使用循環圖神經網絡完成斯坦福 CS224W 課程的Wikispeedia項目
介紹
在這篇文章中,我們将使用現代的圖機器學習技術在 Wikispeedia navigation paths路徑資料集進行項目實踐
West & Leskovec 之前在沒有使用圖神經網絡 [1] 的情況下解決了類似的問題。 Cordonnier & Loukas 還使用 Wikispeedia 圖[2] 上的非回溯随機遊走的圖卷積網絡解決了這個問題。 我們的技術與這兩篇論文都不同并且也取得了很好的效果。
在文章的最後還會提供 GitHub和Colab 的完整代碼。
資料+問題描述
我們的資料來自斯坦福網絡分析項目 (SNAP) 的資料集集合。 該資料集擷取了由 Wikispeedia 的玩家收集的 Wikipedia 超連結網絡上的導航路徑資料。 Wikispeedia是一個更多的被稱為 Wikiracing 的益智小遊戲,目的是機器自動學習常識知識。 遊戲規則很簡單——玩家在比賽中選擇兩個不同的維基百科文章,目标是在隻點選第一篇文章提供的連結的情況下到達第二篇文章并且越快越好。
那麼我們的任務是什麼? 鑒于成千上萬的使用者在玩 Wikispeedia 建立的 Wikipedia 頁面路徑,如果我們知道使用者到目前為止通路的頁面順序,我們是否可以預測玩家的目标文章? 我們可以使用圖神經網絡提供的表達能力來做到這一點嗎?
資料預處理
準備用于圖機器學習的資料集需要大量的預處理。第一個目标是将資料表示為一個有向圖,其中維基百科文章作為節點,連接配接文章的超連結作為邊。這一步可以使用 NetworkX,一個 Python 網絡分析庫,以及 Cordonnier & Loukas [2] 之前的工作。因為Cordonnier & Loukas 已經在使用圖形模組化語言 (GML) 處理并編碼了了來自 SNAP 資料集的超連結圖結構檔案,我們可以輕松地将其導入 NetworkX。
下一個目标是處理來自 Cordonnier & Loukas 和原始 SNAP 資料集的資料,這樣可以為 NetworkX 圖中的每篇文章添加節點級屬性。對于每個節點,我們希望包含頁面的入度和出度以及文章内容,是以這裡使用了文章中每個單詞對應的 FastText 預訓練詞嵌入的平均值表示。Cordonnier & Loukas處理并編碼了每個頁面的度和文本檔案中相應的内容嵌入。此外,我們還将每篇文章進行了層次分類的(例如,“貓”頁面分類在科學 > 生物學 > 哺乳動物下)并添加到其相應的節點,是以在處理時使用 Pandas 以解析制表符分隔并為每篇文章生成一個多分類的變量來表示該文章屬于哪些類别。然後再通過使用 set_node_attributes 方法,新的文章屬性添加到 NetworkX 圖中的每個相應節點。
import networkx as nx
# read our graph from file
our_graph = nx.read_gml('graph.gml')
# define our new node attributes
attrs = { "Cat": { "in_degree": 31 }, "New_York_City": { "in_degree": 317 } }
# add our new attributes to the graph
nx.set_node_attributes(our_graph, attrs) NetworkX圖表已經準備完畢可以加載并準備運作了!但是,還需要處理和定義輸入資料和标簽——即導航路徑和目标文章。與前面類似,使用Pandas解析SNAP資料集中已完成的導航路徑的制表符分隔值,然後處理每個導航路徑以删除傳回的點選(由Wikispeedia玩家建立的導航從目前頁面傳回到之前直接通路的頁面),并删除每個路徑中的最後一篇文章(我們的目标文章)。為了清洗資料,還删除了超過32個超連結點選長度的導航路徑,并将每個導航路徑填充為32個長度。
這樣得到了超過50000條導航路徑連接配接在4000多篇不同的維基百科文章的已經經過處理的資料集。
WikiNet模型架構
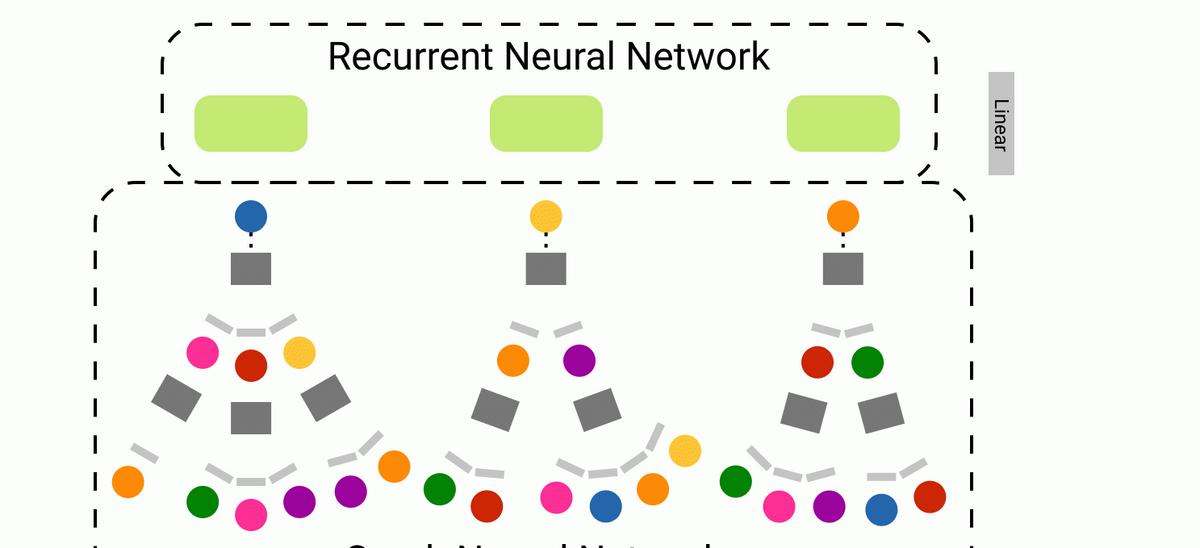
我們的新方法試圖将遞歸神經網絡 (RNN) 捕獲序列知識的能力與圖神經網絡 (GNN) 表達圖網絡結構的能力相結合。 以上就是WikiNet——一種 RNN-GNN 混合體。
import torch
import torch.nn as nn
from torch_geometric.nn import GCN # import any GNN -- we'll use GCN in this example
from torch_geometric.utils import from_networkx
# convert our networkx graph into a PyTorch Geometric (PyG) graph
pyg_graph = from_networkx(networkx_graph, group_node_attrs=NODE_ATTRIBUTE_NAMES)
# define our PyTorch model class
class Model(torch.nn.Module):
def __init__(self, pyg_graph):
super().__init__()
self.graphX = pyg_graph.x
self.graphEdgeIndex = pyg_graph.edge_index
self.gnn = GCN(in_channels=NODE_FEATURE_SIZE,
hidden_channels=GNN_HIDDEN_SIZE,
num_layers=NUM_GNN_LAYERS,
out_channels=NODE_EMBED_SIZE)
self.batch_norm_lstm = nn.BatchNorm1d(SEQUENCE_PATH_LENGTH)
self.batch_norm_linear = nn.BatchNorm1d(LSTM_HIDDEN_SIZE)
self.lstm = nn.LSTM(input_size=NODE_EMBED_SIZE,
hidden_size=LSTM_HIDDEN_SIZE,
batch_first=True)
self.pred_head = nn.Linear(LSTM_HIDDEN_SIZE, NUM_GRAPH_NODES)
def forward(self, indices):
node_emb = self.gnn(self.graphX, self.graphEdgeIndex)
node_emb_with_padding = torch.cat([node_emb, torch.zeros((1, NODE_EMBED_SIZE))])
paths = node_emb_with_padding[indices]
paths = self.batch_norm_lstm(paths)
_, (h_n, _) = self.lstm(paths)
h_n = self.batch_norm_linear(torch.squeeze(h_n))
predictions = self.pred_head(h_n)
return F.log_softmax(predictions, dim=1) 作為模型輸入,WikiNet 接收一批頁面導航路徑。這表示為一系列節點索引。每個導航路徑都被填充到 32 的長度——用索引 -1 的序列開始填充短序列。然後使用圖神經網絡擷取現有的節點屬性并為超連結圖中的每個 Wikipedia 頁面生成大小為 64 的節點嵌入。使用 0 的張量作為缺失節點的節點嵌入(例如:那些由索引 -1 表示的填充“節點”)。
在調用節點嵌入序列之後将此張量輸入BN層以穩定訓練。然後将張量輸入RNN——在我們的例子中是LSTM模型。在将張量發送到最終線性層之前,還會有一個BN層應用于 RNN 的輸出。最後的線性層将 RNN 輸出投影到 4064 個類中的一個——最終目标的wiki頁面。最後就是對輸出應用 log softmax 函數生成機率。
WikiNet 圖神經網絡變體
WikiNet 實驗中用于生成節點嵌入有三種圖神經網絡風格——圖卷積網絡、圖注意力網絡和 GraphSAGE。
首先讨論一下圖神經網絡的一般功能,在圖神經網絡中,關鍵思想是根據每個節點的局部鄰域為每個節點生成節點嵌入。 也就是說,我們可以将資訊從其相鄰節點傳播到每個節點。

上圖表示輸入圖的計算圖。 x_u 表示給定節點 u 的特征。 這是一個有 2 層的簡單示例,盡管 GNN 計算圖可以是任意深度。 我們将節點 u 在第 n 層的輸出稱為節點 u 的“第 n 層嵌入”。
在第 0 層,每個節點的嵌入由它們的初始節點特征 x 給出。 在高層上,通過聚合來自每個節點的鄰居集的第 k 層嵌入,從第(k-1)層嵌入生成第 k 層嵌入。 這激發了每個 GNN 層的兩步過程:
- 消息計算
- 聚合
在消息計算中,通過“消息函數”傳遞節點的第 k 層嵌入。 在聚合中使用“聚合函數”聚合來自節點鄰居以及節點本身的消息。 更具體地說:
圖卷積神經網絡 (GCN)
一種簡單直覺的消息計算方法是使用神經網絡。 對于聚合可以簡單地取鄰居節點消息的平均值。 在 GCN 中還将使用偏置項來聚合來自前一層的節點本身的嵌入。 最後通過激活函數(例如 ReLU)傳遞這個輸出。 是以,方程看起來像這樣:
可以訓練參數矩陣W_k和B_k作為機器學習管道的一部分。[3]
GraphSAGE
GraphSAGE與GCN在幾個方面有所不同。在這個模型中,消息是在聚合函數中計算的,聚合函數由兩個階段組成。首先在節點的鄰居上進行聚合——在本例中使用平均聚合。然後通過連接配接節點的前一層嵌入對節點本身進行聚合。這個連接配接乘以一個權重矩陣W_k,然後通過一個激活函數來獲得輸出[4]。計算層-(k+1)嵌入的總體方程如下:
圖注意網絡(GAT)
GAT出現的理論基礎是并非所有鄰居節點都具有同等的重要性。GAT類似于GCN,但不是簡單的平均聚合,而是使用注意力權值[5]對節點進行權重。也就是說,更新規則如下:
可以看到GCN的更新規則和GAT的更新規則是一樣的,其中:
與權值矩陣不同注意權值不是每一層唯一的。為了計算這些注意力權重,首先要計算注意力系數。對于每個節點v和鄰居u,其系數計算如下:
然後使用softmax函數來計算最終的注意力權重,確定權重之和為1:
這樣就可以通過權值矩陣來訓練注意力權重。
訓練參數
為了訓練我們的模型,我們根據90/5/5%的分割随機地将我們的資料集分成訓練、驗證和測試資料集。使用Adam算法作為訓練優化器,負對數似然作為我們的損失函數。我們使用了以下超參數:
實驗結果
我們評估了WikiNet的三個GNN變量對目标文章預測精度的影響。這類似于Cordonnier & Loukas[2]使用的precision@1度量。每個GNN-RNN混合模型在目标文章預測上的絕對精度都比在節點特征上運作的純LSTM基線高出3%至10%。使用GraphSAGE作為模型的GNN變體的最高準确率為36.7%。圖神經網絡捕獲和編碼維基百科頁面的局部鄰域結構資訊的能力似乎比單獨的導航路徑序列在目标文章預測方面有更大的性能。
引用
[1] West, R. & Leskovec, J. Human Wayfinding in Information Networks (2012), WWW 2012 — Session: Web User Behavioral Analysis and Modeling
[2] Cordonnier, J.B. & Loukas, A. Extrapolating paths with graph neural networks (2019).
[3] Kipf, T.N. & Welling, M. Semi-Supervised Classification with Graph Convolutional Networks (2017).
[4] Hamilton, W.L. & Ying, R. & Leskovec, J. Inductive Representation Learning on Large Graphs (2018).
[5] Veličković, P. et al. Graph Attention Networks (2018).
作者:Alexander Hurtado