Fine-Tuning微調原理
如何在隻有60000張圖檔的Fashion-MNIST訓練資料集中訓練模型。ImageNet,這是學術界使用最廣泛的大型圖像資料集,它擁有1000多萬幅圖像和1000多個類别的對象。然而,我們經常處理的資料集的大小通常比第一個大,但比第二個小。
假設我們想在圖像中識别不同種類的椅子,然後将購買連結推給使用者。一種可行的方法是先找到一百張常見的椅子,每把椅子取一千張不同角度的圖像,然後在采集到的圖像資料集上訓練分類模型。雖然這個資料集可能比時尚MNIST大,但是示例的數量仍然不到ImageNet的十分之一。這可能導緻适用于ImageNet的複雜模型在此資料集上過度拟合。同時,由于資料量有限,最終訓練出的模型精度可能達不到實際要求。
為了解決上述問題,一個顯而易見的解決辦法就是收集更多的資料。然而,收集和标記資料會消耗大量的時間和金錢。例如,為了收集ImageNet的資料集,研究人員花費了數百萬美元的研究經費。盡管近年來,資料采內建本大幅下降,但成本仍然不容忽視。
另一種解決方案是應用轉移學習将從源資料集學習的知識遷移到目标資料集。例如,雖然ImageNet中的圖像大多與椅子無關,但是在這個資料集上訓練的模型可以提取更一般的圖像特征,這些特征可以幫助識别邊緣、紋理、形狀和對象組成。這些相似的特征對于識别椅子同樣有效。
在本節中,我們将介紹遷移學習中的一種常用技術:微調。如圖13.2.1所示,微調包括以下四個步驟:
在源資料集(例如ImageNet資料集)上預訓練神經網絡模型,即源模型。
建立一個新的神經網絡模型,即目标模型。這将複制源模型上的所有模型設計及其參數,輸出層除外。我們假設這些模型參數包含從源資料集學習到的知識,這些知識将同樣适用于目标資料集。我們還假設源模型的輸出層與源資料集的标簽密切相關,是以不在目标模型中使用。
将輸出大小為目标資料集類别數的輸出層添加到目标模型中,并随機初始化該層的模型參數。
在目标資料集上訓練目标模型,例如椅子資料集。我們将從頭開始訓練輸出層,同時根據源模型的參數對所有剩餘層的參數進行微調。
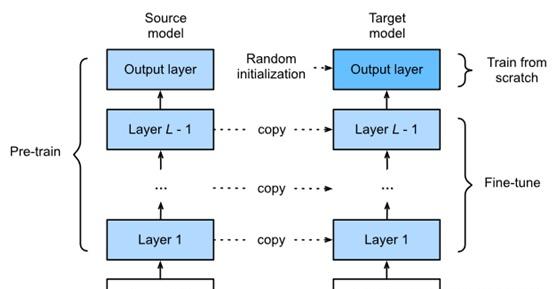
Fig. 1. Fine tuning.
1. Hot Dog Recognition
我們将使用一個具體的例子來練習:熱狗識别。我們将基于一個小的資料集,對在ImageNet資料集上訓練的ResNet模型進行微調。這個小資料集包含數千張圖像,其中一些包含熱狗。我們将使用通過微調獲得的模型來識别圖像是否包含熱狗。
首先,導入實驗所需的軟體包和子產品。Gluon的model_zoo package提供了一個通用的預訓練模型。如果你想獲得更多的計算機視覺的預先訓練模型,你可以使用GluonCV工具箱。
%matplotlib inline
from d2l import mxnet as d2l
from mxnet import gluon, init, np, npx
from mxnet.gluon import nn
import os
npx.set_np()
1.1. Obtaining the Dataset
我們使用的熱狗資料集來自線上圖像,包含1400個熱狗的正面圖檔和其他食物的相同數量的負面圖檔。1000個各種課程的圖像用于訓練,其餘的用于測試。
我們首先下載下傳壓縮資料集,得到兩個檔案夾hotdog/train和hotdog/test。這兩個檔案夾都有hotdog和not hotdog類别子檔案夾,每個子檔案夾都有相應的圖像檔案。
#@save
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL+'hotdog.zip',
'fba480ffa8aa7e0febbb511d181409f899b9baa5')
data_dir = d2l.download_extract('hotdog')
Downloading ../data/hotdog.zip from http://d2l-data.s3-accelerate.amazonaws.com/hotdog.zip...
我們建立兩個ImageFolderDataset執行個體,分别讀取訓練資料集和測試資料集中的所有圖像檔案。
train_imgs = gluon.data.vision.ImageFolderDataset(
os.path.join(data_dir, 'train'))
test_imgs = gluon.data.vision.ImageFolderDataset(
os.path.join(data_dir, 'test'))
前8個正面示例和最後8個負面圖像如下所示。如您所見,圖像的大小和縱橫比各不相同。
hotdogs = [train_imgs[i][0] for i in range(8)]
not_hotdogs = [train_imgs[-i - 1][0] for i in range(8)]
d2l.show_images(hotdogs + not_hotdogs, 2, 8, scale=1.4);

在訓練過程中,我們首先從圖像中裁剪出一個大小和縱橫比随機的随機區域,然後将該區域縮放到一個高度和寬度為224像素的輸入。在測試過程中,我們将圖像的高度和寬度縮放到256像素,然後裁剪高寬為224像素的中心區域作為輸入。此外,我們規範化三個RGB(紅色、綠色和藍色)顔色通道的值。從每個值中減去信道所有值的平均值,然後将結果除以信道所有值的标準差,以産生輸出。
# We specify the mean and variance of the three RGB channels to normalize the
# image channel
normalize = gluon.data.vision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
train_augs = gluon.data.vision.transforms.Compose([
gluon.data.vision.transforms.RandomResizedCrop(224),
gluon.data.vision.transforms.RandomFlipLeftRight(),
gluon.data.vision.transforms.ToTensor(),
normalize])
test_augs = gluon.data.vision.transforms.Compose([
gluon.data.vision.transforms.Resize(256),
gluon.data.vision.transforms.CenterCrop(224),
1.2. Defining and Initializing the Model
我們使用ResNet-18作為源模型,ResNet-18是在ImageNet資料集上預先訓練的。這裡,我們指定pretrained=True以自動下載下傳和加載預先訓練的模型參數。第一次使用時,需要從網際網路上下載下傳模型參數。
pretrained_net = gluon.model_zoo.vision.resnet18_v2(pretrained=True)
預先訓練的源模型執行個體包含兩個成員變量:features和output。前者包含模型的所有層,輸出層除外,後者是模型的輸出層。這一劃分的主要目的是促進除輸出層之外的所有層的模型參數的微調。源模型的成員變量輸出如下所示。作為一個完全連接配接的層,它将ResNet最終的全局平均池層輸出轉換為ImageNet資料集上的1000個類輸出。
pretrained_net.output
Dense(512 -> 1000, linear)
然後建構一個新的神經網絡作為目标模型。它的定義方式與預先訓練的源模型相同,但最終輸出數量等于目标資料集中的類别數。在下面的代碼中,目标模型執行個體finetune_net的成員變量特征中的模型參數初始化為源模型對應層的模型參數。由于特征中的模型參數是通過對ImageNet資料集的預訓練得到的,是以它是足夠好的。是以,我們通常隻需要使用較小的學習速率來“微調”這些參數。相比之下,成員變量輸出中的模型參數是随機初始化的,通常需要更大的學習速率才能從頭開始學習。假設訓練執行個體中的學習率為 η,學習率為10η,更新成員變量輸出中的模型參數。
finetune_net = gluon.model_zoo.vision.resnet18_v2(classes=2)
finetune_net.features = pretrained_net.features
finetune_net.output.initialize(init.Xavier())
# The model parameters in output will be updated using a learning rate ten
# times greater
finetune_net.output.collect_params().setattr('lr_mult', 10)
1.3. Fine Tuning the Model
我們首先定義了一個訓練函數train_fine_tuning,它使用了微調,是以可以多次調用它。
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5):
train_iter = gluon.data.DataLoader(
train_imgs.transform_first(train_augs), batch_size, shuffle=True)
test_iter = gluon.data.DataLoader(
test_imgs.transform_first(test_augs), batch_size)
ctx = d2l.try_all_gpus()
net.collect_params().reset_ctx(ctx)
net.hybridize()
loss = gluon.loss.SoftmaxCrossEntropyLoss()
trainer = gluon.Trainer(net.collect_params(), 'sgd', {
'learning_rate': learning_rate, 'wd': 0.001})
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, ctx)
我們将訓練器執行個體中的學習率設定為一個較小的值,如0.01,以便對預訓練中獲得的模型參數進行微調。基于前面的設定,我們将使用10倍以上的學習率從頭開始訓練目标模型的輸出層參數。
train_fine_tuning(finetune_net, 0.01)
loss 0.518, train acc 0.890, test acc 0.927
634.3 examples/sec on [gpu(0), gpu(1)]
為了進行比較,我們定義了一個相同的模型,但将其所有模型參數初始化為随機值。由于整個模型需要從頭開始訓練,是以我們可以使用更大的學習率。
scratch_net = gluon.model_zoo.vision.resnet18_v2(classes=2)
scratch_net.initialize(init=init.Xavier())
train_fine_tuning(scratch_net, 0.1)
loss 0.371, train acc 0.839, test acc 0.784
706.5 examples/sec on [gpu(0), gpu(1)]
正如您所看到的,由于參數的初始值更好,微調後的模型往往在同一時代獲得更高的精度。
2. Summary
· Transfer learning migrates the knowledge learned from the source dataset to the target dataset. Fine tuning is a common technique for transfer learning.