作者 | 丁效
整理 | 維克多
在過去十年的人工智能浪潮中,以深度學習為代表的人工智能技術已基本實作了視覺、聽覺等感覺智能,但依然無法很好地做到思考、推理等認知智能。
4月9日,哈爾濱工業大學計算學部副研究員丁效,在AI TIME青年科學家——AI 2000學者專場論壇上,做了《基于神經符号的認知推理方法》的報告,分享了神經網絡方法執行符号推理任務的最新進展,同時也給出了将符号知識注入神經網絡的思路以及如何将神經網絡與符号系統相融合。
以下是演講原文,AI科技評論做了不改變原意的整理。
今天和大家分享神經符号認知推理方面的研究工作。人工智能(AI)已經曆了第一代符号智能,第二代感覺智能以及目前的認知智能。認知智能是一種融合的狀态,強調表示學習與複雜知識推理的有機結合是人工智能進步的階梯。
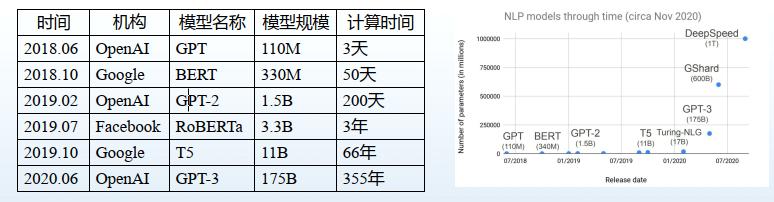
實際上,在自然語言處理(NLP)領域,預訓練模型規模以每年約10倍的速度增長, 模型的通用智能水準顯著增強。如上圖,無論是計算的複雜度、參數以及訓練時間,随着時間的推移,都有跨越性的發展,也促使模型性能大幅度提升。
同時,預訓練語言模型還有很大的發展空間。例如詢問GPT-3:烤箱和鉛筆哪個更重?腳有幾隻眼睛?等問題,它的回答的結果差強人意。根本原因是缺少對知識的推理的能力,以及對推理結果的可解釋性。

如何解決?我認為需要開發新的計算範式,即将基于感覺的深度學習和基于認知的符号計算,進行融合。
傳統基于符号的表示,例如在NLP領域,對于句子的處理是分詞,文本中有1萬個詞就對應1萬維。
現在分布式的表示方法是基于神經網絡,需要學習出每個詞的向量,此向量次元不高,也不會那麼稀疏,它是低維稠密的實數值向量,很容易捕獲文本的語義資訊。
利用符号系統和利用上下文表示的系統有什麼差別?首先對于詞彙的了解,一定離不開上下文的語義的了解。例如:小明離開星巴克和喬布斯離開蘋果公司,同樣是離開一詞,前者可能表示消費完了,離開某個商店,後者可能表示辭職。是以,兩種語義是截然不同的。
傳統的NLP任務從語料中提取特征,利用統計關系學習模組化語義結構,屬于符号系統處理方法。給定若幹個任務,例如共旨消解、語義角色标注、依存分析或者NER等等任務,傳統方法是手工提取一些特征,然後把特征輸入到一些統計模型當中,然後得出分類結果、預測結果。
傳統的 NLP的處理方式,提取特征可以認為是符号系統,即手工提取的特征本身就可以用來解釋最後的預測結果,這是典型的可解釋的方式。
基于神經網絡的分布式的語義表示,在處理各種NLP任務時,“省略”了特征提取步驟,有幾個特點:1. 單詞用稠密的低維向量表示;2.上下文語義表示是單詞語義表示的組合;3.表示向量與組合方式需要在大量的資料上進行訓練;4.能夠得到詞的任務特異表示。
雖然運用神經網絡能夠得到遠超以前的性能,但也有“需要大量訓練資料”、“可解釋性差”、“推理基于表面特征”等缺點。
神經方法和符号方法各有哪些優缺點?符号AI對于規則、知識,能夠可程式化,可以用程式設計的方式直接把規則編寫到程式當中,然後可以進行精确、嚴格的比對、推理,得到的結果也是符合規則的,是以解釋性強。缺點是構造成本太高,覆寫率低,穩定性也不太夠。
神經方法的優點是表示能力非常強,任務的适應性很強,無論生成任務,還是分類任務,亦或回歸任務都能“拿下”。缺點是學習最簡單的模式,距離人的智慧還有很大的距離,以及一直被诟病的黑盒、不可解釋性等等。
顯然,如果有方法将神經與符号相融合就能優勢互補。目前,有三種方法可供參考:
1.神經網絡方法執行符号推理任務,神經網絡在此過程當中可能幫助我們把詞進行泛化。
2. 符号知識注入神經網絡。進行損失函數設計,或者進行一些正則化的限制,或者進行資料增廣等操作。
3. 神經網絡與符号系統相融合。即不以符号為主,也不以神經為主,而是進行有機融合。
在NLP處理領域,如果想獲得以“類人”方式學習和思考的機器,需要在語義合成、推理、常識學習,學會學習等四個方面努力。NLP中的推理是指文本推理能夠推動另外三個任務不斷的進步。
文本推理是指給定文本形式的前提(Premise)與前提相關的某一假設(Hypothesis),模組化文本語義與文本結構,以判斷前提與假設之間的關系。具體的例子如下圖所示:
文本推理有三個典型的任務,文本蘊含、因果推理以及故事結尾預測。結合認知的文本推理,其實來源于認知科學當中的雙過程的理論。
雙過程理論是指人的思考和學習是有兩個系統:直覺系統和邏輯系統。直覺系統幫助我們進行一些直覺的無思決策,快速回答問題;邏輯系統要調用大腦當中存儲的知識進行邏輯的推理。
下面介紹實作剛才提到的三種不同認知推理任務的方法。
1
神經網絡方法執行符号推理任務
符号推理的任務有很多,自動定理證明、多項選擇問答、邏輯規則歸納。由于時間有限,主要介紹多項選擇問答任務。
在去年的EMNLP 2021一篇論文中,我們采用自然邏輯,幫助完成多項式選擇的問答任務。
自然邏輯是一種語義單調性的邏輯系統,它主要是定義了7種單詞之間的語義關系,包括等價、前向蘊含、反向蘊含、前向蘊含、反義、并列、覆寫、獨立等等。然後我們要在遵循自然邏輯的前提下,在文本上進行推理,例如把句子進行增删改操作,然後保持語義的不變性,進行替換。
例如:
給定句子:所有的動物需要水
自然邏輯:動物 (反向蘊含) 狗
替換操作後:所有的動物需要水 所有的狗需要水
推理中的換詞對NLP中的多項選擇問答任務非常有必要。例如上圖中的任務形式:給定問題:齧齒動物吃植物?知識庫當中有一條知識是:松鼠吃松子。
第一步需要進行單詞的替換,将齧齒動物替換成倉鼠,然後把植物替換成果實,或者把植物可以替換成莊稼。
接下來不斷替換,把植物替換成谷物,把果實替換成堅果,把齧齒動物替換成田鼠,經過一步一步的的替換,最終替換到了知識庫當中的某一條知識。是以,基于自然邏輯進行多項選擇問答這條路徑就是可解釋的。其實,不僅是可以替換,也可以增加詞、删除詞、修改詞。
問題在于是基于語義詞典進行詞的替換,而語義詞典是非常有限的。再者沒有考慮上下文的語義關系。
引入神經網絡的方法,可以将詞的替換直接進行神經化。具體過程可以分為4步:
1. 利用預訓練語言模型生成候選單詞
2. 判斷原單詞和候選單詞之間的語義關系
3. 根據上下文的單調性将詞級别的語義關系映射到句子級别
4. 保留滿足恒等和反向蘊含關系的候選句
2
符号知識注入神經網絡
符号知識注入神經網絡的方式有很多,可以利用邏輯規則限制神經網絡的模型;可以利用基于邏輯規則進行資料增強的任務。
例如資料增強,給定三元組 B的首都是A(A,首都,B),可以擴充出A位于B。具體一些,知識庫總已經有: (北京,首都,中國),則基于該規則可以補充額外的三元組(北京,位于,中國)。
如何利用邏輯規則,限制神經模型?上圖是事件時間常識知識預測任務,其中預測為對應的時間單元:給定事件起床,推測頻率、持續時間以及典型發生時間。
這些事件的常識知識有什麼用?可以把事件的常識知識注入到預訓練語言模型當中,讓模型對事件時間的常識知識能夠掌握,會讓模型在進行時間相關的推理的工作中更加高效。
存在的問題在于,從文本中無監督抽取的時間常識可能存在報告偏差(Reporting Bias)。例如常見的情況的在文本中并未顯式提及:自然文本中幾乎不會有“睡醒之後,我一般要花幾分鐘的時間起床”等類似的表達! 在文本表達中會對非尋常現象加以強調:我每天都得花一個小時才能起床!。
如何解決?利用不同次元間的時間常識知識之間的限制關系,減緩報告誤差。對于“我是在媽媽準備早餐期間起床的”,利用事件間時序關系可以得出:起床的持續時間短于準備早餐 ;“自己在家準備早餐,十分鐘就可以搞定” 可以得出:準備早餐的持續時間大概約為10分鐘。
下表詳細總結了類似于上述所有的可能的互補關系:
此規則怎樣利用?我們設計了基于軟邏輯規則的時間的常識預測。給定輸入:我是在媽媽準備早餐期間起床的,得到原子式:,然後将原子式概括成機率軟邏輯規則,如下圖。
将機率軟邏輯規則放到神經網絡模型當中,将其制作成損失函數。這一步是在交叉熵損失函數的基礎上,添加了機率軟邏輯的限制損失,使得模型在做的時間推理的過程當中,既考慮機率軟邏輯的規則,同時考慮對于語義了解之後的的推理結果。
3
融合神經與符号的推理系統
融合神經和符号的推理系統,在進行數值運算,因果邏輯推理,一階謂詞邏輯規則等方面具有優勢。它可以利用神經網絡子產品,顯式模組化符号規則。
傳統的因果推理模型多數以黑盒方式,直接從标注的因果事件對中學習因果知識。是以可能利用部分與标簽存在相關關系的統計特征做出判斷,緻推理結果的不穩定,不可靠,不可解釋。
如何還原背後的因果決策機制?我們提出引入中間證據事件,還原背後的因果邏輯鍊條。這種因果邏輯鍊條提供了更強的可解釋性。在ACL 2021上,我們的工作ExCAR: 事理圖譜知識增強的因果推理架構,能夠從預先建構的事理圖譜中擷取中間證據事件。
具體而言是使用條件馬爾可夫神經邏輯網絡(CMNLN),其中邏輯網絡具有較強的可解釋性與可靠性。神經邏輯網絡是指利用神經網絡表示規則,并賦予每個因果規則以權重(因果強度),以應對規則集合中可能存在的噪音與統計關系的複雜性。條件馬爾可夫還能支援因果疊加效應,即對于同一規則,不同的前件可能對因果強度帶來不同的影響。基本邏輯是:證據事件邏輯規則因果邏輯圖。
4
機器學習:人與機器之間的資訊互動
下面從人機互動的角度,思考機器學習。目前的機器學習過程:極度依賴靜态的标注資料集。例如标簽蘊含的資訊有限,這導緻學習效率低下、對于複雜任務,标注尤為昂貴、資料過時導緻模型無法使用。
機器向人的學習遠遠不隻是說去學标注的資料,可以學習的種類非常多樣,例如點選使用者的行為資料,以及使用者的解釋資訊。實際上使用者的解釋的資訊對于機器學習而言是非常重要的。
如上圖的例子,小明根據ab/b=a,推導出SinX/n=six。老師則認為這是不對的,因為Sin是整體,是三角函數。
是以,基于上述觀察,我們在ACL 2022會議論文中提出,不僅進行因果推理的任務,還需要給出相應的解釋。不隻是針對某因果對解釋,可以是概念性的解釋。
例如将鐵塊加入鹽酸中,導緻鐵塊被溶解。需要生成概念性的解釋酸具有腐蝕性,顯然這不隻是因果對的解釋。
目前的因果推理系統仍缺乏此類常識。例如,現有的因果推理資料集隻提供因果對及其标簽,缺少對因果關系原理層面的解釋。而人類能夠同時運用具體的因果知識,以及對于因果機制的深入了解以高效、可靠地推理出因果關系。是以,未來認知推理,它一定需要和腦科學進行結合。
雷峰網雷峰網