DLedger 基于 raft 協定,故天然支援主從切換,即主節點(Leader)發生故障,會重新觸發選主,在叢集内再選舉出新的主節點。
RocketMQ 中主從同步,從節點不僅會從主節點同步資料,也會同步中繼資料,包含 topic 路由資訊、消費進度、延遲隊列處理隊列、消費組訂閱配置等資訊。那主從切換後中繼資料如何同步呢?特别是主從切換過程中,對消息消費有多大的影響,會丢失消息嗎?
溫馨提示:本文假設大家已經對 RocketMQ4.5 版本之前的主從同步實作有一定的了解,這部分内容在《RocketMQ技術内幕》一書中有詳細的介紹,大家也可以參考如下兩篇文章:
1、
RocketMQ HA機制(主從同步)。
2、
RocketMQ 整合 DLedger(多副本)即主從切換實作平滑更新的設計技巧
1、BrokerController 中與主從相關的方法詳解
本節先對 BrokerController 中與主從切換相關的方法。
1.1 startProcessorByHa
BrokerController#startProcessorByHa
private void startProcessorByHa(BrokerRole role) {
if (BrokerRole.SLAVE != role) {
if (this.transactionalMessageCheckService != null) {
this.transactionalMessageCheckService.start();
}
}
} 感覺該方法的取名較為随意,該方法的作用是開啟事務狀态回查處理器,即當節點為主節點時,開啟對應的事務狀态回查處理器,對PREPARE狀态的消息發起事務狀态回查請求。
1.2 shutdownProcessorByHa
BrokerController#shutdownProcessorByHa
private void shutdownProcessorByHa() {
if (this.transactionalMessageCheckService != null) {
this.transactionalMessageCheckService.shutdown(true);
}
} 關閉事務狀态回查處理器,當節點從主節點變更為從節點後,該方法被調用。
1.3 handleSlaveSynchronize
BrokerController#handleSlaveSynchronize
private void handleSlaveSynchronize(BrokerRole role) {
if (role == BrokerRole.SLAVE) { // @1
if (null != slaveSyncFuture) {
slaveSyncFuture.cancel(false);
}
this.slaveSynchronize.setMasterAddr(null); //
slaveSyncFuture = this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
BrokerController.this.slaveSynchronize.syncAll();
} catch (Throwable e) {
log.error("ScheduledTask SlaveSynchronize syncAll error.", e);
}
}
}, 1000 * 3, 1000 * 10, TimeUnit.MILLISECONDS);
} else { // @2
//handle the slave synchronise
if (null != slaveSyncFuture) {
slaveSyncFuture.cancel(false);
}
this.slaveSynchronize.setMasterAddr(null);
}
} 該方法的主要作用是處理從節點的中繼資料同步,即從節點向主節點主動同步 topic 的路由資訊、消費進度、延遲隊列處理隊列、消費組訂閱配置等資訊。
代碼@1:如果目前節點的角色為從節點:
- 如果上次同步的 future 不為空,則首先先取消。
- 然後設定 slaveSynchronize 的 master 位址為空。不知大家是否與筆者一樣,有一個疑問,從節點的時候,如果将 master 位址設定為空,那如何同步中繼資料,那這個值會在什麼時候設定呢?
- 開啟定時同步任務,每 10s 從主節點同步一次中繼資料。
代碼@2:如果目前節點的角色為主節點,則取消定時同步任務并設定 master 的位址為空。
1.4 changeToSlave
BrokerController#changeToSlave
public void changeToSlave(int brokerId) {
log.info("Begin to change to slave brokerName={} brokerId={}", brokerConfig.getBrokerName(), brokerId);
//change the role
brokerConfig.setBrokerId(brokerId == 0 ? 1 : brokerId); //TO DO check // @1
messageStoreConfig.setBrokerRole(BrokerRole.SLAVE); // @2
//handle the scheduled service
try {
this.messageStore.handleScheduleMessageService(BrokerRole.SLAVE); // @3
} catch (Throwable t) {
log.error("[MONITOR] handleScheduleMessageService failed when changing to slave", t);
}
//handle the transactional service
try {
this.shutdownProcessorByHa(); // @4
} catch (Throwable t) {
log.error("[MONITOR] shutdownProcessorByHa failed when changing to slave", t);
}
//handle the slave synchronise
handleSlaveSynchronize(BrokerRole.SLAVE); // @5
try {
this.registerBrokerAll(true, true, brokerConfig.isForceRegister()); // @6
} catch (Throwable ignored) {
}
log.info("Finish to change to slave brokerName={} brokerId={}", brokerConfig.getBrokerName(), brokerId);
} Broker 狀态變更為從節點。其關鍵實作如下:
- 設定 brokerId,如果broker的id為0,則設定為1,這裡在使用的時候,注意規劃好叢集内節點的 brokerId。
- 設定 broker 的狀态為 BrokerRole.SLAVE。
- 如果是從節點,則關閉定時排程線程(處理 RocketMQ 延遲隊列),如果是主節點,則啟動該線程。
- 關閉事務狀态回查處理器。
- 從節點需要啟動中繼資料同步處理器,即啟動 SlaveSynchronize 定時從主伺服器同步中繼資料。
- 立即向叢集内所有的 nameserver 告知 broker 資訊狀态的變更。
1.5 changeToMaster
BrokerController#changeToMaster
public void changeToMaster(BrokerRole role) {
if (role == BrokerRole.SLAVE) {
return;
}
log.info("Begin to change to master brokerName={}", brokerConfig.getBrokerName());
//handle the slave synchronise
handleSlaveSynchronize(role); // @1
//handle the scheduled service
try {
this.messageStore.handleScheduleMessageService(role); // @2
} catch (Throwable t) {
log.error("[MONITOR] handleScheduleMessageService failed when changing to master", t);
}
//handle the transactional service
try {
this.startProcessorByHa(BrokerRole.SYNC_MASTER); // @3
} catch (Throwable t) {
log.error("[MONITOR] startProcessorByHa failed when changing to master", t);
}
//if the operations above are totally successful, we change to master
brokerConfig.setBrokerId(0); //TO DO check // @4
messageStoreConfig.setBrokerRole(role);
try {
this.registerBrokerAll(true, true, brokerConfig.isForceRegister()); // @5
} catch (Throwable ignored) {
}
log.info("Finish to change to master brokerName={}", brokerConfig.getBrokerName());
} 該方法是 Broker 角色從從節點變更為主節點的處理邏輯,其實作要點如下:
- 關閉中繼資料同步器,因為主節點無需同步。
- 開啟定時任務處理線程。
- 開啟事務狀态回查處理線程。
- 設定 brokerId 為 0。
- 向 nameserver 立即發送心跳包以便告知 broker 伺服器目前最新的狀态。
主從節點狀态變更的核心方法就介紹到這裡了,接下來看看如何觸發主從切換。
2、如何觸發主從切換
從前面的文章我們可以得知,RocketMQ DLedger 是基于 raft 協定實作的,在該協定中就實作了主節點的選舉與主節點失效後叢集會自動進行重新選舉,經過協商投票産生新的主節點,進而實作高可用。
BrokerController#initialize
if (messageStoreConfig.isEnableDLegerCommitLog()) {
DLedgerRoleChangeHandler roleChangeHandler = new DLedgerRoleChangeHandler(this, (DefaultMessageStore) messageStore);
((DLedgerCommitLog)((DefaultMessageStore) messageStore).getCommitLog()).getdLedgerServer().getdLedgerLeaderElector().addRoleChangeHandler(roleChangeHandler);
} 上述代碼片段截取自 BrokerController 的 initialize 方法,我們可以得知在 Broker 啟動時,如果開啟了 多副本機制,即 enableDLedgerCommitLog 參數設定為 true,會為 叢集節點選主器添加 roleChangeHandler 事件處理器,即節點發送變更後的事件處理器。
接下來我們将重點探讨 DLedgerRoleChangeHandler 。
2.1 類圖
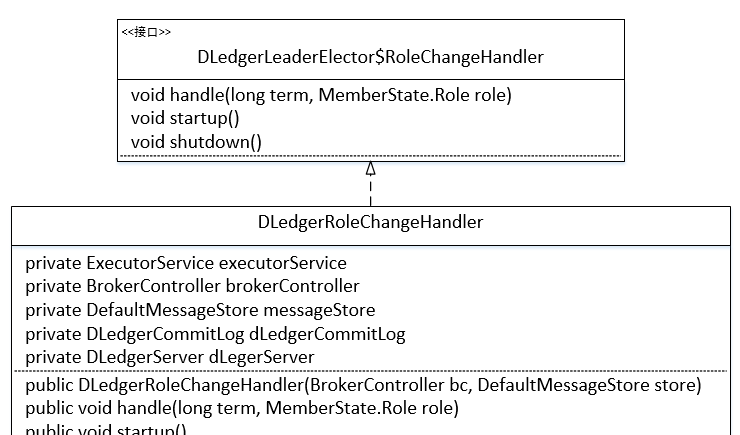
DLedgerRoleChangeHandler 繼承自 RoleChangeHandler,即節點狀态發生變更後的事件處理器。上述的屬性都很簡單,在這裡就重點介紹一下 ExecutorService executorService,事件處理線程池,但隻會開啟一個線程,故事件将一個一個按順序執行。
接下來我們來重點看一下 handle 方法的執行。
2.2 handle 主從狀态切換處理邏輯
DLedgerRoleChangeHandler#handle
public void handle(long term, MemberState.Role role) {
Runnable runnable = new Runnable() {
public void run() {
long start = System.currentTimeMillis();
try {
boolean succ = true;
log.info("Begin handling broker role change term={} role={} currStoreRole={}", term, role, messageStore.getMessageStoreConfig().getBrokerRole());
switch (role) {
case CANDIDATE: // @1
if (messageStore.getMessageStoreConfig().getBrokerRole() != BrokerRole.SLAVE) {
brokerController.changeToSlave(dLedgerCommitLog.getId());
}
break;
case FOLLOWER: // @2
brokerController.changeToSlave(dLedgerCommitLog.getId());
break;
case LEADER: // @3
while (true) {
if (!dLegerServer.getMemberState().isLeader()) {
succ = false;
break;
}
if (dLegerServer.getdLedgerStore().getLedgerEndIndex() == -1) {
break;
}
if (dLegerServer.getdLedgerStore().getLedgerEndIndex() == dLegerServer.getdLedgerStore().getCommittedIndex()
&& messageStore.dispatchBehindBytes() == 0) {
break;
}
Thread.sleep(100);
}
if (succ) {
messageStore.recoverTopicQueueTable();
brokerController.changeToMaster(BrokerRole.SYNC_MASTER);
}
break;
default:
break;
}
log.info("Finish handling broker role change succ={} term={} role={} currStoreRole={} cost={}", succ, term, role, messageStore.getMessageStoreConfig().getBrokerRole(), DLedgerUtils.elapsed(start));
} catch (Throwable t) {
log.info("[MONITOR]Failed handling broker role change term={} role={} currStoreRole={} cost={}", term, role, messageStore.getMessageStoreConfig().getBrokerRole(), DLedgerUtils.elapsed(start), t);
}
}
};
executorService.submit(runnable);
} 代碼@1:如果目前節點狀态機狀态為 CANDIDATE,表示正在發起 Leader 節點,如果該伺服器的角色不是 SLAVE 的話,需要将狀态切換為 SLAVE。
代碼@2:如果目前節點狀态機狀态為 FOLLOWER,broker 節點将轉換為 從節點。
代碼@3:如果目前節點狀态機狀态為 Leader,說明該節點被選舉為 Leader,在切換到 Master 節點之前,首先需要等待目前節點追加的資料都已經被送出後才可以将狀态變更為 Master,其關鍵實作如下:
- 如果 ledgerEndIndex 為 -1,表示目前節點還未又資料轉發,直接跳出循環,無需等待。
- 如果 ledgerEndIndex 不為 -1 ,則必須等待資料都已送出,即 ledgerEndIndex 與 committedIndex 相等。
- 并且需要等待 commitlog 日志全部已轉發到 consumequeue中,即 ReputMessageService 中的 reputFromOffset 與 commitlog 的 maxOffset 相等。
等待上述條件滿足後,即可以進行狀态的變更,需要恢複 ConsumeQueue,維護每一個 queue 對應的 maxOffset,然後将 broker 角色轉變為 master。
經過上面的步驟,就能實時完成 broker 主節點的自動切換。由于單從代碼的角度來看主從切換不夠直覺,下面我将給出主從切換的流程圖。
2.3 主從切換流程圖
由于從源碼的角度或許不夠直覺,故本節給出其流程圖。
溫馨提示:該流程圖的前半部分在 源碼分析 RocketMQ 整合 DLedger(多副本)實作平滑更新的設計技巧 該文中有所闡述。

3、主從切換若幹問題思考
我相信經過上面的講解,大家應該對主從切換的實作原理有了一個比較清晰的了解,我更相信讀者朋友們會抛出一個疑問,主從切換會不會丢失消息,消息消費進度是否會丢失而導緻重複消費呢?
3.1 消息消費進度是否存在丢失風險
首先,由于 RocketMQ 中繼資料,當然也包含消息消費進度的同步是采用的從伺服器定時向主伺服器拉取進行更新,存在時延,引入 DLedger 機制,也并不保證其一緻性,DLedger 隻保證 commitlog 檔案的一緻性。
當主節點當機後,各個從節點并不會完成同步了消息消費進度,于此同時,消息消費繼續,此時消費者會繼續從從節點拉取消息進行消費,但彙報的從節點并不一定會成為新的主節點,故消費進度在 broker 端存在丢失的可能性。當然并不是一定會丢失,因為消息消費端隻要不重新開機,消息消費進度會存儲在記憶體中。
綜合所述,消息消費進度在 broker 端會有丢失的可能性,存在重複消費的可能性,不過問題不大,因為 RocketMQ 本身也不承若不會重複消費。
3.2 消息是否存在丢失風險
消息會不會丢失的關鍵在于,日志複制進度較慢的從節點是否可以被選舉為主節點,如果在一個叢集中,從節點的複制進度落後與從主節點,但當主節點當機後,如果該從節點被選舉成為新的主節點,那這将是一個災難,将會丢失資料。關于一個節點是否給另外一個節點投贊成票的邏輯在
源碼分析 RocketMQ DLedger 多副本之 Leader 選主的 2.4.2 handleVote 方法中已詳細介紹,在這裡我以截圖的方式再展示其核心點:
從上面可以得知,如果發起投票節點的複制進度比自己小的話,會投拒絕票。其
必須得到叢集内超過半數節點認可,即最終選舉出來的主節點的目前複制進度一定是比絕大多數的從節點要大,并且也會等于承偌給用戶端的已送出偏移量。故得出的結論是不會丢消息。
本文的介紹就到此為止了,最後抛出一個思考題與大家互相交流學習,也算是對 DLedger 多副本即主從切換一個總結回顧。答案我會以留言的方式或在下一篇文章中給出。
4、思考題
例如一個叢集内有5個節點的 DLedgr 叢集。
Leader Node: n0-broker-a
folloer Node: n1-broker-a,n2-broker-a,n3-broker-a,n4-broker-a
從節點的複制進度可能不一緻,例如:
n1-broker-a複制進度為 100
n2-broker-a複制進度為 120
n3-broker-a複制進度為 90
n4-broker-a負載進度為 90
如果此時 n0-broker-a 節點當機,觸發選主,如果 n1率先發起投票,由于 n1,的複制進度大于 n3,n4,再加上自己一票,是有可能成為leader的,此時消息會丢失嗎?為什麼?
原文釋出時間為:2019-10-04
本文作者:丁威,《RocketMQ技術内幕》作者。
本文來自
中間件興趣圈,了解相關資訊可以關注