對于大多數深度學習實踐者來說,序列模組化與循環網絡是同義詞。然而,最近的研究結果表明,卷積架構在語音合成和機器翻譯等任務上的表現優于循環網絡。給定一個新的序列模組化任務或資料集,應該使用哪種架構?我們對序列模組化的一般卷積和循環架構進行了系統的評價。我們在廣泛的标準任務中評估這些模型。我們的結果表明,一個簡單的卷積架構在不同的任務和資料集上的表現優于LSTM等典型的循環網絡。我們的結論是,需要重新考慮序列模組化和循環網絡之間的共同關聯,卷積網絡應該被視為序列模組化任務的一個自然起點我們提供了相關代碼:
http://github.com/locuslab/TCN。
總結本文的作者質疑了一個常見假設,即循環架構應該是序列模組化任務的預設起點。他們的結果表明,
時間卷積網絡(TCN)在多個序列模組化任務中明顯優于長短期記憶網絡(LSTMs)和門控循環單元網絡等典型的循環架構。
論文的核心思想是什麼?1、時間卷積網絡(TCN)是基于最近提出的最佳實踐(如擴張卷積和殘差連接配接)設計的,它在一系列複雜的序列模組化任務中表現得明顯優于通用的循環架構。
2、TCN表現出比循環架構更長的記憶,是以更适合需要較長的曆史記錄的任務。
關鍵成就是什麼?·
在序列模組化任務上提供了卷積架構和循環體系結構系統的比較。
設計了卷積體系結構,它可以作為序列模組化任務的友善且強大的起點。
AI 社群的對其評價?在使用RNN之前,一定要先從CNN開始。
未來的研究領域是什麼?為了提高TCN在不同序列模組化任務中的性能,需要進一步精化架構和算法。
可能應用的商業領域?引入TCN可以提高依賴于循環架構進行序列模組化的AI系統的性能。其中包括以下任務:
§機器翻譯;
§語音識别;
§音樂和語音生成。
你在哪裡可以得到代碼?1ã如論文摘要所述,研究人員
通過GitHub存儲庫提供了
官方代碼2、你還可以檢視PhilippeRémy提供的
Keras實施的TCN 12. 用于 文本分類的通用語言模型微調 -ULMFiTJEREMY HOWARD和SEBASTIAN
RUDER
遷移學習在計算機視覺方面取得了很多成功,但是同樣的方法應用在NLP領域卻行不通。是以我們提出了通用語言模型微調(ULMFiT),這是一種有效的轉移學習方法,可以應用于NLP中的任何任務。該方法在6個文本分類任務上的性能明顯優于現有的文本分類方法,在大部分的資料集上測試使得錯誤率降低了18-24%。此外,僅有100個标記樣本訓練的結果也相當不錯。我們已經開源我們的預訓練模型和代碼。
Howard和Ruder建議使用預先訓練的模型來解決各種NLP問題。使用這種方法的好處是你無需從頭開始訓練模型,隻需對原始模型進行微調。通用語言模型微調(ULMFiT)的方法優于最先進的結果,它将誤差降低了18-24%。更重要的是,ULMFiT可以隻使用100個标記示例,就能與10K标記示例中從頭開始訓練的模型的性能相比對。
為了解決缺乏标記資料的難題,研究人員建議将轉移學習應用于NLP問題。是以,你可以使用另一個經過訓練的模型來解決類似問題作為基礎,然後微調原始模型以解決你的特定問題,而不是從頭開始訓練模型。
但是,這種微調應該考慮到幾個重要的考慮因素:
§不同的層應該進行不同程度地微調,因為它們捕獲不同類型的資訊。
§如果學習速率首先線性增加然後線性衰減,則将模型的參數調整為任務特定的特征将更有效。
§微調所有層可能會導緻災難性的遺忘;是以,從最後一層開始逐漸微調模型可能會更好。
顯著優于最先進的技術:将誤差降低18-24%;
所需的标記資料要少得多,但性能可以保障。
社群對其的看法是什麼?預先訓練的ImageNet模型的可用性已經改變了計算機視覺領域,ULMFiT對于NLP問題可能具有相同的重要性。
此方法可以應用于任何語言的任何NLP任務。
未來的研究領域的方向是什麼?改進語言模型預訓練和微調。
将這種新方法應用于新的任務和模型(例如,序列标記、自然語言生成、蘊涵或問答)。
ULMFiT可以更有效地解決
各種NLP問題,包括:
§識别垃圾郵件、機器人、攻擊性評論;
§按特定功能對文章進行分組;
§對正面和負面評論進行分類;
§查找相關檔案等
你在哪裡可以得到實作代碼?Fast.ai提供ULMFiT的
官方實施,用于文本分類,并作為fast.ai庫的一部分 13. 用非監督學習來提升語言了解,作者:ALEC RADFORD,KARTHIK
NARASIMHAN,TIM SALIMANS,ILYA
SUTSKEVER
自然語言了解包括各種各樣的任務,例如文本蘊涵、問答、語義相似性評估和文檔分類。雖然大量未标記的文本語料庫很豐富,但用于學習這些特定任務的标記資料很少。我們證明,通過對多種未标記文本語料庫中的語言模型進行生成預訓練,然後對每項特定任務進行辨識性微調,可以實作這些任務的巨大收益。與以前的方法相比,我們在微調期間利用任務感覺輸入轉換來實作有效傳輸,同時對模型架構進行最少的更改。我們證明了我們的方法在廣泛的自然語言了解基準上的有效性。例如,我們在常識推理(Stories Cloze Test)上獲得8.9%的性能改善,在問答(RACE)上達到5.7%,在文本蘊涵(MultiNLI)上達到1.5%。
OpenAI團隊建議通過在多種未标記文本語料庫中預先訓練語言模型,然後使用标記資料集對每個特定任務的模型進行微調,進而可以顯著改善了語言了解。他們還表明,使用Transformer模型而不是傳統的遞歸神經網絡可以顯著提高模型的性能,這種方法在所研究的12項任務中有9項的表現優于之前的最佳結果。
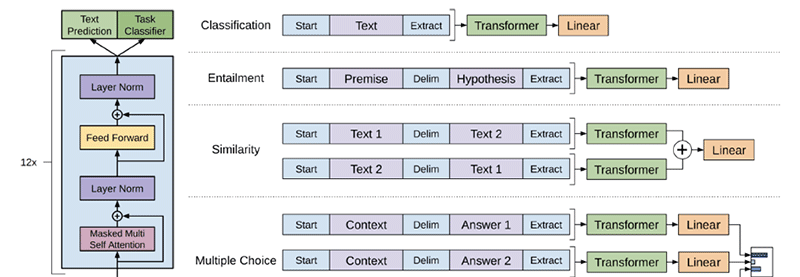
通過在未标記資料上學習神經網絡模型的初始參數,然後使用标記資料使這些參數适應特定任務,結合使用無監督預訓練和監督微調。
通過使用周遊樣式方法避免跨任務對模型體系結構進行大量更改:
§預訓練模型是在連續的文本序列上訓練的,但是問題回答或文本蘊涵等任務具有結構化輸入。
§解決方案是将結構化輸入轉換為預先訓練的模型可以處理的有序序列。
使用Transformer模型而不是LSTM,因為這些模型提供了更加結構化的記憶體,用于處理文本中的長期依賴關系。
取得了什麼關鍵成就?對于自然語言推理(NLI)的任務,通過在SciTail上獲得5%的性能改進和在QNLI上獲得5.8%的性能改進。
對于QA和常識推理的任務,表現優于以前的最佳結果-在Story Cloze上高達8.9%,在RACE上高達5.7%。
通過在QQP上實作4.2%的性能改善,重新整理了3個語義相似性任務中的2個的最新結果。
對于分類任務,獲得CoLA的45.4分,而之前的最佳結果僅為35分。
社群對其看法是什麼?該論文通過使用基于Transformer模型而非LSTM擴充了ULMFiT研究,并将該方法應用于更廣泛的任務。
“這正是我們希望我們的ULMFiT工作能夠發揮作用的地方!”
Jeremy Howard,fast.ai的創始人。
進一步研究自然語言了解和其他領域的無監督學習,以便更好地了解無監督學習的時間和方式。
OpenAI團隊的方法通過無監督學習增強了自然語言了解,是以可以幫助标記資料集稀疏或不可靠的NLP應用。
在哪裡可以得到實作代碼?Open AI團隊在
GitHub上的公開了代碼和模型。
14. 語境化詞向量解析:架構和表示 ,作者:MATTHEW E. PETERS,MARK NEUMANN,LUKE ZETTLEMOYER,WEN-TAU YIH最近研究顯示從預訓練的雙向語言模型(biLM)導出的上下文詞表示為廣泛的NLP任務提供了對現有技術的改進。然而,關于這些模型如何以及為何如此有效的問題,仍然存在許多問題。在本文中,我們提出了一個詳細的實證研究,探讨神經結構的選擇(例如LSTM,CNN)如何影響最終任務的準确性和所學習的表征的定性屬性。我們展示了如何在速度和準确性之間的權衡,但所有體系結構都學習了高品質的上下文表示,這些表示優于四個具有挑戰性的NLP任務的字嵌入。此外,所有架構都學習随網絡深度而變化的表示,從基于詞嵌入層的專有形态學到基于較低上下文層的局部文法到較高範圍的語義。總之,這些結果表明,無人監督的biLM正在學習更多關于語言結構的知識。
今年早些時候艾倫人工智能研究所的團隊介紹了ELMo嵌入,旨在更好地了解預訓練的語言模型表示。為此,他們精心設計了無監督和監督任務上廣泛研究學習的單詞和跨度表示。研究結果表明,獨立于體系結構的學習表示随網絡深度而變化。
預訓練的語言模型大大提高了許多NLP任務的性能,将錯誤率降低了10-25%。但是,仍然沒有清楚地了解為什麼以及如何在實踐中進行預訓練。
為了更好地了解預訓練的語言模型表示,研究人員憑經驗研究神經結構的選擇如何影響:
§直接終端任務準确性;
§學習表示的定性屬性,即語境化詞表示如何編碼文法和語義的概念。
什麼是關鍵成就?确認在速度和準确度之間存在權衡,在評估的三種架構中-LSTM,Transformer和Gated
CNN:
§LSTM獲得最高的準确度,但也是最慢的;
§基于Transformer和CNN的模型比基于LSTM的模型快3倍,但也不太準确。
證明由預先訓練的雙向語言模型(biLM)捕獲的資訊随網絡深度而變化:
§深度biLM的詞嵌入層專注于詞形态,與傳統的詞向量形成對比,傳統的詞向量在該層也編碼一些語義資訊;
§biLM的最低上下文層隻關注本地文法;
證明了biLM激活可用于形成對文法任務有用的短語表示。
該論文在EMNLP 2018上發表。
“對我來說,這确實證明了預訓練的語言模型确實捕獲了與在ImageNet上預訓練的計算機視覺模型相似的屬性。”AYLIEN的研究科學家
Sebastian Ruder使用明确的句法結構或其他語言驅動的歸納偏見來增強模型。
将純無監督的biLM訓練目标與現有的注釋資源以多任務或半監督方式相結合。
1、通過更好地了解預訓練語言模型表示所捕獲的資訊,研究人員可以建構更複雜的模型,并增強在業務環境中應用的NLP系統的性能。
本文由
阿裡雲雲栖社群組織翻譯。
文章原标題《WE SUMMARIZED 14 NLP RESEARCH BREAKTHROUGHS YOU CAN APPLY TO YOUR BUSINESS》作者:
Mariya Yao譯者:虎說八道,審校:袁虎。
文章為簡譯,更為詳細的内容,請檢視
原文![吳恩達logistic回歸實作[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)