為了安全高效地在道路上行駛,自動駕駛汽車必須具有像人類駕駛員一樣預測周圍交通參與者行為的能力。目前,軌迹預測的相關研究受到了越來越多的重視。這篇文章主要解決軌迹預測的一個難點,即預測的多模态。同時,這篇文章的另一個亮點是通過卷積光栅圖像來實作預測。作者通過實驗得到了目前最優的預測效果。這篇文章對軌迹預測相關領域的研究具有一定的學習和參考價值。
無論是在難度還是潛在的社會影響方面,自動駕駛是目前人工智能領域面臨的最大問題之一。自動駕駛車輛(SDVs)有望在改善更多人的生活品質的同時,減少道路事故,挽救數百萬人的生命。然而,盡管有大量的關注和在自動駕駛領域工作的行業參與者,為了開發一個能與最好的人類駕駛員操作水準相當的系統,仍有許多工作要做。其中一個原因是交通行為的高度不确定性以及SDV在道路上可能遇到的大量情況,使得很難建立一個完全通用的系統。為了確定安全和高效的運作,自動駕駛車輛需要考慮到這種不确定性,并預測周圍交通參與者的多種可能行為。我們解決了這個關鍵問題,并提出了一種方法來預測多個可能的軌迹,同時估計它們的機率。該方法将每個參與者的周圍環境編碼成一個光栅圖像,作為深度卷積網絡的輸入,以自動獲得任務的相關特征。經過大量的離線評估和與最新基準的比較,該方法成功地在SDVs上完成了封閉道路測試。
近年來,人工智能(AI)應用領域取得了前所未有的進展,智能算法迅速成為我們日常生活中不可或缺的一部分。舉幾個影響了數百萬人的例子:醫院使用人工智能方法來幫助診斷疾病[1],婚介服務使用學習的模型來連接配接潛在的夫婦[2],而社交媒體訂閱源則通過算法[3]來建構。盡管如此,人工智能革命仍遠未結束,并有可能在未來幾年進一步加速。有趣的是,汽車領域是主要的産業之一,目前為止人工智能的應用還很有限。大型汽車制造商通過在進階駕駛輔助系統(ADAS)中使用人工智能(AI)取得了一些進展[5],然而,它的全部能力仍有待通過新的智能技術的出現加以利用,例如自動駕駛汽車(SDVs)。
盡管駕駛車輛對許多人來說是很平常的活動,但也是一項危險任務,甚至對于有幾年經驗的人類駕駛員來說也是如此[6]。雖然汽車制造商正努力通過更好的設計和ADAS系統來提高汽車安全性,但年複一年的統計資料表明,仍有許多工作要做來扭轉公共道路上的負面趨勢。尤其是2015年美國的車禍死亡人數占總死亡人數的5%以上[7],絕大多數車禍都是人為因素造成的[8]。不幸的是,這并不是最近才出現的問題,幾十年來,研究人員一直在試圖了解其原因。研究包括調查司機分心的影響[9]、酒精和毒品使用[10]、[11]和司機年齡[6]等因素,以及如何最有效地讓司機接受自己是易犯錯誤的并最高效地影響他們的行為[12]。毫不奇怪,現有文獻中的一個共同主題是,人類是交通系統中最不可靠的部分。這可以通過SDV的發展和廣泛應用來改善。硬體和軟體技術的最新突破使這一前景成為可能,為機器人和人工智能領域打開了大門,進而可能産生迄今為止最大的社會影響。
自動駕駛技術已經發展了很長一段時間,最早的嘗試可以追溯到20世紀80年代,關于AL-VINN的研究[13]。然而,直到最近,技術進步才達到一個可以更廣泛使用的程度,例如2007年DARPA城市挑戰的結果[14],[15]。在這裡,參賽隊伍必須在複雜的城市環境中導航,處理公共道路上常見的情況,并與人和機器人駕駛的車輛進行互動。這些早期的成功激發了人們對自動駕駛領域的極大興趣,許多行業參與者(如Uber和Waymo)和政府機構正競相為實作SDVs建立技術和法律基礎。然而盡管取得了進展,仍有更多的工作要做,來使SDVs以人的水準運作并充分商業化。
要在現實世界中安全有效地運作,一個關鍵的難題是正确地預測周圍參與者的運動,一個成功的系統還需要考慮到他們固有的多模态特性。我們專注于這項任務,并以我們部署的基于深度學習的工作[16]為基礎,建立了編碼高清地圖和環境的鳥瞰圖(BEV)光栅,以預測參與者的未來,并提出以下貢獻:
(1)我們擴充了現有技術,提出了一種方法,取代單一軌迹的推斷,而給出了多條軌迹及其機率;
(2) 在對多假設方法進行廣泛的離線研究之後,該方法成功地在SDV上進行了封閉道路測試。
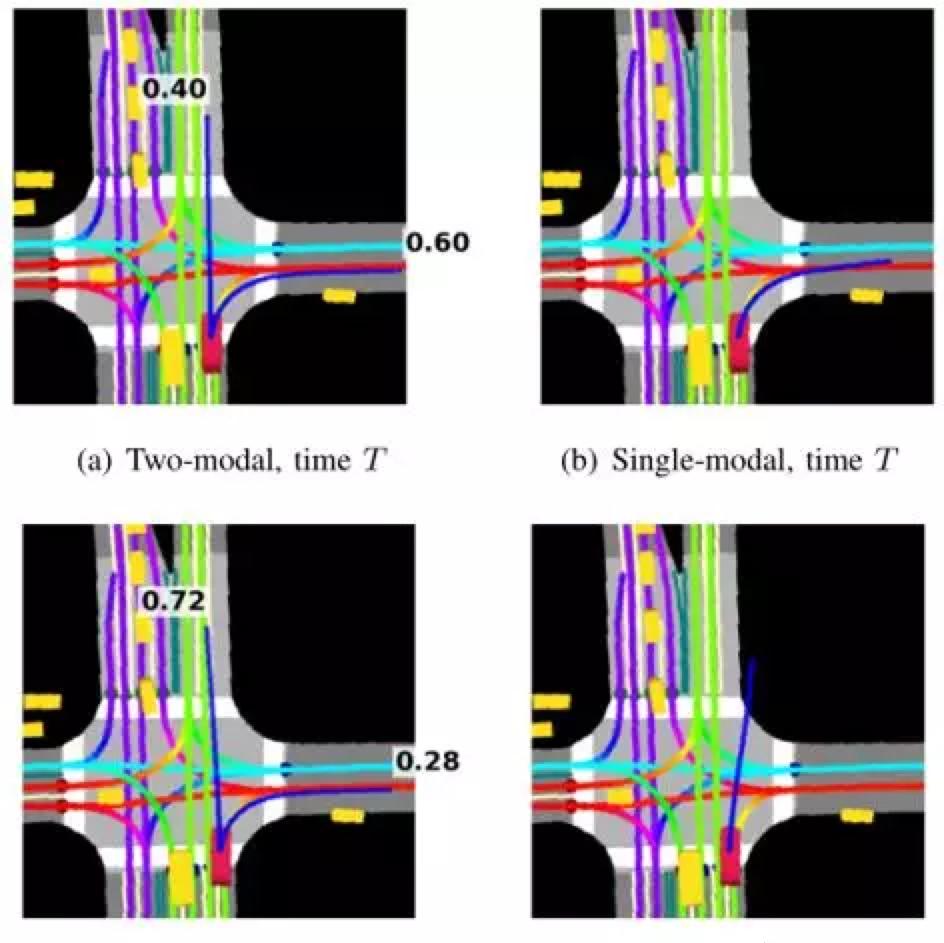
圖1顯示了我們的模型如何捕獲未來6秒軌迹的多模态。該方法使用光栅化的車輛上下文(包括高清地圖和其他參與者)作為模型輸入,以預測參與者在動态環境中的運動[16]。當車輛接近交叉口時,多模态模型(其中我們将模态數設定為2)估計直行的機率比右轉的機率略低,見圖1a。在三個步驟後,車輛繼續直行,此時右轉的機率顯著下降(圖1c);注意,實際上車輛繼續直行通過交叉口。我們可以看到,單模态模型不能捕捉場景的多模态,而是粗略地預測兩種模态的平均值,如圖1b和1d所示。
相關工作
預測參與者未來動作的問題已在最近的一些出版物中讨論過。本課題的全面概述見[17]、[18],在本節中,我們将從自主駕駛的角度回顧相關工作。首先,我們将介紹自動駕駛行業中實際應用的工程方法。然後,我們讨論了用于運動預測的機器學習方法,特别強調了深度學習方法。
自動駕駛系統中的運動預測
大多數部署的自動駕駛系統使用成熟的工程方法來預測參與者的動作。常用的方法包括根據底層實體系統的假設和利用卡爾曼濾波(KF)[19],[20]等技術,通過随時間傳播對象的狀态來計算對象的未來運動。雖然這種方法對短期預測效果很好,但由于模型忽略了周圍的環境(如道路、其他參與者、交通規則),其性能在較長時間内會下降。針對這一問題,MercedesBenz[21]提出的方法利用地圖資訊作為限制條件來計算車輛的長期未來位置。系統首先将每個檢測到的車輛與地圖上的一條或多條車道相關聯。然後,基于地圖拓撲、車道連通性和車輛目前狀态估計,為每個車輛和相關車道對生成所有可能的路徑。這種啟發式方法在一般情況下提供了合理的預測,但是它對車輛和車道關聯的誤差很敏感。作為現有的部署工程方法的替代,所提出的方法自動地從車輛通常遵守道路和車道限制的資料中學習,同時很好地推廣到在道路上觀察到的各種情況。此外,結合現有的車道關聯的想法,我們提出了一個我們方法的擴充。
機器學習預測模型
人工設計的模型無法擴充到許多不同的交通場景,這促使機器學習模型成為替代方案,如隐馬爾可夫模型[22]、貝葉斯網絡[23]或高斯過程[24]。最近研究人員關注于如何使用逆強化學習(IRL)來模拟環境背景[25]。Kitani等人[26]考慮場景語義,使用逆最優控制來預測行人路徑,然而現有的IRL方法對于實時應用來說是低效的。
深度學習在許多實際應用中的成功[27]促使人們研究它在運動預測中的應用。随着近期遞歸神經網絡(RNN)的成功,其中一條研究路線叫做長短時間記憶(LSTM)被用于序列預測任務。文獻[28],[29]的作者應用LSTM預測了行人在社會交往中的未來軌迹。在[30]中,LSTM被應用于利用過去的軌迹資料預測車輛位置。在[31]中,另一個稱為門控遞歸單元(GRU)的RNN變體與條件變分自動編碼器(CVAE)結合用于預測車輛軌迹。此外,[32],[33]通過将卷積神經網絡(CNN)應用于一系列視覺圖像,直接從圖像像素預測簡單實體系統的運動。在[16]中,作者提出了一個系統,在該系統中,使用CNNs預測短期車輛軌迹,并将編碼單個參與者周圍環境的BEV光栅圖像作為輸入,該圖像随後也應用于弱勢交通參與者[34]。盡管這些方法取得了成功,但它們并沒有解決精确的長期交通預測所需的未來可能軌迹潛在的多模态問題。
目前存在許多研究在解決多模态模組化的問題。混合密度網絡(MDNs)[35]是通過學習高斯混合模型的參數來解決多模态回歸問題的傳統神經網絡。然而,MDNs由于在高維空間中操作時的數值不穩定性,實際上經常難以訓練。
為了解決這個問題,研究人員提出訓練一個網絡集合[36],或者訓練一個網絡,用一個僅考慮最接近真值的預測結果的損失,來産生M種不同假設[37]對應的M個不同輸出。由于良好的經驗結果,我們的工作建立在這些努力的基礎上。此外,在[38]中,作者通過學習将機率配置設定給六個機動類别的模型,介紹了公路車輛多模态軌迹預測的方法。該方法需要預先定義一組可能的離散動機,這對于複雜的城市駕駛來說可能很難定義。或者,在[28]、[29]、[31]中,作者建議通過采樣生成多模态預測,這需要重複的前向傳遞來生成多個軌迹。而我們提出的方法在一個單一的前向CNN模型上,直接計算多模态的預測結果。

圖2. 本文提出的網絡架構
提出的方法
在本小節中,我們讨論提出的交通參與者多模态軌迹預測方法,我們先介紹問題定義以及符号使用,然後讨論我們設計的卷積神經網絡結構和損失函數。
問題定義
假設我們可以得到安裝在自動駕駛汽車上的傳感器,比如雷射雷達、超音波雷達或者相機的實時資料流。此外,假設這些資料被用于現存的檢測和跟蹤系統中,并輸出所有周圍交通參與者的狀态估計S(狀态包括檢測框、位置、速度、加速度、航向和航向角變化率)。定義跟蹤器輸出狀态評估的一組離散時間為,在連續的時間步之間的時間間隔是固定的(當跟蹤器工作在10Hz時,時間間隔為0.1s)。然後,我們定義跟蹤器在tj時刻對第i個交通參與者的狀态輸出為sij,這裡i=1,…,Nj。Nj是在tj時刻被跟蹤的所有交通參與者數。注意一般情況下,交通參與者的個數是時刻變化的因為新的交通參與者會出現在傳感器的感覺範圍内以及原先被跟蹤的交通參與者會超出傳感器的感覺範圍。并且,我們假設可以得到自動駕駛汽車行駛區域的詳細的高精地圖資訊M,包括道路和人行道位置,車道方向以及其他相關的地圖資訊。
多模态軌迹模組化
基于我們之前的工作[16],我們首先栅格化一個BEV栅格圖像,該圖像編碼交通參與者的地圖環境以及周圍交通參與者(比如其他的車輛和行人等),如圖一所示。然後,給定在tj時刻的第i個交通參與者的栅格圖和狀态估計sij,我們使用一個卷積神經網絡模型來預測M個可能的未來狀态序列,以及每個序列的機率。其中,m表示模态數,H表示預測的時間步長。有關栅格化方法的較長的描述,請讀者查閱我們之前的工作[16]。在不損失一般性的情況下,我們簡化了工作,我們隻推斷第i個交通參與者未來的x和y坐标而不是完整的狀态估計,而其餘的狀态估計可以通過狀态序列和未來的位置估計得到。在tj時刻交通參與者過去和未來的位置坐标都是都是相對于交通參與者在tj時刻的位置,其中前進方向為x軸,左手方向為y軸,交通參與者檢測框的中心為原點。
本文提出的網絡結構如圖2所示。輸入是300*300的分辨率為0.2米的RGB栅格圖以及交通參與者目前的狀态(車速、加速度和朝向角改變率),輸出是M個模态的未來的x坐标和y坐标(每個模态有2H個輸出)以及它們的機率(每個模态一個标量)。是以每個交通參與者有(2H+1)M的輸出。機率輸出随後被傳到softmax層以保證它們的和為1。注意任何卷積神經網絡結構可以被用作基礎網絡,這裡我們使用了MobilleNet-v2。
多模态優化函數
在這一部分我們讨論我們提出的模組化軌迹預測問題固有的多模态性的損失函數。首先,我們定義在tj時刻第i個交通參與者的第m個模态的單模态損失函數為真值軌迹點和預測的第m個模态之間的平均位移誤差(或者L2範數)。
一個簡單的多模态損失函數我們可以直接使用的是ME損失,定義如下:
然而,從我們在第四節的評估結果可以看出,由于模态崩潰問題,ME損失不适用于軌迹預測問題。為了解決這個問題,我們受到[37]的啟發提出使用一種新的多軌迹預測(MTP)損失,它明确地模拟了軌迹空間的多模态。在MTP方法中,對tj時刻的第i個交通參與者,我們首先通過神經網絡的前向傳播獲得M條輸出軌迹。然後我們通過一個任意軌迹距離公式确定最接近真值軌迹的模态m。
在選擇了最佳的比對模态m後,最終的損失函數可以被定義為如下:
這裡I是一個二進制訓示函數,如果條件c是真的就等于1,否則就為0,是一個分類交叉熵損失,定義為:
α是一個用來權衡兩個損失的超參數。換句話說,我們使最比對的模态m的機率接近1,使其它模态的機率接近0。注意在訓練的過程中,位置的輸出隻更新最優模态,而機率的輸出所有模态都更新。這使得每個模式都專門針對不同類别的參與者行為(例如,直走或者轉彎),這樣就成功地解決了模态崩潰的問題,如接下來的實驗中所示。
圖3:模态選擇方法(模态以藍色表示):使用位移時,真值(綠色)與右轉模态比對,而使用角度時則與直行模态比對
我們實驗了幾種不同的軌迹距離函數。特别是作為第一選項,我們使用的是兩個軌迹之間的平均位移。但是,這個距離函數并不能很好地對十字路口處的多模态行為進行模組化,如圖3所示。為了解決這個問題,我們提出一個通過考慮交通參與者目前位置與真值和預測軌迹最後一個位置之間夾角的測距函數,進而改進了對十字路口場景的處理。第四節給出了定量的比較結果。
最後,對損失(2)和(4)我們訓練卷積神經網絡參數來最小化訓練集上的損失。
注意我們的多模态損失函數是不可知的選擇其中一個模态作損失函數,并且很容易将我們的方法推廣到論文[16]中提出的用負高斯對數似然來預測軌迹點的不确定性。
車道線跟随多模态預測
之前我們描述了一種方法,它可以直接在一個前向傳播過程中預測多個模态。在[21]中,每輛車都與一條車道相關聯(即為車道線跟随車輛),我們提出了一種隐式輸出多條軌迹的方法。特别是,假設我們已知可能跟随的車道線和通過車道線評分系統篩選出不可能跟随的車道線,我們添加了另一個栅格層來編碼此資訊,并訓練網絡輸出車道線跟随軌迹。然後,對于一個場景,我們通過生成多個不同的車道線跟随的栅格圖,可以有效地預測多模态軌迹。為了生成訓練集,我們首先确定車輛實際跟随的車道線并基于此建立輸入栅格圖。然後我們通過設定M=1(ME和MTP在這種情況下是相等的)來使用之前介紹的損失函數來訓練車道線跟随(LF)模型。實際上,LF和其它方法可以被同時使用,分别處理車道線跟随和其它的交通參與者。請注意我們介紹這種方法隻是為了完整性,因為實踐者可能會發現将栅格化想法與現有的車道線跟随方法相結合來獲得多模态預測會很有幫助,如[21]中所述。
圖4. LF模型在同一場景下不同跟随車道線的軌迹輸出示例(淡粉色表示)
在圖4中我們展示了同一個場景的栅格圖,但是使用兩個不同的用淡粉色标記的跟随車道線。一個是直行另一個是左轉。該方法輸出的軌迹很好地遵循了預定的路徑,并可用于對車道線跟随車輛生成多條預測軌迹。
實驗
我們通過手動駕駛在匹茲堡、PA、菲尼克斯、AZ等不同交通條件下(如不同時段、不同天數),收集了240小時的資料。從相機、雷射雷達和超音波雷達擷取原始傳感器資料,使用UKF[40]和運動學模型[41]對j交通參與者進行跟蹤,并以10Hz的速率對每輛跟蹤車輛輸出狀态估計。UKF在大量标記資料上進行了高度優化和訓練,并在大規模真實資料上進行了廣泛測試。每個交通參與者在每個離散時刻的跟蹤時刻相當于一個單一的資料點1,在删除靜态交通參與者後,總體資料有780萬個資料點。我們考慮了6秒的預測時間(即H=60),α=1,并且使用3:1:1的分割比例獲得訓練集、驗證集和測試集。
我們将提出的方法與幾個基線進行比較:
(1)前向UKF實時估計的狀态
(2)單軌迹預測(STP)[16]
(3)高斯混合軌迹空間MDN[35]
模型在TensorFlow[42]上實作,并在16Nvidia Titan X GPU卡上訓練。我們使用開源分布式架構Horovod[43]進行訓練,在24小時内完成。我們設定每個gpu處理的批量數為64,并使用Adam optimizer[44]進行訓練,将初始學習率設定為10-4,每隔2萬次疊代就降低0.9倍。所有的模型都是端到端的訓練,并部署到自動駕駛汽車上,使用GPU執行批量處理,平均時間約為10ms。
實驗結果
我們使用與運動預測相關的誤差度量來比較方法:位移(1),以及沿着和交叉跟蹤的誤差[45]分别測量與真值的縱向和橫向偏差。由于多磨要方法提供了機率,一種可能的評估方法是使用最可能的模态的預測誤差。但是,早期關于多模态預測[31]的研究發現,這種度量名額更傾向于單模态模型,因為他們顯示地優化了平均預測誤差,同時輸出了不真實的軌迹(參看圖1中的示例)。我們從[31]和[37]鏡像現有的設定,過濾掉機率低的軌迹(我們将門檻值設定為0.2),并使用其餘設定的最小誤差模式來計算度量名額。我們發現這種方式計算的結果更加符合自動駕駛汽車上的觀測性能。
表1. 不同方法的預測誤差比較(以米為機關)
在表1中我們給出了預測步長為1s和6s的誤差,一級不同數量的模态M在整個預測步長的平均度量名額(模态數量從2到4)。首先我們可以看到單模态模型(如UKF和STP)顯然不适合進行上時間預測。然而它們在1s的短時預測結果是合理的,6s的預測誤差明顯大于最優多模态方法。這樣的結果是在意料之中的,因為在短期内交通參與者受到實體和它們周圍環境的限制,導緻真值近似單模态分布[16]。另一方面,從長時間的角度來看,預測問題的多模态性變得更加明顯(例如當一個交通參與者接近一個十字路口時,它們在完全相同的場景下可能做出幾種不同的選擇)。單模态預測并沒有很好地考慮這種問題,而是直接預測了一個分布的平均值,如圖1所示。
此外,值得注意的是,對于各種M值,MDN和ME給出的結果與STP相似。原因是衆所周知的模态崩潰問題,其中隻有一個模态提供了非退化預測。是以,在實踐中,一個受影響的多模态方法會退回到單模态,不能完全捕獲多個模态。[37]的作者報告了MDNs的這個問題,并發現多模态假設模型受到的影響較小,我們的實驗結果也進一步證明了這一點。
将我們的重點轉移到MTP方法上,我們觀察到與其他方法相比有了明顯的改進。平均誤差和6s時刻的誤差都全面下降,表明這些方法學習到了交通問題的多模态性。短期1s和長期6s的預測誤差均低于其它方法,即使在長期預測的效果更加明顯。有趣的是,結果表明當M=3時,各項評價名額均達到了最佳。
表2. 對于不同模态在6s時刻的位移誤差
接下來,我們評估了不同的軌迹距離度量,以選擇在MP訓練中的最佳比對模态。表一顯示,使用位移作為距離函數比使用角度的性能稍好。然而,為了更好地了解這種選擇的含義,我們将測試集分為三類:左轉、右轉和直行(測試集中95%的交通參與者大緻是直行,其餘的在轉彎之間平均分布),并在表2中報告了6s預測的結果。我們可以看到,使用角度改善轉彎的處理,以及非常輕微的退化直行情況。這證明了我們的假設,即角度比對政策提高了十字路口的性能,這對自動駕駛汽車的安全性至關重要。考慮到這些結果,在本節的剩餘部分中,我們将使用角度模态比對政策的MTP模型。
圖5. 從左到右分别對應1到4個不同模态對輸出軌迹的影響
在圖5中,當增加模态M的數量時,我們可以看到,當M=1時(即所推斷的軌迹大緻是直線模式和右轉模式的平均值。增加模态的數量到2,我們得到了一個直走和右轉模态的清晰的分離。此外,将M設定為3會出現左轉模态,盡管可能性很低。當我們設定為M=4時,我們發現了一個有趣的結果,直線模态又分成了“快”和“慢”模态,模組化·交通參與者的縱向速度。我們注意到在遠離十字路口的直道上也有同樣的效果,直行模态會分開成幾種不同的速度模态。
圖6. 模态機率校正的分析
最後,我們對預測模态機率的标定進行了分析。特别地,利用測試集,我們計算了預測模态機率和與真值軌迹最比對的模态機率之間的關系。我們根據軌迹的預測機率對其進行了分段,并計算了每個分段的平均模态比對機率。圖6給出了我們使用M=3的結果,而M為其他值的結果與所示類似。我們可以看出,改圖與y=x參考線非常接近,表明預測的機率經過了很好的校準。
由于交通參與者行為固有的不确定性,為了保證在道路上安全高效地行駛,自動駕駛汽車需要考慮周圍交通參與者未來可能的多條軌迹。在這篇論文中,我們解決了自動駕駛問題的這一關鍵方面,并且提出了一種對車輛運動預測的多模态模組化方法。該方法首先生成一個栅格圖編碼交通參與者的周圍環境,并使用一個卷積神經網絡模型輸出幾個可能的預測軌迹及其機率。我們讨論了幾種多模态模型,并與目前最先進的方法進行了比較,結果表明,本文提出的方法具有實際效益。經過大量的離線評估,該方法成功地在自動駕駛汽車上進行了測試。
參考文獻
[1]F.Amato,A.López,E.M.Pe a-Méndez,P. Vaňhara, A.Hampl,and J.Havel,"Artificial neural networks in medical diagnosis,"Jounal of Applied Biomedicine,vol.11,no.2pp.47-582013.
[2]K.Albury,J.Burgess,B.Light,K.Race,and R.Wilken,"Data cultures of mobile dating and hook-up apps: Emerging issues for critical social science research,"Big Data & Society,vol.4,no.2,2017.
[3]I.Katakis,G.Tsoumakas,E.Banos,N. Bassiliades, and I. Vlahavas. An adaptive personalized news dissemination system,Journal of Intelligent Information Systems,vol.32,no.2,pp.191-212,2009[4]Y.N.Harari,"Reboot for the ai revolution," Nature News, vol.550 no.7676,p.324,2017.
[5]A.Lindgren and F.Chen,"State of the art analysis: An overview of advanced driver assistance systems (adas) and possible human factors issues,"Human factors and economics aspects on safety,pp.38-502006.
[8]S.Singh, "Critical reasons for crashes investigated in the national motor vehicle crash causation survey,National Highway Traffic Safety Administration,Tech.Rep.DOT HS 812 115,February 2015.
[9]F.A.Wilson and J.P. Stimpson,“Trends in fatalities from distracted driving in the united states,1999to 2008,American journal of public health,vol.100no11,pp2213-2219,2010.
[12] R. Na t nen and H. Summala,"Road-user behaviour and traffic accidents,Publication of: North-Holland Publishing Company,1976
[13]DA.Pomerleau,Alvinn:An autonomous land vehicle in a neural network,"in Advances in neural information processing systems,1989 pp305-313.
[14] M.Montemerlo,J. BeckerSBhatH.Dahlkamp,D.Dolgov S.EttingerD.HaehnelTHildenGHoffmannB.Huhnke,et al. Junior: The stanford entry in the urban challenge,"Journal offield Robotics,vol25,no9,pp569-597,2008.
15]CUrmson et al."Self-driving cars and the urban challenge"IEEE Intelligent Systemsvol23no.22008.
[16]N.Djuric,V.RadosavljevicH.CuiTNguyen,F.-C.Chou,T-H.Lin and J.Schneider“Short-term motion prediction of traffic actors for autonomous driving using deep convolutional networks,"arXiv preprint arXiv:1808058192018
[18]J.Wiest, Statistical long-term motion prediction. Universit t Ulm 2017.
[19]R.E.KalmanA new approach to linear filtering and prediction problems,"Transactions ofthe ASME-Journal ofBasic Engineering vol.82no.Series Dpp35-451960.
20]ACosgunL.Ma,et al,"Towards full automated drive in urban environments:Ademonstrationin gomentum station,california,"in IEEE Intelligent Vehicles Symposium,2017,pp1811-1818 [Online]Available:https://doiorg/101109/1VS20177995969
[21]J.Ziegler,P.BenderM.Schreiber,et al,“Making bertha drive-an au-tonomous journey on a historic route,"IEEE Intelligent Transportation Systems Magazine,vol6pp8-20102015.
[22] TStreubel and KH.Hoffmann, Prediction of driver intended path at intersections.IEEE,Jun 2014.[Online].Available http://dxdoiorg/10.1109/VS.2014.6856508
[23]M.Schreier, V. Willert, and J.Adamy,“An integrated approach to maneuver-based trajectory prediction and criticality assessment in arbitrary road environments,"IEEE Transactions on Intelligen Transportation Systems,vol17no10p2751-2766Oct 2016[Online].Available:http://dxdoiorg/10.1109/TITS.2016.2522507
[24]J.Wang,D.Fleet,and A.Hertzmann,“Gaussian process dynamical models for human motion,"IEEE Transactions on Pattern Analysis and Machine Intelligence,vol.30,no.2p.283-298Feb2008 [Onlinel.Available:http://dxdoi.org/10.1109/TPAMI.2007.1167
[25]A.Y.Ng and S.Russell,"Algorithms for inverse reinforcement learning, in International Conference on Machine Learning,2000
[26] K.M.Kitani,B.D.Ziebart,J. A.Bagnell, and M.Hebert, Activity Forecasting. Springer Berlin Heidelberg,2012p.201-214.[Online] Available:http://dxdoiorg/10.1007/978-3-642-33765-9_15
[28] A.Alahi,K. Goel, et al. Social LSTM:Human Trajectory Prediction in Crowded Spaces. IEEE,Jun 2016.Online].Availables http://dxdoi.org/10.1109/CVPR.2016.110
[29] A.Gupta,J.Johnson,L.Fei-Fei,S.Savarese,and A.Alahi“Social gan: Sociallyacceptable trajectories with generative adversarial networks, in The IEEE Conference on Computer Vision and Pattern Recognition(CVPR)2018.
[30]B.KimC.M.Kang,S.H.Lee,H.Chae,J.Kim,C.C.Chung,and J.W. Choi,“Probabilistic vehicle trajectory prediction over occupancy grid map via recurrent neural network,"arXiv preprint arXiv:1704.070492017.
[31] N.Lee,W.Choi,P.Vernaza.C.B.Choy,et al,DESIRE:Distant Future Prediction in Dynamic Scenes with Interacting Agents. IEEE,Jul2017.[Online.Available:http://dxdoi.org/10.1109/CVPR.2017.233[32]K.Fragkiadaki,P.Agrawal,et al,"Learning visual predictive models of physics for playing billiards,"in International Conference on Learning Representations(CLR),2016.
[34]F.-C.Chou,T-H.Lin,HCui,V.RadosavljevicT Nguyen,T.-K. Huang.M.Niedoba,J.Schneiderand N.Djuric,“Predicting motion of vulnerable road users using high-definition maps and efficient convnets," in Workshop on 'Machine Learning for Intelligent Transportation Systems’at Conference on Neural Information Processing Systems(MLITS)2018.
[35] C.M.Bishop,“Mixture density networks,"Citeseer,Tech.Rep,1994[36] S.Lee,SPurushwalkam Shiva Prakash,M.Cogswell,V. Ranjan D.Crandall,and D.Batra,“Stochastic multiple choice learning fo training diverse deep ensembles,"in Advances in Neural Information Processing Systems 29,2016,pp.2119-2127.
[37] C.Rupprecht,I.Laina,R.DiPietro,M.Baust,F.Tombari,N. Navab and G. D. Hager, "Learning in an uncertain world: Representing ambiguity through multiple hypotheses,"in Proceedings ofthe lEEE International Conference on Computer Vision,2017pp.3591-3600[38]N.Deo and M.M.Trivedi,"Multi-modal trajectory prediction osurrounding vehicles with maneuver based lstms,"arXiv preprint arXiv:1805.054992018.
[39] M.Sandler,A.Howard,M.Zhu,A.Zhmoginov,and L.-C.Chen Invertedresiduals and linear bottlenecks:Mobile networks for classifi cation, detection and segmentation,"arXivpreprint arXiv:1801.043812018.
[40] E.A.Wan and R.Van Der Merwe,"The unscented kalman filter for nonlinear estimation,"in Adaptive Systems for Signal Processing Communications, and Control Symposium2000.AS-spcc.The IEEE2000. eee,2000,pp.153-158.
[41]J.Kong,M.Pfeiffer,G.Schildbach,and F.Borrelli,"Kinematic and dynamic vehicle models for autonomous driving control design,"in Intelligent Vehicles Symposium(IV),2015 IEEE. IEEE,2015,Pp1094-1099.
[42] M.Abadi,A.Agarwal,P.BarhamE.Brevdo,et al,“TensorFlow Large-scale machine learning on heterogeneous systems"2015 [Online].Available:https://www.tensorfloworg/
[43] A.Sergeev and M.D.Balso,“Horovod: fast and easy distributed deep learning in tensorflow,"arXiv preprint arXiv:1802.05799,2018.
[44]D.P.Kingma and J.Ba“Adam:A method for stochastic optimization, arXiv preprint arXiv:1412.6980,2014.
[45]C.Gong and D.McNally,A methodology for automated trajectory prediction analysis,"in AIAA Guidance, Navigation, and Control Conference and Exhibit,2004.
轉載自網絡,文中觀點僅供分享交流,不代表本公衆号立場,如涉及版權等問題,請您告知,我們将及時處理。
-- END --