一、卷積神經網絡結構
常見的卷積神經網絡結構:
伺服器上:LeNet、AlexNet、VGG、InceptionV1-V4、Inception-ResNet、ResNet
手機上:SqueezNet、NASNet
二、卷積參數量的計算
1、卷積層參數量
需要與上一節中的進行區分卷積核計算參數進行區分
卷積層參數量parameter=(W×H×C+1)*Cout
其中,W為卷積核的寬;H為卷積核的高;+1為偏執量;C為上一層通道數;Cout為下一層通道數
1、全連接配接層參數量
全連接配接層的參數量parameter=(Nin+1)*Nout
其中,Nout輸入的特征向量權重;Nin輸出的特征向量權重;+1為偏執量
三、Lenet網絡模型
Lenet是一個基礎網絡結構,其網絡結構如下:
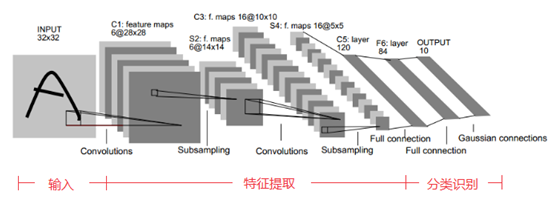
Lenet模型總結:
1、卷積神經網絡使用一個三層的序列組合:卷積、下采樣(池化)、非線性映射(LeNet-5最重要的特性,奠定了目前深層卷積網絡的基礎)
2、使用卷積提取空間特征
3、使用映射的空間均值進行下采樣
4、使用TANH或sigmoid進行非線性映射
5、多層神經網絡MLP作為最終分類器
四、ALexnet網絡模型
ALexnet使用了8層卷積神經網絡,赢得了2012ImageNet挑戰賽,錯誤率為16.4%,在這之前是28.2%,其網絡結構如下:

以第一步操作為例進行講解:
輸入:224*224*3
經過卷積:
卷積:11*11;步長:4;補邊:0
卷積核形狀:48*3*11*11
輸出:2*48*55*55
ALexnet模型小結:
1、AlexNet 跟LeNet結構類似,但使用了更多的卷積層和更大的參數空間來拟合大規模資料集ImageNet.它是淺層神經網絡和深度神經網絡的分界線。雖然看上去AlexNet的實作比LeNet的實作也就多了幾行代碼而已,但這個觀念上的轉變和真正優秀實驗結果的産生令學術界付出了很多年。
2、由五層卷積和三層 全連接配接組成,輸入圖像為三通道224x224大小,網絡規模遠大于LeNet(32×32)
3、所有卷積層都使用ReLU作為非線性映射函數,使模型收斂速度更快
4、在多個GPU上進行模型的訓練,不但可以提高模型的訓練速度,還能提升資料的使用規模
5、使用**随機丢棄技術(dropout)**選擇性地忽略訓練中的單個神經元, 可以作為正則項防止過拟合,提升模型魯棒性,避免模型的過拟合
五、VGG網絡模型
VGGNet由牛津大學提出,是首批把圖像分類的錯誤率降低到10%以内的模型,該網絡采用3×3卷積核的思想是後來許多模型基礎。
VGGNet基本單元都一樣:卷積、池化、全連接配接子產品,常用的是VGG16-3以及VGG19
輸入層:224*224*3
卷積:3*3(全程都這個大小),補邊:1(預設),步長:1(計算得出)
計算公式:N=(W-F+2P)/S+1
計算:(224-3+2*1)/x+1=224
x=1
卷積核尺寸:64*3*3*3
輸出層:224*224*64
池化:2*2,步長:2
輸出層:112*112*64
卷積:3*3(全程都這個大小),補邊:1
計算:(224-3+2*1)+1=224
卷積核尺寸:128*64*3*3
輸出層:112*112*128
..........
..........
..........
其餘過程與上述過程類似
遇到一個max pooling除以2
在VGG16中隻算卷積層,池化層不算,故16層
VGG模型小結
1、整個網絡都使用 了同樣大小的卷積核尺寸3 X3和最大池化尺寸2 X2。
2、1 X1卷積的意義主要在于線性變換,而輸入通道數和輸出通道數不變,沒有發生降維。
3、兩個3 X3的卷積層串聯相當于1個5 X5的卷積層,感受野大小為5 X5。同樣地,3個3 X3的卷積層串聯的效果則相當于1個7 X7的卷積層。這樣的連接配接方式使得網絡參數量更小。而且多層的激活函數令網絡對特征的學習能力更強。
4、VGGNet 在訓練時有一個小技巧,先訓練淺層的的簡單網絡VGGII,再複用VGG11的權重來初始化VGG13,如此反複訓練并初始化VGG19,能夠使訓練時收斂的速度更快。
網絡架構核心思想:用3×3可以代替5×5
對于特征圖5×5大小進行特征提取,變成1×1大小,使用不同卷積核進行對比
在這裡插入圖檔描述](https://img-blog.csdnimg.cn/20210520125413271.png)
| 卷積核大小 | 卷積核參數 |
|---|---|
| 3×3 | 18 |
| 5×5 | 25 |
六、Googlent網絡模型
googlenet作為2014年ILSVRC在分類任務上的冠軍,以6.65的錯誤率%超過VGG等模型,其網絡結構核心部分為inception塊
Vgg在深度做擴充;Googlenet在廣度上做擴充,inception塊模型如下:
具體分析inception塊:
輸入層(任意一步的特征圖):以輸入層為:224*224*3為例
輸入層:224*224*3
第一部分:使用1*1卷積,目标得到輸出層224*224*100
第二部分:使用1*1卷積,目标得到輸出層224*224*10
使用3*3卷積,補邊1,目标得到輸出層224*224*100
第三部分:使用1*1卷積,目标得到輸出層224*224*10
使用5*5卷積,補邊2,目标得到輸出層224*224*100
第四部分:使用3*3池化,目标得到輸出層224*224*3
(池化操作,特征圖層數不變 )
使用1*1卷積,目标得到輸出層224*224*100
最後進行層數拼接得到輸出層:224*224*400
| 各部分 | 輸入層 | 輸出層 | 輸出層 | 參數量總數 |
|---|---|---|---|---|
| 第一部分 | 224×224×3 | ———— | 224×224×100 | 100×3×3×3 |
| 第二部分 | 224×224×3 | 224×224×10 | 224×224×100 | 10×3×1×1+10×100×3×3 |
| 第三部分 | 224×224×3 | 224×224×10 | 224×224×100 | 10×3×1×1+100 ×10×5×5 |
| 第四部分 | 224×224×3 | 224×224×3 | 224×224×100 | 100×3×3×3 |
正常參數應該會變得小,但是224這個參數不好,無法展現,從多個角度觀察,可以縮小參數
Googlenet模型小結
1、采用不同大小的卷 積核意味着不同大小的感受緊,最後拼接意味着不同尺度特征的融合:
2、之是以卷積核 大小采用1.3和5,主要是為了友善對齊。設定卷積步長stride=1之後,隻要分别設定pad=0. 1. 2,那麼卷積之後便可以得到相同次元的特征,然後這些特征就可以直接拼接在一起了:
3、網絡越到後面, 特征越抽象,而且每個特征所涉及的感受野也更大了,是以随着層數的增加,3x3 和5x5卷積的比例也要增加。但是,使用5x5的卷積核仍然會帶來巨大的計算量。為此, 采用1x1卷積核來進行降維。
七、ResNet網絡模型
通俗來講,就是在一個淺層的網絡模型上進行改造,然後将新的模型與原來的淺層模型相比較,這裡有個底線就是,改造後的模型至少不應該比原來的模型表現要差。因為新加的層可以讓它的結果為0,這樣它就等同于原來的模型了。這個假設是ReNet的出發點,核心就是殘差塊。如下圖所示
residual結構(殘差結構)
residual結構描述
輸入層:256*256
左側參數量:3*3*256*256+*3*256*256=1179684
用1×1的卷積核用來降維和升維
右側參數量:1*1*256*64+3*3*64*64+1*1*64*256=69632
ResNet模型小結
1.超深的網絡結構(突破1000層)
2.提出residual子產品
3.使用Batch Normalization加速訓練(丢棄dropout)
4.除了殘差塊,還使用批量歸一化:BN層
八、DenseNet網絡模型
CVPR2017年的Best paper,從特征角度考慮,通過特征重用和旁路設定(Bypass)設定,既大幅度減少網絡的參數量,又在一定程度上緩解了gradient vanishing問題。
DenseNet模型小結
1、相比ResNet擁有更少的參數數量;
2、旁路加強了特征的重用;
3、網絡更易于訓練,并具有一一定的正則效果;
4、緩解了gradient vanishing利model degradation的問題。
九、SENet網絡模型
SENet是Image2017(收官賽)的冠軍模型,全稱為壓縮和激勵網絡
| 年份 | 網絡模型 | 錯誤率 |
|---|---|---|
| 2014 | Google LeNet | 6.67% |
| 2015 | ResNet | 3.57% |
| 2016 | ----- | 2.99% |
| 2017 | SENET | 2.25% |
網絡過程:
(1)進行卷積,變成HWC,
(2)C個通道編變成一個一維通道,11C個數值
(3)對特征圖不同通道指派權重
(1)**Squeeze部分:**即為壓縮部分,原始feature map的次元為HWC,其中H是高度(Height) ,W是寬度(width),C是通道數(channel) 。Squeeze做的事情是把HWC壓縮為11C,相當于把HW壓縮成一維了,實際中般是用Eglobal average pooling實作的。HW壓縮成一維後,相當于這一維參數獲得了之前HW全局的視野,感受區域更廣。
(2) **Excitation部分:**得到Squeeze的11*C的表示後,加入一個FC全連接配接層(Fully Connected),對每個通道的重要性進行預測,得到不同channel的重要性大小後再作用(激勵)到之前的feature map的對應channel上,再進行後續操作。
十、模型的問題及解決方法
1、1×1卷積核的好處
進行一次線性變換,重新組織特征
将特征圖通道數進行升維和降維
2、過拟合與欠拟合
過拟合:根本原因是特征次元過多,模型假設過于複雜,參數過多,訓練資料過少,噪聲過多,導緻拟合的函數完美的預測訓練集,但對新資料的測試集預測結果差。過度的拟合了訓練資料,而沒有考慮到泛化能力。見下圖,為了解決這一問題使用dropout的方式解決。
使用dropout的方式在網絡正向傳播過程中随機失活一部分神經元,dropout随機當機神經元,類似于一個随機森林,在訓練過程中每次當機一些,在梯度回傳的過程中,提高泛化性。
3、深層次網絡的問題
神經網絡疊的越深,學習出的效果一定越好嗎?
人們發現當模型層數到達某種程度,模型效果将會不升反降,也就是說模型發生退化(degradation)情況
下圖左側為訓練誤差,右側為測試誤差,20層的誤差低于56層
網絡繼續加深————産生退化————梯度消失、爆炸
參考博文:
https://blog.csdn.net/daydayup_668819/article/details/79932548