在過去幾年中, 深度學習
改變了整個人工智能的發展。深度學習技術已經開始在醫療保健,金融,人力資源,零售,地震檢測和自動駕駛汽車等領域的應用程式中出現。至于現有的成果表現也一直在穩步提高。
在學術層面,
機器學習 領域已經變得非常重要了,以至于 每 20 分鐘就會出現一篇新的科學文章。
在本文中,我将介紹2018年深度學習的一些主要進展,與
2017 年深度學習進展版本一樣 ,我沒有辦法進行詳盡的審查。我隻想分享一些給我留下最深刻印象的領域成就。 語言模型: Google 的 BERT 在 自然語言處理 (NLP)中, 語言模型 是可以估計一組語言單元(通常是單詞序列)的機率分布的模型。在該領域有很多有趣的模型,因為它們可以以很低的成本建構,并且顯着改進了幾個NLP任務,例如 機器翻譯 , 語音識别 和内容 解析 曆史上,最著名的方法之一是基于 馬爾可夫模型 和 n-gram 。随着深度學習的出現,出現了基于 長短期記憶網絡(LSTM)更強大的模型。雖然高效,但現有模型通常是單向的,這意味着隻有單詞的上下文才會被考慮。
去年10月,Google AI語言團隊發表了一篇引起社群轟動的論文。
是一種新的雙向語言模型,它已經實作了11項複雜NLP任務的最新結果,包括 情感分析 、 問答 複述檢測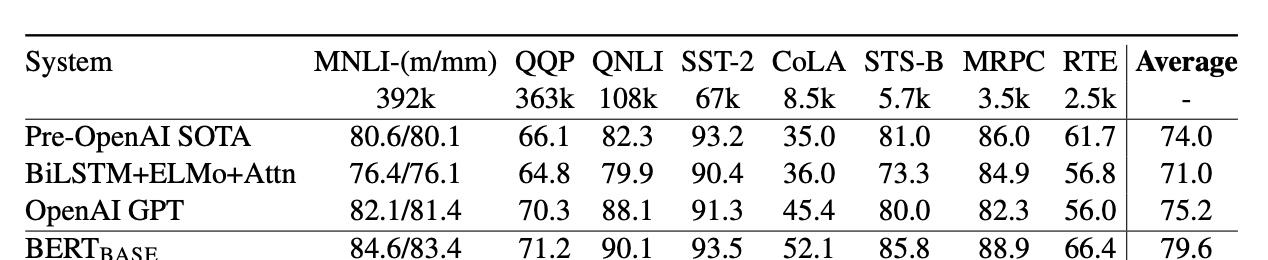
GLUE基準的比較結果
預訓練BERT的政策不同于傳統的從左到右或從右到左的選項。新穎性包括:
·
随機屏蔽一定比例的輸入詞,然後預測那些被屏蔽的詞;這可以在多層次的背景下保持間接“看到自己”的詞語。
建構二進制分類任務以預測句子B之後是否緊跟句子A,這允許模型确定句子之間的關系,這種現象不是由經典語言模組化直接捕獲的。
至于實施,Google AI開源
了他們的論文代碼,該代碼 基于TensorFlow。其中一些在PyTorch也能實作,例如 Thomas WolfJunseong
Kim
的實作 BERT對業務應用程式的影響很大,因為這種改進會影響NLP的各個方面。這可以在機器翻譯,聊天機器人行為,自動電子郵件響應和客戶審查分析中獲得更準确的結果。 視訊到視訊合 成 我們通常習慣由 圖形引擎建立的模拟器和視訊遊戲進行環境互動。雖然令人印象深刻,但經典方法的成本很高,因為必須精心指定場景幾何、材料、照明和其他參數。一個很好的問題是:是否可以使用例如深度學習技術自動建構這些環境。
在他們的
視訊到視訊合成論文中 ,NVIDIA的研究人員解決了這個問題。他們的目标是在源視訊和輸出視訊之間提供映射功能,精确描繪輸入内容。作者将其模組化為分布比對問題,其目标是使自動建立視訊的條件分布盡可能接近實際視訊的條件分布。為實作這一目标,他們建立了一個基于 生成對抗網絡(GAN)的模型。在GAN架構内的關鍵思想是,生成器試圖産生真實的合成資料,使得鑒别器無法區分真實資料和合成資料。他們定義了一個時空學習目标,旨在實作暫時連貫的視訊。
結果非常驚人,如下面的圖檔所示:

的街道場景視訊的分段圖。作者将他們的結果(右下)與兩個基線進行比較:pix2pixHD(右上)和COVST(左下)。
這種方法甚至可以用于執行未來的視訊預測。由于NVIDIA開源
vid2vid 代碼 (基于PyTorch),你可以嘗試執行它。改進詞嵌入
去年,我寫了關于
字嵌入在 NLP 中的重要性,并且相信這是一個在不久的将來會得到更多關注的研究課題。任何使用過詞嵌入的人都知道,一旦通過組合性檢查的興奮(即King-Man+Woman=Queen)已經過去,因為在實踐中仍有一些限制。也許最重要的是對多義不敏感,無法表征詞之間确切建立的關系。到底同義詞Hyperonyms?另一個限制涉及形态關系:詞嵌入模型通常無法确定諸如駕駛員和駕駛之類的單詞在形态上是相關的。
在題為“
深度語境化詞語表示 ”(被認為是
NAACL 2018 年 優秀論文)的
論文中,來自艾倫人工智能研究所和Paul G. Allen計算機科學與工程學院的研究人員提出了一種新的深層語境化詞彙表示方法。同時模拟單詞使用的複雜特征(例如文法和語義)以及這些用途如何在語言環境(即多義詞)中變化。
他們的提議的中心主題,稱為語言模型嵌入(ELMo),是使用它的整個上下文或整個句子來對每個單詞進行矢量化。為了實作這一目标,作者使用了深度雙向語言模型(biLM),該模型在大量文本上進行了預訓練。另外,由于表示基于字元,是以可以捕獲單詞之間的形态句法關系。是以,當處理訓練中未見的單詞(即詞彙外單詞)時,該模型表現得相當好。
六項基準NLP任務中最先進模型的比較結果。
作者表明,通過簡單地将ELMo添加到現有的最先進解決方案中,結果可以顯著改善難以處理的NLK任務,例如
文本解釋,共
指解析,與Google的BERT表示一樣,ELMo是該領域的重要貢獻,也有望對業務應用程式産生重大影響。
視覺任務空間結構的模組化
視覺任務是否相關?這是斯坦福大學和加州大學伯克利分校的研究人員在題為“
Taskonomy :Disentangling Task Transfer
Learning
”的論文中
提出的問題,該
論文獲得了
2018 CVPR 最佳論文獎可以合理地認為某些視覺任務之間存在某種聯系。例如,知道表面法線可以幫助估計圖像的深度。在這種情況下,
遷移學習技術-或重用監督學習結果的可能性将極大的提高。
作者提出了一種計算方法,通過在26個常見的視覺任務中找到轉移學習依賴關系來對該結構進行模組化,包括對象識别、邊緣檢測和深度估計。輸出是用于任務轉移學習的計算分類圖。
由計算任務分類法發現的示例任務結構。
上圖顯示了計算分類法任務發現的示例任務結構。在該示例中,該方法告知我們如果組合了表面法線估計器和遮擋邊緣檢測器的學習特征,則可以用很少的标記資料快速訓練用于重新整形和點比對的模型。
減少對标簽資料的需求是這項工作的主要關注點之一。作者表明,可以通過粗略地減小求解一組10個任務所需的标記的資料點的總數2/3(具有獨立訓練相比),同時保持幾乎相同的性能。這是對實際用例的重要發現,是以有望對業務應用程式産生重大影響。
微調通用語言模型以進行文本分類
深度學習模型為NLP領域做出了重大貢獻,為一些常見任務提供了最先進的結果。但是,模型通常從頭開始訓練,這需要大量資料并且需要相當長的時間。
Howard Ruder提出了一種歸納
方法,稱為通用語言模型微調(ULMFiT)。主要思想是微調預訓練的語言模型,以使其适應特定的NLP任務。這是一種精明的方法,使我們能夠處理我們沒有大量資料的特定任務。
兩個文本分類資料集上的測試錯誤率(越低越好)。
他們的方法優于六個
文本分類任務的最新結果,将錯誤率降低了18-24%。關于訓練資料的數量,結果也非常驚人:隻有100個标記樣本和50K未标記樣本,該方法實作了與10K标記樣本從頭開始訓練的模型相同的性能。
同樣,這些結果證明遷移學習是該領域的關鍵概念。你可以在
這裡檢視他們的代碼和預訓練模型。
最後的想法
與去年的情況一樣,2018年深度學習技術的使用持續增加。特别是,今年的特點是遷移學習技術越來越受到關注。從戰略角度來看,這可能是我認為今年最好的結果,我希望這種趨勢在将來可以繼續下去。
我在這篇文章中沒有探讨的其他一些進展同樣引人注目。例如,強化學習的進步,例如能夠擊敗
Dota 2職業玩家的驚人的
OpenAI Five 機器人。另外,我認為現在
球 CNN,特别有效的分析球面圖像,以及
PatternNet PatternAttribution,這兩種技術所面臨的神經網絡的一個主要缺點:解釋深層網絡的能力。
上述所有技術發展對業務應用程式的影響是巨大的,因為它們影響了NLP和計算機視覺的許多領域。我們可能會在機器翻譯、醫療診斷、聊天機器人、倉庫庫存管理、自動電子郵件響應、面部識别和客戶審查分析等方面觀察到改進的結果。
從科學的角度來看,我喜歡
Gary Marcus 撰寫的深度學習評論。他清楚地指出了目前深度學習方法的局限性,并表明如果深度學習方法得到其他學科和技術的見解(如認知和發展心理學、符号操作和混合模組化)的補充,人工智能領域将獲得相當大的收益。無論你是否同意他,我認為值得閱讀他的論文。
本文由
阿裡雲雲栖社群組織翻譯。
文章原标題《major-advancements-deep-learning-2018》
作者:
Javier譯者:虎說八道,審校:袁虎。
文章為簡譯,更為詳細的内容,請檢視
原文