【磐創AI導讀】:本文是對fasttext的一個詳細介紹。
fasttext是一個被用于對詞向量和句子分類進行高效學習訓練的工具庫,采用c++編寫,并支援訓練過程中的多程序處理。你可以使用這個工具在監督和非監督情況下訓練單詞和句子的向量表示。這些訓練出來的詞向量,可以應用于許多處理資料壓縮的應用程式,或者其他模型的特征選擇,或者遷移學習的初始化。
FastText支援使用negative sampling,softmax或層次softmax損失函數等方法來訓練CBOW或Skip-gram模型。我已經使用了fastText對一個規模有千萬個單詞的語料庫進行語義詞向量訓練,對于它的表現以及它對原任務的擴充,我都感到非常滿意。在此之前,我很難找到除了 getting started(
https://fasttext.cc/docs/en/support.html)之外的關于fasttext的相關說明文檔,是以在這篇文章中,我将帶您了解fastText的内部原理以及它是如何工作的。對word2vec模型如何工作的了解是需要的,克裡斯·麥考密克的文章(見連結)很好地闡述了word2vec模型。
一. 運作fasttext
我們可以通過下面這條指令來用fastText訓練一個Skip-gram模型:
$ fasttext skipgram -input data.txt -output model
data.txt是一個包含一串文本序列的輸入檔案,輸出模型儲存在model.bin檔案下,詞向量則儲存在model.vec中。
二. 表示方法
fasttext可以在詞向量的訓練和句子分類上取得非常好的表現,尤其表現在對罕見詞進行了字元粒度上的處理。
每個單詞除了單詞本身外還被表示為多個字元級别的n-grams(有時也稱為N元模子)。例如,對于單詞matter,當n = 3時,fasttext對該詞對字元ngram就表示為。其中<和>是作為邊界符号被添加,來将一個單詞的ngrams與單詞本身區分開來。再舉個例子,如果單詞mat屬于我們的詞彙表,則會被表示為。這麼做剛好讓一些短詞以其他詞的ngram出現,有助于更好學習到這些短詞的含義。從本質上講,這可以幫助你捕捉字尾/字首的含義。
可以通過-minn和-maxn這兩個參數來控制ngrams的長度,這兩個标志分别決定了ngrams的最小和最大字元數,也即控制了ngrams的範圍。這個模型被認為是一個詞袋模型,因為除了用于選擇n-gram的滑動視窗外,它并沒有考慮到對單詞的内部結構進行特征選擇。它隻要求字元落在視窗以内,但并不關心ngrams的順序。你可以将這兩個值都設為0來完全關閉n-gram,也就是不産生n-gram符号,單純用單詞作為輸入。當您的模型中的“單詞”不是特定語言的單詞時或者說字元級别的n-gram沒有意義的時候,這會變得很有用。最常見的例子是當您将id作為您的單詞輸入。在模型更新期間,fastText會學習到每個ngram以及整個單詞符号的權重。
三. 讀取資料
雖然fastText的訓練是多線程的,但是讀取資料卻是通過單線程來完成。而文本解析和分詞則在讀取輸入資料時就被完成了。讓我們來看看具體是怎麼做到的:
FastText通過-input參數擷取一個檔案句柄用于輸入資料。FastText不支援從stdin讀取資料,它初始化兩個向量word2int_和words_來跟蹤輸入資訊。word2int_是一個字元串到數值的映射集,索引鍵是單詞字元串,根據字元串哈希值可以得到一個數值作為它的值,同時這個數值恰好就對應到了words_數組(std:::vector)的索引。words_ 數組在讀取輸入時根據單詞出現的順序遞增建立索引,每個索引對應的值是一個結構體entry,這個entry封裝了單詞的所有資訊。條目包含以下資訊:
struct entry {
std::string word;
int64_t count;
entry_type type;
std::vector<int32_t> subwords;
};
在這個entry裡,word是單詞的字元串表示形式,count是各個單詞在輸入序列裡的出現頻次,entry_type的值是word或label中的一個,label選項僅在有監督情況下有效。所有的輸入符号,包括entry_type都存儲在同一個詞典中,這使得擴充fastText來包含其他類型的實體變得更加容易(我将在後續的文章中詳細讨論這一點)。最後,subword是一個包含一個單詞所有的n-grams的向量。這個subword也會在讀取輸入資料時被建立,然後被傳遞到訓練過程中。
word2int_的大小為MAX_VOCAB_SIZE = 30000000,這是一個寫死的數字。當在大型語料庫上進行訓練時,這個大小可以是受限制的,但也可以在保持性能的同時有效地增加。word2int_數組的索引是由字元串得到的整數哈希值,并且是0和MAX_VOCAB_SIZE之間的唯一數字。如果出現哈希沖突,得到的哈希值已經存在,那麼這個值就會增加,直到我們找到一個唯一的id來配置設定給一個單詞為止。
是以,一旦詞彙表的大小達逼近MAX_VOCAB_SIZE,算法性能就會顯著下降。為了防止這種情況,每當哈希值的大小超過MAX_VOCAB_SIZE的75%時,fastText就會對詞彙表進行删減。删減過程是這樣的,首先增加單詞最小計數門檻值來重新确定一個單詞是否有資格出現在單詞表裡,然後對詞典裡所有計數小于這個的單詞進行删減。當添加一個新單詞時,會檢查這個單詞對應的哈希值是否超過75%門檻值,是以這種自動删減可以在檔案讀取過程的任何階段進行。
除了自動删減過程,對于已經存在于詞彙表裡的單詞的最小計數是通過使用-minCount和-minCountLabel(用于監督訓練)這兩個參數來控制的。基于這兩個參數的删減在整個訓練檔案被處理之後進行。如果單詞表的總數已經觸發了前面所說的因哈希值太大發生的自動删減,那麼您的詞典可能就需要手動設定一個較高值的minCount門檻值了。但無論如何,你都必須手動指定minCount門檻值,才能確定較低詞頻的單詞不會被用作輸入的一部分。
在求解負采樣損失函數過程中,一個大小NEGATIVE_TABLE_SIZE = 10000000的負采樣單詞表會被構造。注意它的大小是MAX_VOCAB_SIZE的三分之一。該表是從每個詞詞頻的平方根的一進制模型分布(unigram distribution)中進行采樣構造的,這確定了每個詞出現在負采樣單詞表中的次數與它的頻率的平方根成正比。接着再對該表打亂詞序以確定其随機性。
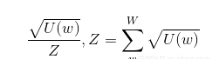
圖一 U(w)是一個特定單詞的計數,W是所有單詞計數的集合
接下來,一個用于删除高頻詞的采樣表會被建構,這個表在the original word2vec extension paper這篇論文的2.3節中有大概描述。這背後的思想是,高頻詞所能提供的資訊比罕見的單詞更少,而且高頻詞即使在遇見到更多相同單詞的執行個體後,它們的詞向量也不會發生太大的變化。
該論文提出了一種删除訓練詞的方法,通過下面公式計算訓練詞被丢棄的機率:

圖二 t為所選門檻值,f(w)為單詞w的出現頻率
作者認為t = 10e-5是一個較為合理的預設值。該公式丢棄了丢棄頻率大于門檻值的詞,并在有效對低頻詞進行采樣的同時又保持了它們的相對頻率,進而抑制了高頻詞的誇大作用。
但另一方面,FastText又重新定義了這種分布。
圖三 t = 10e-4為所選門檻值,f(w)為單詞w的出現頻率
預設的門檻值可以通過 -t 手動設定。門檻值t在fastText中的含義和最初的word2vec論文中的含義有所不同,你應該針對自己的應用程式進行調優。
在訓練階段,隻有當從(0,1)的均勻分布中随機抽取一個值的大小大于單詞被丢棄的機率時,該單詞才會被丢棄。下面是在預設門檻值情況下,單詞被丢棄機率與詞頻f(w)的關系。如圖所示,随着單詞頻率的增加,被抽到的機率大于被丢棄的機率P(w)的機率增加。是以,随着單詞頻率的增加,被丢棄的機率也增加。注意這隻适用于無監督模型,在有監督模型中,單詞不會被丢棄。
圖四 fasttext中預設門檻值下單詞被丢棄機率與詞頻f(w)的關系
如果我們用-pretrainedVectors參數初始化訓練,輸入檔案中的值将被用于初始化輸入層向量。如果未指定,一個次元MxN的矩陣将會被建立,其中M = MAX_VOCAB_SIZE + bucket_size, N = dim。 bucket_size是一個數組的長度大小,這個數組是為所有的ngrams符号配置設定的。它通過-bucket标志進行設定,預設設定為2000000。
所有的ngrams在矩陣裡的位置資訊是通過取得ngram字元串的哈希值(同一個哈希函數)來進行初始化的,并将對該哈希值取模之後的值填到初始化後的矩陣中,其位置對應到MAX_VOCAB_SIZE + hash。注意到在ngrams空間中可能存在哈希沖突,但對于原始單詞來說則是不存在這種情況。這也會影響到模型的性能。
Dim表示訓練中隐藏層的次元,是以詞向量的次元可以通過-dim參數進行設定,預設值為100。矩陣的每個值被初始化為0到1/dim之間的均勻實數分布。
四. 訓練
一旦輸入層和隐藏層向量被初始化成功,多個訓練線程就會啟動。線程數量由-thread參數指定。所有訓練線程都共享一個指向輸入層和隐藏層向量矩陣的指針。所有線程都從輸入檔案中讀取資料,并使用讀取到的每一行來更新模型,其實也就相當于批次大小為1的随機梯度下降法。如果遇到換行字元,或者讀入的單詞數量超過允許的行最大數量,則會截斷該行的後續輸入。這裡通過MAX_LINE_SIZE設定,預設值為1024。
CBOW模型和Skip-gram模型都會同時對一段上下文文本的權重進行更新,這段文本的單詞數量是1到-ws(參數設定)之間的随機均勻分布,也就是說視窗大小是随機的。
損失函數的目标向量是這樣計算的,先對每個輸入向量作歸一化計算,再把歸一化後的所有向量求和可得。輸入向量是原始單詞以及該詞的所有ngrams的向量表示。通過計算這個損失函數,可以在前向傳播的過程中設定權重,然後又一路将影響反向傳播傳遞到輸入層的向量。在反向傳播過程中對輸入向量權重的調整幫助我們學到了使得共現相似性(co occurrence similarity)最大化的詞向量。學習速率參數-lr會決定每條特定的執行個體樣本對權重的影響究竟有多大。
圖五 無監督Skip-gram fastText模型的拓撲結構
模型的輸入層權重、隐藏層權重以及傳入的參數都會儲存在.bin格式的檔案中,-saveOutput标志控制了是否輸出一個包含隐藏層向量的word2vec檔案格式的.vec檔案。
我希望這篇文章能幫助我們了解fasttext的内部工作原理。我個人已經通過使用這個庫取得了很多成功,并強烈推薦你用它去解決你的問題。在下一篇文章中,我将讨論我為fastText添加的一些可以泛化它的能力的附加功能。敬請繼續關注。(譯自:
https://towardsdatascience.com/fasttext-under-the-hood-11efc57b2b3)
原文釋出時間為:2018-07-17
本文作者:Revolver
本文來自雲栖社群合作夥伴“
磐創AI”,了解相關資訊可以關注“
”。