1,簡述socket 通信原理
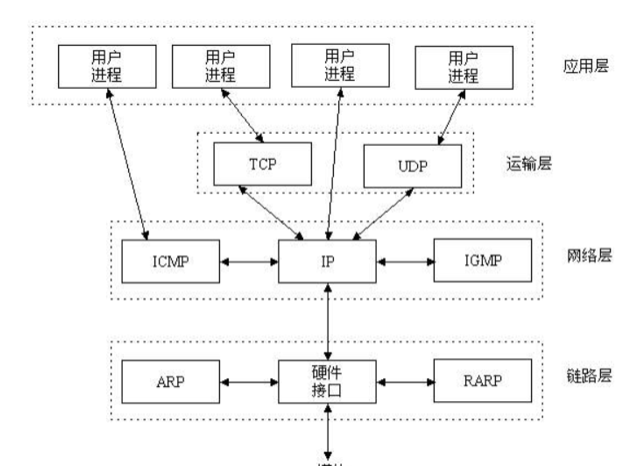

如上圖,socket通信建立在應用層與TCP/IP協定組通信(運輸層)的中間軟體抽象層,它是一組接口,在設計模式中,socket其實就是一個門面模式,它把複雜的TCP/IP協定組隐藏在Socket接口後面,對于使用者來說,一組簡單的接口就是全部,讓socket去組織資料,以符合指定的協定。
是以,經常對使用者來講,socket就是ip+prot 即IP位址(識别網際網路中主機的位置)+port是程式開啟的端口号
socket通信如下:
用戶端
# _*_ coding: utf-8 _*_
import socket
ip_port = ('127.0.0.1',9696)
link = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
link.connect(ip_port)
print("開始發送資料")
cmd = input("client請輸入要發送的資料>>>>").strip()
link.send(cmd.encode('utf-8'))
recv_data = link.recv(1024)
print("這是受到的消息:",recv_data)
link.close()
服務端
# _*_ coding: utf-8 _*_
import socket
ip_port = ('127.0.0.1',9696)
link = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
link.bind(ip_port)
link.listen(5)
conn,addr = link.accept()
#這裡,因為我們知道自己寫的少,是以1024夠用
recv_data = conn.recv(1024)
print("這是受到的消息:",recv_data)
cmd = input("server請輸入要發送的資料>>>>").strip()
conn.send(cmd.encode('utf-8'))
conn.close()
link.close()
2,粘包的原因和解決方法?
TCP是面向流的協定,發送檔案内容是按照一段一段位元組流發送的,在接收方看來不知道檔案的位元組流從和開始,從何結束。
UDP是面向消息的協定,每個UDP段都是一個消息,
直接原因:
所謂粘包問題主要還是因為接收方不知道消息之間的界限,不知道一次性提取多少位元組的資料所造成的
根本原因:
發送方引起的粘包是由TCP協定本身造成的,TCP為了提高傳送效率,發送方往往要收集到足夠多的資料
才發送一個TCP段,若連續幾次需要send的資料都很少,通常TCP會根據優化算法把這些資料合成到一個TCP
段後一次發送過去,這樣接收方就受到了粘包資料。
如果需要一直收發消息,加一個while True即可。但是這裡有個1024的問題,即粘包,
粘包的根源在于:接收端不知道發送端将要發的位元組流的長度,是以解決粘包問題的方法就是圍繞如何讓發送端在發送資料前,把自己将要發送的位元組流大小讓接收段知道,然後接收端來一個死循環,接收完所有的資料即可。
粘包解決的具體做法:為位元組流加上自定義固定長度報頭,報頭中包含位元組流長度,然後依次send到對端,對端在接受時,先從緩存中取出定長的報頭,然後再取真是資料。
# _*_ coding: utf-8 _*_
import socket
import struct
import json
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.connect(('127.0.0.1',8080)) #連接配接伺服器
while True:
# 發收消息
cmd = input('請你輸入指令>>:').strip()
if not cmd:continue
phone.send(cmd.encode('utf-8')) #發送
#先收報頭的長度
header_len = struct.unpack('i',phone.recv(4))[0] #吧bytes類型的反解
#在收報頭
header_bytes = phone.recv(header_len) #收過來的也是bytes類型
header_json = header_bytes.decode('utf-8') #拿到json格式的字典
header_dic = json.loads(header_json) #反序列化拿到字典了
total_size = header_dic['total_size'] #就拿到資料的總長度了
#最後收資料
recv_size = 0
total_data=b''
while recv_size<total_size: #循環的收
recv_data = phone.recv(1024) #1024隻是一個最大的限制
recv_size+=len(recv_data) #有可能接收的不是1024個位元組,或許比1024多呢,
# 那麼接收的時候就接收不全,是以還要加上接收的那個長度
total_data+=recv_data #最終的結果
print('傳回的消息:%s'%total_data.decode('gbk'))
phone.close()
# _*_ coding: utf-8 _*_
import socket
import subprocess
import struct
import json
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #買手機
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind(('127.0.0.1',8080)) #綁定手機卡
phone.listen(5) #阻塞的最大數
print('start runing.....')
while True: #連結循環
coon,addr = phone.accept()# 等待接電話
print(coon,addr)
while True: #通信循環
# 收發消息
cmd = coon.recv(1024) #接收的最大數
print('接收的是:%s'%cmd.decode('utf-8'))
#處理過程
res = subprocess.Popen(cmd.decode('utf-8'),shell = True,
stdout=subprocess.PIPE, #标準輸出
stderr=subprocess.PIPE #标準錯誤
)
stdout = res.stdout.read()
stderr = res.stderr.read()
# 制作報頭
header_dic = {
'total_size': len(stdout)+len(stderr), # 總共的大小
'filename': None,
'md5': None
}
header_json = json.dumps(header_dic) #字元串類型
header_bytes = header_json.encode('utf-8') #轉成bytes類型(但是長度是可變的)
#先發報頭的長度
coon.send(struct.pack('i',len(header_bytes))) #發送固定長度的報頭
#再發報頭
coon.send(header_bytes)
#最後發指令的結果
coon.send(stdout)
coon.send(stderr)
coon.close()
phone.close()
3,TCP/IP協定詳情
TCP和UDP協定在傳輸層
4,簡述3次握手,四次揮手?
三次握手:
client發送請求建立通道;
server收到請求并同意,同時也發送請求建通道;
client收到請求并同意,建立完成
四次揮手:
client發送請求斷開通道;
server收到請求并同意,同時還回複client上一條消息;
server也發送請求斷開通道;
client受到消息結束
5,定義一個學生類,然後。。。
__init__被稱為構造方法或者初始化方法,在例執行個體化過程中自動執行,目的是初始化執行個體的一些屬性,每個執行個體通過__init__初始化的屬性都是獨有的。
self就是執行個體本身,你執行個體化時候python解釋器就會自動把這個執行個體本身通過self參數傳進去。
這個object,就是經典類與新式類的問題了。
1.隻有在python2中才分新式類和經典類,python3中統一都是新式類
2.在python2中,沒有顯式的繼承object類的類,以及該類的子類,都是經典類
3.在python2中,顯式地聲明繼承object的類,以及該類的子類,都是新式類
4.在python3中,無論是否繼承object,都預設繼承object,即python3中所有類均為新式類
# _*_ coding: utf-8 _*_
class Student(object):
def __init__(self,name,age,sex):
self.name = name
self.sex = sex
self.age = age
def talk(self):
print("hello,my name is %s "%self.name)
p = Student('james',12,'male')
p.talk()
print(p.__dict__)
# 結果:
# hello,my name is james
# {'name': 'james', 'sex': 'male', 'age': 12}
6,繼承
繼承:
繼承就是類與類的關系,是一種建立新類的方式,在python中,建立的類可以繼承一個或多個父類,父類可以稱為基類或超類,建立的類稱為派生類或子類。
python中類的繼承分為:單繼承和多繼承
class ParentClass1: #定義父類
pass
class ParentClass2: #定義父類
pass
class SubClass1(ParentClass1): #單繼承,基類是ParentClass1,派生類是SubClass
pass
class SubClass2(ParentClass1,ParentClass2): #python支援多繼承,用逗号分隔開多個繼承的類
pass
檢視繼承:
>>> SubClass1.__bases__
#__base__隻檢視從左到右繼承的第一個子類,__bases__則是檢視所有繼承的父類
(<class '__main__.ParentClass1'>,)
>>> SubClass2.__bases__
(<class '__main__.ParentClass1'>, <class '__main__.ParentClass2'>)
7,多态
多态指一種事物有多種形态,那為什麼要使用多态呢?
1.增加了程式的靈活性
以不變應萬變,不論對象千變萬化,使用者都是同一種形式去調用,如func(animal)
2.增加了程式額可擴充性
通過繼承animal類建立了一個新的類,使用者無需更改自己的代碼,還是用func(animal)去調用
舉個例子:
>>> class Cat(Animal): #屬于動物的另外一種形态:貓
... def talk(self):
... print('say miao')
...
>>> def func(animal): #對于使用者來說,自己的代碼根本無需改動
... animal.talk()
...
>>> cat1=Cat() #執行個體出一隻貓
>>> func(cat1) #甚至連調用方式也無需改變,就能調用貓的talk功能
say miao
'''
這樣我們新增了一個形态Cat,由Cat類産生的執行個體cat1,使用者可以在完全不需要修改
自己代碼的情況下。使用和人、狗、豬一樣的方式調用cat1的talk方法,即func(cat1)
'''
8,封裝
首先說一下隐藏,在python中用雙下劃線開頭的方式将屬性隐藏起來(即設定成私有屬性)
#其實這僅僅這是一種變形操作
#類中所有雙下劃線開頭的名稱如__x都會自動變形成:_類名__x的形式:
class A:
__N=0 #類的資料屬性就應該是共享的,但是文法上是可以把類的資料屬性設定
成私有的如__N,會變形為_A__N
def __init__(self):
self.__X=10 #變形為self._A__X
def __foo(self): #變形為_A__foo
print('from A')
def bar(self):
self.__foo() #隻有在類内部才可以通過__foo的形式通路到.
#A._A__N是可以通路到的,即這種操作并不是嚴格意義上的限制外部通路,
僅僅隻是一種文法意義上的變形
封裝不是單純意義上的隐藏
1,封裝資料
将資料隐藏起來這不是目的。隐藏起來然後對外提供操作該資料的接口,然後我們可以在接口附加上對該資料操作的限制,以此完成對資料屬性操作的嚴格控制
class Teacher:
def __init__(self,name,age):
self.__name=name
self.__age=age
def tell_info(self):
print('姓名:%s,年齡:%s' %(self.__name,self.__age))
def set_info(self,name,age):
if not isinstance(name,str):
raise TypeError('姓名必須是字元串類型')
if not isinstance(age,int):
raise TypeError('年齡必須是整型')
self.__name=name
self.__age=age
t=Teacher('egon',18)
t.tell_info()
t.set_info('egon',19)
t.tell_info()
2,封裝方法,目的是隔離複雜度
#取款是功能,而這個功能有很多功能組成:插卡、密碼認證、輸入金額、列印賬單、取錢
#對使用者來說,隻需要知道取款這個功能即可,其餘功能我們都可以隐藏起來,很明顯這麼做
#隔離了複雜度,同時也提升了安全性
class ATM:
def __card(self):
print('插卡')
def __auth(self):
print('使用者認證')
def __input(self):
print('輸入取款金額')
def __print_bill(self):
print('列印賬單')
def __take_money(self):
print('取款')
def withdraw(self):
self.__card()
self.__auth()
self.__input()
self.__print_bill()
self.__take_money()
a=ATM()
a.withdraw()
9,元類? 使用元類定義一個對象
元類是類的類,是類的模闆
元類是用來控制如何建立類的,正如類是建立對象的模闆一樣,而元類的主要目的是為了控制類的建立行為
元類的執行個體化的結果為我們用class定義的類,正如類的執行個體為對象(f1對象是Foo類的一個執行個體,
Foo類是 type 類的一個執行個體)
10,說一下__new__和__init__的差別
根據官方文檔:
- __init__是當執行個體對象建立完成後被調用的,然後設定對象屬性的一些初始值。
- __new__是在執行個體建立之前被調用的,因為它的任務就是建立執行個體然後傳回該執行個體,是個靜态方法。
也就是,__new__在__init__之前被調用,__new__的傳回值(執行個體)将傳遞給__init__方法的第一個參數,然後__init__給這個執行個體設定一些參數。
在python2.x中,從object繼承得來的類稱為新式類(如class A(object))不從object繼承得來的類稱為經典類(如class A()
新式類跟經典類的差别主要是以下幾點:
1. 新式類對象可以直接通過__class__屬性擷取自身類型:type
2. 繼承搜尋的順序發生了改變,經典類多繼承時屬性搜尋順序: 先深入繼承樹左側,再傳回,開始找右側(即深度優先搜尋);新式類多繼承屬性搜尋順序: 先水準搜尋,然後再向上移動
例子:
經典類: 搜尋順序是(D,B,A,C)
>>> class A: attr = 1
...
>>> class B(A): pass
...
>>> class C(A): attr = 2
...
>>> class D(B,C): pass
...
>>> x = D()
>>> x.attr
1
新式類繼承搜尋程式是寬度優先
新式類:搜尋順序是(D,B,C,A)
>>> class A(object): attr = 1
...
>>> class B(A): pass
...
>>> class C(A): attr = 2
...
>>> class D(B,C): pass
...
>>> x = D()
>>> x.attr
2
3. 新式類增加了__slots__内置屬性, 可以把執行個體屬性的種類鎖定到__slots__規定的範圍之中。
4. 新式類增加了__getattribute__方法
5.新式類内置有__new__方法而經典類沒有__new__方法而隻有__init__方法
注意:Python 2.x中預設都是經典類,隻有顯式繼承了object才是新式類
而Python 3.x中預設都是新式類(也即object類預設是所有類的祖先),不必顯式的繼承object(可以按照經典類的定義方式寫一個經典類并分别在python2.x和3.x版本中使用dir函數檢驗下。
例如:
class A():
pass
print(dir(A))
會發現在2.x下沒有__new__方法而3.x下有。
接下來說下__new__方法和__init__的差別:
在python中建立類的一個執行個體時,如果該類具有__new__方法,會先調用__new__方法,__new__方法接受目前正在執行個體化的類作為第一個參數(這個參數的類型是type,這個類型在c和python的互動程式設計中具有重要的角色,感興趣的可以搜下相關的資料),其傳回值是本次建立産生的執行個體,也就是我們熟知的__init__方法中的第一個參數self。那麼就會有一個問題,這個執行個體怎麼得到?
注意到有__new__方法的都是object類的後代,是以如果我們自己想要改寫__new__方法(注意不改寫時在建立執行個體的時候使用的是父類的__new__方法,如果父類沒有則繼續上溯)可以通過調用object的__new__方法類得到這個執行個體(這實際上也和python中的預設機制基本一緻),如:
class display(object):
def __init__(self, *args, **kwargs):
print("init")
def __new__(cls, *args, **kwargs):
print("new")
print(type(cls))
return object.__new__(cls, *args, **kwargs)
a=display()
運作上述代碼會得到如下輸出:
new
<class 'type'>
init
是以我們可以得到如下結論:
在執行個體建立過程中__new__方法先于__init__方法被調用,它的第一個參數類型為type。
如果不需要其它特殊的處理,可以使用object的__new__方法來得到建立的執行個體(也即self)。
于是我們可以發現,實際上可以使用其它類的__new__方法類得到這個執行個體,隻要那個類或其父類或祖先有__new__方法。
class another(object):
def __new__(cls,*args,**kwargs):
print("newano")
return object.__new__(cls, *args, **kwargs)
class display(object):
def __init__(self, *args, **kwargs):
print("init")
def __new__(cls, *args, **kwargs):
print("newdis")
print(type(cls))
return another.__new__(cls, *args, **kwargs)
a=display()
上面的輸出是:
newdis
<class 'type'>
newano
init
所有我們發現__new__和__init__就像這麼一個關系,__init__提供生産的原料self(但并不保證這個原料來源正宗,像上面那樣它用的是另一個不相關的類的__new__方法類得到這個執行個體),而__init__就用__new__給的原料來完善這個對象(盡管它不知道這些原料是不是正宗的)
11,說一下深度優先和廣度優先的差別
隻有在python2中才分新式類和經典類,python3中統一都是新式類
2.在python2中,沒有顯式的繼承object類的類,以及該類的子類,都是經典類
3.在python2中,顯式地聲明繼承object的類,以及該類的子類,都是新式類
4.在python3中,無論是否繼承object,都預設繼承object,即python3中所有類均為新式類
在Java和C#中子類隻能繼承一個父類,而Python中子類可以同時繼承多個父類,如果繼承了多個父類,那麼屬性的查找方式有兩種,分别是:深度優先和廣度優先
示範代碼
class A(object):
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B):
def test(self):
print('from D')
class E(C):
def test(self):
print('from E')
class F(D,E):
# def test(self):
# print('from F')
pass
f1=F()
f1.test()
print(F.__mro__) #隻有新式才有這個屬性可以檢視線性清單,經典類沒有這個屬性
#新式類繼承順序:F->D->B->E->C->A
#經典類繼承順序:F->D->B->A->E->C
#python3中統一都是新式類
#pyhon2中才分新式類與經典類
12,說一下反射的原理
反射就是通過字元串映射到對象的屬性,python的一切事物都是對象(都可以使用反射)
1,hasattr(object,name)
判斷object中有沒有對應的方法和屬性
判斷object中有沒有一個name字元串對應的方法或屬性
2,getattr(object, name, default=None) 擷取object中有沒有對應的方法和屬性
3,setattr(x, y, v) 設定對象及其屬性
4,delattr(x, y) 删除類或對象的屬性
13,編寫程式, 在元類中控制把自定義類的資料屬性都變成大寫.
class Mymetaclass(type):
def __new__(cls,name,bases,attrs):
update_attrs={}
for k,v in attrs.items():
if not callable(v) and not k.startswith('__'):
update_attrs[k.upper()]=v
else:
update_attrs[k]=v
return type.__new__(cls,name,bases,update_attrs)
class Chinese(metaclass=Mymetaclass):
country='China'
tag='Legend of the Dragon' #龍的傳人
def walk(self):
print('%s is walking' %self.name)
print(Chinese.__dict__)
'''
{'__module__': '__main__',
'COUNTRY': 'China',
'TAG': 'Legend of the Dragon',
'walk': <function Chinese.walk at 0x0000000001E7B950>,
'__dict__': <attribute '__dict__' of 'Chinese' objects>,
'__weakref__': <attribute '__weakref__' of 'Chinese' objects>,
'__doc__': None}
'''
14,編寫程式, 在元類中控制自定義的類無需init方法.
1.元類幫其完成建立對象,以及初始化操作;
2.要求執行個體化時傳參必須為關鍵字形式,否則抛出異常TypeError: must use keyword argument
3.key作為使用者自定義類産生對象的屬性,且所有屬性變成大寫
class Mymetaclass(type):
# def __new__(cls,name,bases,attrs):
# update_attrs={}
# for k,v in attrs.items():
# if not callable(v) and not k.startswith('__'):
# update_attrs[k.upper()]=v
# else:
# update_attrs[k]=v
# return type.__new__(cls,name,bases,update_attrs)
def __call__(self, *args, **kwargs):
if args:
raise TypeError('must use keyword argument for key function')
obj = object.__new__(self) #建立對象,self為類Foo
for k,v in kwargs.items():
obj.__dict__[k.upper()]=v
return obj
class Chinese(metaclass=Mymetaclass):
country='China'
tag='Legend of the Dragon' #龍的傳人
def walk(self):
print('%s is walking' %self.name)
p=Chinese(name='egon',age=18,sex='male')
print(p.__dict__)
15,簡述靜态方法和類方法
1:綁定方法(綁定給誰,誰來調用就自動将它本身當作第一個參數傳入):
綁定方法分為綁定到類的方法和綁定到對象的方法,具體如下:
1. 綁定到類的方法:用classmethod裝飾器裝飾的方法。
為類量身定制
類.boud_method(),自動将類當作第一個參數傳入
(其實對象也可調用,但仍将類當作第一個參數傳入)
2. 綁定到對象的方法:沒有被任何裝飾器裝飾的方法。
為對象量身定制
對象.boud_method(),自動将對象當作第一個參數傳入
(屬于類的函數,類可以調用,但是必須按照函數的規則來,沒有自動傳值那麼一說)
2:非綁定方法:用staticmethod裝飾器裝飾的方法
1. 不與類或對象綁定,類和對象都可以調用,但是沒有自動傳值那麼一說。就是一個普通工具而已
注意:與綁定到對象方法區分開,在類中直接定義的函數,沒有被任何裝飾器
裝飾的,都是綁定到對象的方法,可不是普通函數,對象調用該方法會自動傳值,而
staticmethod裝飾的方法,不管誰來調用,都沒有自動傳值一說
具體見:http://www.cnblogs.com/wj-1314/p/8675548.html
3,類方法與靜态方法說明
1:self表示為類型為類的object,而cls表示為類也就是class
2:在定義普通方法的時候,需要的是參數self,也就是把類的執行個體作為參數傳遞給方法,如果不寫self的時候,會發現報錯TypeError錯誤,表示傳遞的參數多了,其實也就是調用方法的時候,将執行個體作為參數傳遞了,在使用普通方法的時候,使用的是執行個體來調用方法,不能使用類來調用方法,沒有執行個體,那麼方法将無法調用。
3:在定義靜态方法的時候,和子產品中的方法沒有什麼不同,最大的不同就是在于靜态方法在類的命名空間之間,而且在聲明靜态方法的時候,使用的标記為@staticmethod,表示為靜态方法,在叼你用靜态方法的時候,可以使用類名或者是執行個體名來進行調用,一般使用類名來調用
4:靜态方法主要是用來放一些方法的,方法的邏輯屬于類,但是有何類本身沒有什麼互動,進而形成了靜态方法,主要是讓靜态方法放在此類的名稱空間之内,進而能夠更加有組織性。
5:在定義類方法的時候,傳遞的參數為cls.表示為類,此寫法也可以變,但是一般寫為cls。類的方法調用可以使用類,也可以使用執行個體,一般情況使用的是類。
6:在重載調用父類方法的時候,最好是使用super來進行調用父類的方法。靜态方法主要用來存放邏輯性的代碼,基本在靜态方法中,不會涉及到類的方法和類的參數。類方法是在傳遞參數的時候,傳遞的是類的參數,參數是必須在cls中進行隐身穿
7:python中實作靜态方法和類方法都是依賴python的修飾器來實作的。靜态方法是staticmethod,類方法是classmethod。
不經一番徹骨寒 怎得梅花撲鼻香