前言
近來想寫一個mybatis的分頁插件,但是在寫插件之前肯定要了解一下mybatis具體的工作原理吧,于是邊參考别人的部落格,邊看源碼就開幹了。
核心部件:
-
SqlSession
Executor
StatementHandler
ParameterHandler
ResultSetHandler
TypeHandler
MappedStatement
Configuration
在分析工作原理之前,首先看一下我的mybatis全局配置檔案
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 和spring整合後 environments配置将廢除 -->
<environments default="development">
<environment id="development">
<!-- 使用jdbc事務管理 -->
<transactionManager type="JDBC" />
<!-- 資料庫連接配接池 -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url"
value="jdbc:mysql://localhost:3306/test?characterEncoding=utf-8" />
<property name="username" value="root" />
<property name="password" value="123456" />
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="sqlMapper/userMapper.xml"/>
</mappers>
</configuration>
第一步:建立一個sqlSessionFactory
在了解如何建立sqlSessionFactory之前,先看一下mybatis是如何加載全局配置檔案,解析xml檔案生成Configuration的
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
private void parseConfiguration(XNode root) {
try {
propertiesElement(root.evalNode("properties")); //issue #117 read properties first
typeAliasesElement(root.evalNode("typeAliases"));
pluginElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
settingsElement(root.evalNode("settings"));
environmentsElement(root.evalNode("environments")); // read it after objectFactory and objectWrapperFactory issue #631
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
在上面的第二段代碼中有一句
mapperElement(root.evalNode("mappers"));
剛好我們的全局配置檔案中有一個mapper的配置,由此可見,mapperElemet()方法是解析mapper映射檔案的,具體代碼如下
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {//進入該判斷
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
根據以上代碼可以分析,在寫mapper映射檔案的位址時不僅可以寫成resource,還可以寫成url和mapperClass的形式,由于我們用的是resource,是以直接進入第一個判斷,最後解析mapper映射檔案的方法是
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. Cause: " + e, e);
}
}
其中具體解析每一個sql語句節點的是
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
進入這個方法一層層深究,最後到這裡可以知道MappedStatement是由builderAssistant(即MapperBuildAssistant)建立的。
public void parseStatementNode() {
...
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
最後進入方法addMappedStatement(),mappedStatement最後以id為鍵儲存在了Configuration中的一個map變量mappedStatements中。
public MappedStatement addMappedStatement(
String id,
SqlSource sqlSource,
StatementType statementType,
SqlCommandType sqlCommandType,
Integer fetchSize,
Integer timeout,
String parameterMap,
Class<?> parameterType,
String resultMap,
Class<?> resultType,
ResultSetType resultSetType,
boolean flushCache,
boolean useCache,
boolean resultOrdered,
KeyGenerator keyGenerator,
String keyProperty,
String keyColumn,
String databaseId,
LanguageDriver lang,
String resultSets) {
if (unresolvedCacheRef) throw new IncompleteElementException("Cache-ref not yet resolved");
id = applyCurrentNamespace(id, false);
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType);
statementBuilder.resource(resource);
statementBuilder.fetchSize(fetchSize);
statementBuilder.statementType(statementType);
statementBuilder.keyGenerator(keyGenerator);
statementBuilder.keyProperty(keyProperty);
statementBuilder.keyColumn(keyColumn);
statementBuilder.databaseId(databaseId);
statementBuilder.lang(lang);
statementBuilder.resultOrdered(resultOrdered);
statementBuilder.resulSets(resultSets);
setStatementTimeout(timeout, statementBuilder);
setStatementParameterMap(parameterMap, parameterType, statementBuilder);
setStatementResultMap(resultMap, resultType, resultSetType, statementBuilder);
setStatementCache(isSelect, flushCache, useCache, currentCache, statementBuilder);
MappedStatement statement = statementBuilder.build();
configuration.addMappedStatement(statement);
return statement;
}
最後回到我們的建立sqlSessionFactory上,之前的一切都是為了生成一個sqlSessionFactory服務的
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
從上面的代碼可以看出最後是通過以Configuration為參數build()方法生成DefautSqlSessionFactory。
第二步:建立sqlSession
public SqlSession openSession() {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
//傳回一個SqlSession,預設使用DefaultSqlSession
public DefaultSqlSession(Configuration configuration, Executor executor, boolean autoCommit) {
this.configuration = configuration;
this.executor = executor;
this.dirty = false;
this.autoCommit = autoCommit;
}
executor在這一步得到建立,具體的使用在下一步。
第三步:執行具體的sql請求
在我的代碼裡執行的是
User user = sqlSession.selectOne("test.findUserById", 1);
具體到裡面的方法就是
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//1.根據Statement Id,在mybatis 配置對象Configuration中查找和配置檔案相對應的MappedStatement
MappedStatement ms = configuration.getMappedStatement(statement);
//2. 将查詢任務委托給MyBatis 的執行器 Executor
List<E> result = executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
return result;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
在這裡通過statementId拿到了我們在第一步存在map裡面的MappedStatement。在這裡引用參考部落格的一句話:
SqlSession根據Statement ID, 在mybatis配置對象Configuration中擷取到對應的MappedStatement對象,然後調用mybatis執行器來執行具體的操作。
再繼續看query()和queryFromDatabase()這兩個方法
@SuppressWarnings("unchecked")
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) throw new ExecutorException("Executor was closed.");
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear(); // issue #601
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache(); // issue #482
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
在這兩個方法裡面會為目前的查詢建立一個緩存key,如果緩存中沒有值,直接從資料庫中讀取,執行查詢後将得到的list結果放入緩存之中。
緊接着看doQuery()在SimpleExecutor類中重寫的方法
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
Statement連接配接對象就是在這裡建立的,是以Executor的作用之一就是建立Statement了,建立完後又把Statement丢給StatementHandler傳回List查詢結果。
接下來再看一下這裡的兩個方法prepareStatement()和query()的具體實作
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection);
handler.parameterize(stmt);
return stmt;
}
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.<E> handleResultSets(ps);
}
prepareStatement()是建立Statement的具體實作方法,調用parameterize()對建立的Statement對象設定參數,即為我們設為占位符的地方賦上指定的參數,parameterize()方法再深入進去就是調用ParameterHandler的setParameters()方法具體指派了。
歡迎大家關注我的公種浩【程式員追風】,文章都會在裡面更新,整理的資料也會放在裡面。
這裡的query()是調用了ResultSetHandler的handleResultSets(Statement) 方法。作用就是把ResultSet結果集對象轉換成List類型的集合。
總結以上步驟就是:
根據具體傳入的參數,動态地生成需要執行的SQL語句,用BoundSql對象表示
為目前的查詢建立一個緩存Key
緩存中沒有值,直接從資料庫中讀取資料
執行查詢,傳回List 結果,然後 将查詢的結果放入緩存之中
根據既有的參數,建立StatementHandler對象來執行查詢操作
将建立Statement傳遞給StatementHandler對象,調用parameterize()方法指派
調用StatementHandler.query()方法,傳回List結果集
總結
以上三個步驟所有流程大體可以用一張圖來總結
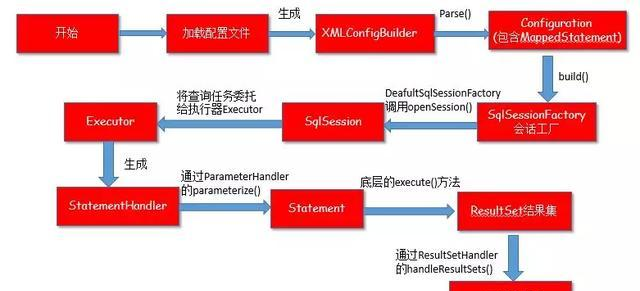
最後
歡迎大家一起交流,喜歡文章記得點個贊喲,感謝支援!
![Java String.format方法的簡單使用[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)