文章目錄
- 1. 前言
- 2. Prometheus與Kubernetes完美結合
- 2.1 Kubernetes Operator
- 2.3 Prometheus Operator
- 3. 在Kubernetes上部署Prometheus的傳統方式
- 3.1 Kubernetes部署Prometheus
- 3.1.1 建立命名空間monitoring
- 3.1.2 建立RBAC規則
- 3.1.3 建立ConfigMap類型的Prometheus配置檔案
- 3.1.4 建立ConfigMap類型的prometheus rules配置檔案
- 3.1.5 建立prometheus svc
- 3.1.6 deployment方式建立prometheus執行個體
- 3.1.7 建立prometheus ingress實作外部域名通路
- 3.1.8 測試登入prometheus
- 3.2 Kubernetes部署kube-state-metrics
- 3.2.1 建立RBAC
- 3.2.2 建立kube-state-metrics Service
- 3.2.3 建立kube-state-metrics的deployment
- 3.2.4 prometheus配置kube-state-metrics 的target
- 3.3 Kubernetes部署node-exporter
- 3.3.1 部署node-exporter service
- 3.3.2 daemonset方式建立node-exporter容器
- 3.3.3 prometheus配置node-exporter的target
- 3.4 Kubernetes部署Grafana
- 3.4.1 建立Grafana Service
- 3.4.2 deployment方式部署Grafana
- 3.4.3 建立grafana ingress實作外部域名通路
- 3.4.4 測試登入grafana
參考連結:
- https://dbaplus.cn/news-134-3247-1.html
- https://github.com/aiopstack/Prometheus-book
- kubernetes ingress-nginx通過外網通路您的應用
- https://github.com/kubernetes/kube-state-metrics
- https://github.com/kubernetes/ingress-nginx
- https://cloud.tencent.com/developer/article/1536967
1. 前言
本文首先從Prometheus是如何監控Kubernetes入手,介紹Prometheus Operator元件。接着詳細介紹基于Kubernetes的兩種Prometheus部署方式,最後介紹服務配置、監控對象以及資料展示和告警。通過本文,大家可以在Kubernetes叢集的基礎上學習和搭建完善的Prometheus監控系統。
2. Prometheus與Kubernetes完美結合
2.1 Kubernetes Operator
在Kubernetes的支援下,管理和伸縮Web應用、移動應用後端以及API服務都變得比較簡單了。因為這些應用一般都是無狀态的,是以Deployment這樣的基礎Kubernetes API對象就可以在無需附加操作的情況下,對應用進行伸縮和故障恢複了。
而對于資料庫、緩存或者監控系統等有狀态應用的管理,就是挑戰了。這些系統需要掌握應用領域的知識,正确地進行伸縮和更新,當資料丢失或不可用的時候,要進行有效的重新配置。我們希望這些應用相關的運維技能可以編碼到軟體之中,進而借助Kubernetes 的能力,正确地運作和管理複雜應用。
Operator
這種軟體,使用TPR(第三方資源,現在已經更新為CRD)機制對Kubernetes API進行擴充,将特定應用的知識融入其中,讓使用者可以建立、配置和管理應用。與Kubernetes的内置資源一樣,Operator操作的不是一個單執行個體應用,而是叢集範圍内的多執行個體。
2.3 Prometheus Operator
Kubernetes的
Prometheus Operator
為Kubernetes服務和Prometheus執行個體的部署和管理提供了簡單的監控定義。
安裝完畢後,Prometheus Operator提供了以下功能:
- 建立/毀壞。在Kubernetes namespace中更容易啟動一個Prometheus執行個體,一個特定的應用程式或團隊更容易使用的Operato。
- 簡單配置。配Prometheus的基礎東西,比如在Kubernetes的本地資源
versions
persistence
retention policies
replicas
- Target Services通過标簽。基于常見的Kubernetes label查詢,自動生成監控target配置;不需要學習Prometheus特定的配置語言。
Prometheus Operator架構如圖1所示。
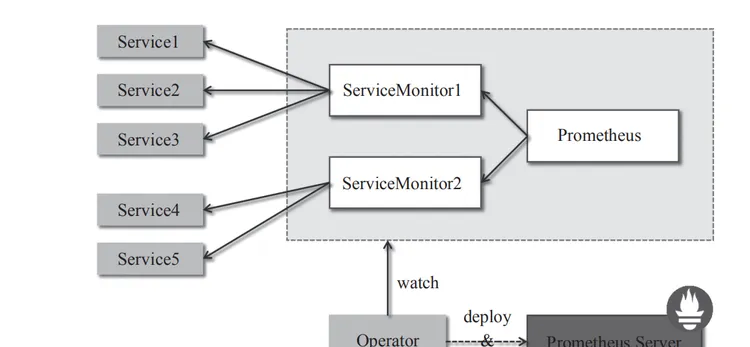
架構中的各組成部分以不同的資源方式運作在Kubernetes叢集中,它們各自有不同的作用。
-
Operator
Custom Resource Definition,CRD
Prometheus Server
-
Prometheus
-
Prometheus Server
Prometheus Server
-
ServiceMonitor
-
Service
Node Exporter Service
Mysql Exporter Service
-
Alertmanager
3. 在Kubernetes上部署Prometheus的傳統方式
本節詳細介紹Kubernetes通過YAML檔案方式部署Prometheus的過程,即按順序部署了
Prometheus
、
kube-state-metrics
、
node-exporter
以及
Grafana
。圖2展示了各個元件的調用關系。

在Kubernetes Node上部署
Node exporter
,擷取該節點實體機或者虛拟機的監控資訊,在Kubernetes Master上部署
kube-state-metrics
擷取Kubernetes叢集的狀态。所有資訊彙聚到Prometheus進行處理和存儲,然後通過Grafana進行展示。
下載下傳媒體,也可以不用下載下傳,直接對文章的yaml複制黏貼,當然無論怎麼樣都需要根據自己的環境修改恰當的配置參數。
git clone https://github.com/aiopstack/Prometheus-book
cd Prometheus-book-master/scripts-config/Chapter11/
ls -l
ls -l
total 64
-rw-r--r-- 1 root root 1756 Jan 17 23:52 grafana-deploy.yaml
-rw-r--r-- 1 root root 261 Jan 17 23:52 grafana-ingress.yaml
-rw-r--r-- 1 root root 207 Jan 17 23:52 grafana-service.yaml
-rw-r--r-- 1 root root 444 Jan 17 23:52 kube-state-metrics-deploy.yaml
-rw-r--r-- 1 root root 1087 Jan 17 23:52 kube-state-metrics-rbac.yaml
-rw-r--r-- 1 root root 293 Jan 17 23:52 kube-state-metrics-service.yaml
-rw-r--r-- 1 root root 1728 Jan 17 23:52 node_exporter-daemonset.yaml
-rw-r--r-- 1 root root 390 Jan 17 23:52 node_exporter-service.yaml
-rw-r--r-- 1 root root 65 Jan 17 23:52 ns-monitoring.yaml
-rw-r--r-- 1 root root 5052 Jan 17 23:52 prometheus-core-cm.yaml
-rw-r--r-- 1 root root 1651 Jan 18 01:59 prometheus-deploy.yaml
-rw-r--r-- 1 root root 269 Jan 17 23:52 prometheus_Ingress.yaml
-rw-r--r-- 1 root root 679 Jan 17 23:52 prometheus-rbac.yaml
-rw-r--r-- 1 root root 2429 Jan 17 23:52 prometheus-rules-cm.yaml
-rw-r--r-- 1 root root 325 Jan 17 23:52 prometheus-service.yaml 3.1 Kubernetes部署Prometheus
部署對外可通路Prometheus:
- 首先需要建立Prometheus所在命名空間,
- 然後建立Prometheus使用的RBAC規則,
- 建立Prometheus的configmap來儲存配置檔案,
- 建立service進行固定叢集IP通路,
- 建立deployment部署帶有Prometheus容器的pod,
- 最後建立ingress實作外部域名通路Prometheus。
部署順序如圖3所示。
3.1.1 建立命名空間monitoring
相關對象都部署到該命名空間,使用以下指令建立命名空間:
$ kubectl create namespace monitoring 或者
$ kubectl create -f ns-monitoring.yaml 代碼如下
apiVersion: v1
kind: Namespace
metadata:
name: monitoring 可以看到該YAML檔案使用的apiVersion版本是v1,kind是Namespace,命名空間的名字是monitoring。
使用以下指令确認名為monitoring的ns已經建立成功:
$ kubectl get ns monitoring
NAME STATUS AGE
monitoring Active 1d 3.1.2 建立RBAC規則
建立RBAC規則,包含
ServiceAccount
、
ClusterRole
、
ClusterRoleBinding
三類YAML檔案。Service Account 是面向命名空間的,ClusterRole、ClusterRoleBinding是面向整個叢集所有命名空間的,可以看到ClusterRole、ClusterRoleBinding對象并沒有指定任何命名空間。ServiceAccount中可以看到,名字是prometheus-k8s,在monitoring命名空間下。ClusterRole一條規則由apiGroups、resources、verbs共同組成。ClusterRoleBinding中subjects是通路API的主體,subjects包含users、groups、service accounts三種類型,我們使用的是ServiceAccount類型,使用以下指令建立RBAC:
kubectl create -f prometheus-rbac.yaml rometheus-rbac.yaml檔案内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus-k8s
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources: ["nodes", "services", "endpoints", "pods"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: prometheus-k8s 使用以下指令确認RBAC是否建立成功:
$ kubectl get sa prometheus-k8s -n monitoring
NAME SECRETS AGE
prometheus-k8s 1 2m17s
$ kubectl get clusterrole prometheus
NAME CREATED AT
prometheus 2021-01-18T07:42:36Z
$ kubectl get clusterrolebinding prometheus
NAME ROLE AGE
prometheus ClusterRole/cluster-admin 2m24s 3.1.3 建立ConfigMap類型的Prometheus配置檔案
使用ConfigMap方式建立Prometheus配置檔案,YAML檔案中使用的類型是ConfigMap,命名空間為monitoring,名稱為
prometheus-core
,apiVersion是v1,data資料中包含
prometheus.yaml
檔案,内容是prometheus.yaml: |這行下面的内容。使用以下指令建立Prometheus的配置檔案:
$ kubectl create -f prometheus-core-cm.yaml prometheus-core-cm.yaml檔案内容如下:
kind: ConfigMap
metadata:
creationTimestamp: null
name: prometheus-core
namespace: monitoring
apiVersion: v1
data:
prometheus.yaml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets: ["$alertmanagerIP:9093"]
rule_files:
- "/etc/prometheus-rules/*.yml"
scrape_configs:
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-nodes'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: $kube-apiserverIP:6443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
- job_name: 'kubernetes-cadvisor'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: 36.111.140.20:6443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: 'kubernetes-services'
metrics_path: /probe
params:
module: [http_2xx]
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.example.com:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name 使用以下指令檢視已建立的配置檔案prometheus-core:
$ kubectl get cm prometheus-core -n monitoring
NAME DATA AGE
prometheus-core 1 44s 3.1.4 建立ConfigMap類型的prometheus rules配置檔案
建立prometheus rules配置檔案,使用ConfigMap方式建立prometheus rules配置檔案,包含的内容是兩個檔案,分别是
node-up.yml
和
cpu-usage.yml
。使用以下指令建立Prometheus的另外兩個配置檔案:
$ kubectl create -f prometheus-rules-cm.yaml
prometheus-rules-cm.yaml
檔案内容如下:
kind: ConfigMap
apiVersion: v1
metadata:
name: prometheus-rules
namespace: monitoring
data:
node-up.yml: |
groups:
- name: server_rules
rules:
- alert: 機器當機
expr: up{component="node-exporter"} != 1
for: 1m
labels:
severity: "warning"
instance: "{{ $labels.instance }}"
annotations:
summary: "機器 {{ $labels.instance }} 處于down的狀态"
description: "{{ $labels.instance }} of job {{ $labels.job }} 已經處于down狀态超過1分鐘,請及時處理"
cpu-usage.yml: |
groups:
- name: cpu_rules
rules:
- alert: cpu 剩餘量過低
expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85
for: 1m
labels:
severity: "warning"
instance: "{{ $labels.instance }}"
annotations:
summary: "機器 {{ $labels.instance }} cpu 已用超過設定值"
description: "{{ $labels.instance }} CPU 用量已超過 85% (current value is: {{ $value }}),請及時處理"
low-disk-space.yml: |
groups:
- name: disk_rules
rules:
- alert: disk 剩餘量過低
expr: 1 - node_filesystem_free_bytes{fstype!~"rootfs|selinuxfs|autofs|rpc_pipefs|tmpfs|udev|none|devpts|sysfs|debugfs|fuse.*",device=~"/dev/.*"} /
node_filesystem_size_bytes{fstype!~"rootfs|selinuxfs|autofs|rpc_pipefs|tmpfs|udev|none|devpts|sysfs|debugfs|fuse.*",device=~"/dev/.*"} > 0.85
for: 1m
labels:
severity: "warning"
instance: "{{ $labels.instance }}"
annotations:
summary: "{{$labels.instance}}: 磁盤剩餘量低于設定值"
description: "{{$labels.instance}}: 磁盤用量超過 85% (current value is: {{ $value }}),請及時處理"
mem-usage.yml: |
groups:
- name: memory_rules
rules:
- alert: memory 剩餘量過低
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 85
for: 1m
labels:
severity: "warning"
instance: "{{ $labels.instance }}"
annotations:
summary: "{{$labels.instance}}: 記憶體剩餘量過低"
description: "{{$labels.instance}}: 記憶體使用量超過 85% (current value is: {{ $value }} ,請及時處理" 使用以下指令檢視已下發的配置檔案
prometheus-rules
:
$ kubectl get cm -n monitoring prometheus-rules
NAME DATA AGE
prometheus-rules 4 2s 3.1.5 建立prometheus svc
會生成一個
CLUSTER-IP
進行叢集内部的通路,CLUSTER-IP也可以自己指定。使用以下指令建立Prometheus要用的service:
$ kubectl create -f prometheus-service.yaml prometheus-service.yaml檔案内容如下:
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitoring
labels:
app: prometheus
component: core
annotations:
prometheus.io/scrape: 'true'
spec:
ports:
- port: 9090
targetPort: 9090
protocol: TCP
name: webui
selector:
app: prometheus
component: core 檢視已建立的名為prometheus的service:
$ kubectl get svc prometheus -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus ClusterIP 10.98.66.13 9090/TCP 11s 3.1.6 deployment方式建立prometheus執行個體
可以根據自己的環境需求選擇部署節點,我計劃部署在node1
$ kubectl label node node1 app=prometheus
$ kubectl label node node1 component=core
$ kubectl create -f prometheus-deploy.yaml prometheus-deploy.yaml檔案内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-core
namespace: monitoring
labels:
app: prometheus
component: core
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: core
template:
metadata:
name: prometheus-main
labels:
app: prometheus
component: core
spec:
serviceAccountName: prometheus-k8s
# nodeSelector:
# kubernetes.io/hostname: 192.168.211.40
containers:
- name: prometheus
image: zqdlove/prometheus:v2.0.0
args:
- '--storage.tsdb.retention=15d'
- '--config.file=/etc/prometheus/prometheus.yaml'
- '--storage.tsdb.path=/home/prometheus_data'
- '--web.enable-lifecycle'
ports:
- name: webui
containerPort: 9090
resources:
requests:
cpu: 1000m
memory: 1000M
limits:
cpu: 1000m
memory: 1000M
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /home/prometheus_data
- name: config-volume
mountPath: /etc/prometheus
- name: rules-volume
mountPath: /etc/prometheus-rules
- name: time
mountPath: /etc/localtime
volumes:
- name: data
hostPath:
path: /home/cdnadmin/prometheus_data
- name: config-volume
configMap:
name: prometheus-core
- name: rules-volume
configMap:
name: prometheus-rules
- name: time
hostPath:
path: /etc/localtime 使用以下指令檢視已建立的名字為prometheus-core的deployment的狀态:
$ kubectl get deployments.apps -n monitoring
NAME READY UP-TO-DATE AVAILABLE AGE
prometheus-core 1/1 1 1 75s
$ kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
prometheus-core-6544fbc888-m58hf 1/1 Running 0 78s 傳回資訊表示部署期望的pod有1個,目前有1個,更新到最新狀态的有1個,可用的有1個,pod目前的年齡是1天。
3.1.7 建立prometheus ingress實作外部域名通路
使用以下指令建立Ingress:
$ kubectl create -f prometheus_Ingress.yaml prometheus_Ingress.yaml檔案内容如下:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: traefik-prometheus
namespace: monitoring
spec:
rules:
- host: prometheus.test.com
http:
paths:
- path: /
backend:
serviceName: prometheus
servicePort: 9090 将prometheus.test.com域名解析到Ingress伺服器,此時可以通過prometheus.test.com通路Prometheus的監控資料的界面了。
使用以下指令檢視已建立Ingress的狀态:
$ kubectl get ing traefik-prometheus -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
traefik-prometheus prometheus.test.com 80 52s 3.1.8 測試登入prometheus
将
prometheus.test.com
解析到Ingress伺服器,此時可以通過
grafana.test.com
通路Grafana的監控展示的界面。
linux檔案/etc/hosts添加:
#任意node_ip
192.168.211.41 prometheus.test.com 執行:
30304
是nginx-ingress的統一對外開方端口,
$ curl prometheus.test.com:30304
href="/graph">Found. windows添加
C:\Windows\System32\drivers\etc\hosts
192.168.211.41 prometheus.test.com 3.2 Kubernetes部署kube-state-metrics
kube-state-metrics
使用名為monitoring的命名空間,在上節已建立,不需要再次建立。創
3.2.1 建立RBAC
包含
ServiceAccount
、
ClusterRole
、
ClusterRoleBinding
三類YAML檔案,本節RBAC内容結構和上節中内容類似。使用以下指令建立kube-state-metrics RBAC:
$ kubectl create -f kube-state-metrics-rbac.yaml
kube-state-metrics-rbac.yaml
檔案内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources: ["nodes","pods","services","resourcequotas","replicationcontrollers","limitranges"]
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources: ["daemonsets","deployments","replicasets"]
verbs: ["list", "watch"]
- apiGroups: ["batch/v1"]
resources: ["job"]
verbs: ["list", "watch"]
- apiGroups: ["v1"]
resources: ["persistentvolumeclaim"]
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulset"]
verbs: ["list", "watch"]
- apiGroups: ["batch/v2alpha1"]
resources: ["cronjob"]
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
# name: cluster-admin
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: monitoring 使用以下指令确認RBAC是否建立成功,指令分别擷取已建立的ServiceAccount、ClusterRole、ClusterRoleBinding:
$ kubectl get sa kube-state-metrics -n monitoring
NAME SECRETS AGE
kube-state-metrics 1 20s
$ kubectl get clusterrole kube-state-metrics
NAME CREATED AT
kube-state-metrics 2021-01-19T08:44:39Z
$ kubectl get clusterrolebinding kube-state-metrics
NAME ROLE AGE
kube-state-metrics ClusterRole/kube-state-metrics 32s 3.2.2 建立kube-state-metrics Service
kubectl create -f kube-state-metrics-service.yaml
kube-state-metrics-service.yaml
檔案内容如下:
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
name: kube-state-metrics
namespace: monitoring
labels:
app: kube-state-metrics
spec:
ports:
- name: kube-state-metrics
port: 8080
protocol: TCP
selector:
app: kube-state-metrics 使用以下指令檢視名為kube-state-metrics的Service:
$ kubectl get svc kube-state-metrics -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-state-metrics ClusterIP 10.101.0.15 8080/TCP 41s 3.2.3 建立kube-state-metrics的deployment
用來部署kube-state-metrics 容器:
可以根據自己的環境需求選擇部署節點,我計劃部署在node2
$ kubectl label node node2 app=kube-state-metrics
$ kubectl create -f kube-state-metrics-deploy.yaml
kube-state-metrics-deploy.yaml
檔案内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
nodeSelector:
type: k8smaster
containers:
- name: kube-state-metrics
image: zqdlove/kube-state-metrics:v1.0.1
ports:
- containerPort: 8080 使用以下指令檢視monitoring命名空間下名為kube-state-metrics的deployment的狀态資訊:
kubectl get deployment kube-state-metrics -n monitoring
NAME READY UP-TO-DATE AVAILABLE AGE
kube-state-metrics 1/1 1 1 8m9s 3.2.4 prometheus配置kube-state-metrics 的target
3.3 Kubernetes部署node-exporter
在Prometheus中負責資料彙報的程式統一稱為Exporter,而不同的Exporter負責不同的業務。它們具有統一命名格式,即xx_exporter,例如,負責主機資訊收集的node_exporter。本節為安裝node_exporter的教程。node_exporter主要用于*NIX系統監控,用Golang編寫。
node-exporter使用名為monitoring的命名空間,上節已建立。
3.3.1 部署node-exporter service
$ kubectl create -f node_exporter-service.yaml
node_exporter-service.yaml
檔案内容如下:
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
name: prometheus-node-exporter
namespace: monitoring
labels:
app: prometheus
component: node-exporter
spec:
clusterIP: None
ports:
- name: prometheus-node-exporter
port: 9100
protocol: TCP
selector:
app: prometheus
component: node-exporter
type: ClusterIP 使用以下指令檢視monitoring命名空間下名為prometheus-node-exporter的service:
$ kubectl get svc prometheus-node-exporter -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-node-exporter ClusterIP None 9100/TCP 20s 3.3.2 daemonset方式建立node-exporter容器
$ kubectl label node --all node-exporter=node-exporter
$ kubectl create -f node_exporter-daemonset.yaml 檢視monitoring指令空間下名為prometheus-node-exporter的daemonset的狀态,指令如下:
$ kubectl get ds prometheus-node-exporter -n monitoring
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
prometheus-node-exporter 2 2 2 2 2
node_exporter-daemonset.yaml
檔案詳細内容如下:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: prometheus-node-exporter
namespace: monitoring
labels:
# app: prometheus
# component: node-exporter
node-exporter: node-exporter
spec:
selector:
matchLabels:
# app: prometheus
node-exporter: node-exporter
#component: node-exporter
template:
metadata:
name: prometheus-node-exporter
labels:
node-exporter: node-exporter
#app: prometheus
#component: node-exporter
spec:
nodeSelector:
node-exporter: node-exporter
containers:
- image: zqdlove/node-exporter:v0.16.0
name: prometheus-node-exporter
ports:
- name: prom-node-exp
#^ must be an IANA_SVC_NAME (at most 15 characters, ..)
containerPort: 9100
# hostPort: 9100
resources:
requests:
# cpu: 20000m
cpu: "0.6"
memory: 100M
limits:
cpu: "0.6"
#cpu: 20000m
memory: 100M
securityContext:
privileged: true
command:
- /bin/node_exporter
- --path.procfs
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- ^/(sys|proc|dev|host|etc)($|/)
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: root
mountPath: /rootfs
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: dev
hostPath:
path: /dev
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
- name: root
hostPath:
path: /
# affinity:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: kubernetes.io/hostname
# operator: NotIn
# values:
# - $YOUR_IP
#
hostNetwork: true
hostIPC: true
hostPID: true
node_exporter-daemonset.yaml
檔案說明:
- hostPID:true
- hostIPC:true
- hostNetwork:true 這三個配置主要用于主機的
PID namespace
、
IPC namespace
以及主機網絡
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule" $ kubectl describe nodes |grep Taint
Taints: node-role.kubernetes.io/master:NoSchedule
Taints:
Taints: 檢視有污點的節點為master,如果想把daemonset pod部署到master,需要容忍這個節點的污點,也可以稱之為過濾。
3.3.3 prometheus配置node-exporter的target
3.4 Kubernetes部署Grafana
Grafana使用名為monitoring的命名空間,前面小節已經建立,不需要再次建立.
3.4.1 建立Grafana Service
$ kubectl create -f grafana-service.yaml
grafana-service.yaml
檔案内容如下:
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitoring
labels:
app: grafana
component: core
spec:
ports:
- port: 3000
selector:
app: grafana
component: core 使用以下指令檢視monitoring指令空間下名為grafana的service的資訊:
$ kubectl get svc grafana -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana ClusterIP 10.109.232.15 3000/TCP 18s 3.4.2 deployment方式部署Grafana
根據自己需求選擇部署的節點,我計劃在node2
$ kubectl label node node2 grafana=grafana
#要預先配置好grafana的配置檔案 node2執行
$ docker run -tid zqdlove/grafana:v5.0.0 --name grafana-tmp bash
$ docker cp practical_morse:/et/grafana/grafana.ini /etc/grafana/
$ docker kill grafana-tmp
$ docker rm grafana-tmp
$ useradd grafana
$ chown grafana:grafana /etc/grafana/grafana.ini
$ chmod 777 /etc/grafana/grafana.ini master執行
$ kubectl create -f grafana-deploy.yaml
grafana-deploy.yaml
檔案内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana-core
namespace: monitoring
labels:
app: grafana
component: core
spec:
replicas: 1
selector:
matchLabels:
app: grafana
component: core
template:
metadata:
labels:
app: grafana
component: core
spec:
nodeSelector:
#kubernetes.io/hostname: 192.168.211.42
grafana: grafana
containers:
- image: zqdlove/grafana:v5.0.0
name: grafana-core
imagePullPolicy: IfNotPresent
#securityContext:
# privileged: true
# env:
resources:
# keep request = limit to keep this container in guaranteed class
limits:
cpu: 500m
memory: 1200Mi
requests:
cpu: 500m
memory: 1200Mi
env:
# The following env variables set up basic auth twith the default admin user and admin password.
- name: GF_AUTH_BASIC_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "false"
# - name: GF_AUTH_ANONYMOUS_ORG_ROLE
# value: Admin
# does not really work, because of template variables in exported dashboards:
# - name: GF_DASHBOARDS_JSON_ENABLED
# value: "true"
readinessProbe:
httpGet:
path: /login
port: 3000
# initialDelaySeconds: 30
# timeoutSeconds: 1
volumeMounts:
- name: grafana-persistent-storage
mountPath: /var
- name: grafana
mountPath: /etc/grafana
imagePullSecrets:
- name: bjregistry
volumes:
- name: grafana-persistent-storage
emptyDir: {}
- name: grafana
hostPath:
path: /etc/grafana 檢視monitoring指令空間下名為grafana-core的deployment的狀态,資訊如下:
$ kubectl get deployment grafana-core -n monitoring
NAME READY UP-TO-DATE AVAILABLE AGE
grafana-core 1/1 1 1 8m32s 3.4.3 建立grafana ingress實作外部域名通路
$ kubectl create -f grafana-ingress.yaml grafana-ingress.yaml檔案内容如下:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: traefik-grafana
namespace: monitoring
spec:
rules:
- host: grafana.test.com
http:
paths:
- path: /
backend:
serviceName: grafana
servicePort: 3000 檢視monitoring命名空間下名為traefik-grafana的Ingress,使用以下指令:
$ kubectl get ingress traefik-grafana -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
traefik-grafana grafana.test.com 80 30s 3.4.4 測試登入grafana
将
grafana.test.com
解析到Ingress伺服器,此時可以通過grafana.test.com通路Grafana的監控展示的界面。
linux檔案/etc/hosts添加:
192.168.211.41 grafana.test.com 執行:
30304
是nginx-ingress的統一對外開方端口
$ curl grafana.test.com:30304
href="/login">Found. windows添加
C:\Windows\System32\drivers\etc\hosts
192.168.211.41 grafana.test.com