日前,網易數帆旗下人工智能技術與服務品牌——網易易智在CCF和百度聯合舉辦的“千言資料集:文本相似度”行業測評中擊敗多支勁旅,榮登榜首。
文本相似度,即識别兩段文本在語義上是否相似,在自然語言處理(NLP)領域是一個重要研究方向,目前已大規模商用于智能客服、資訊檢索、新聞推薦等領域,如已服務超40萬企業客戶的網易七魚智能客服,背後就有這項技術的支撐。
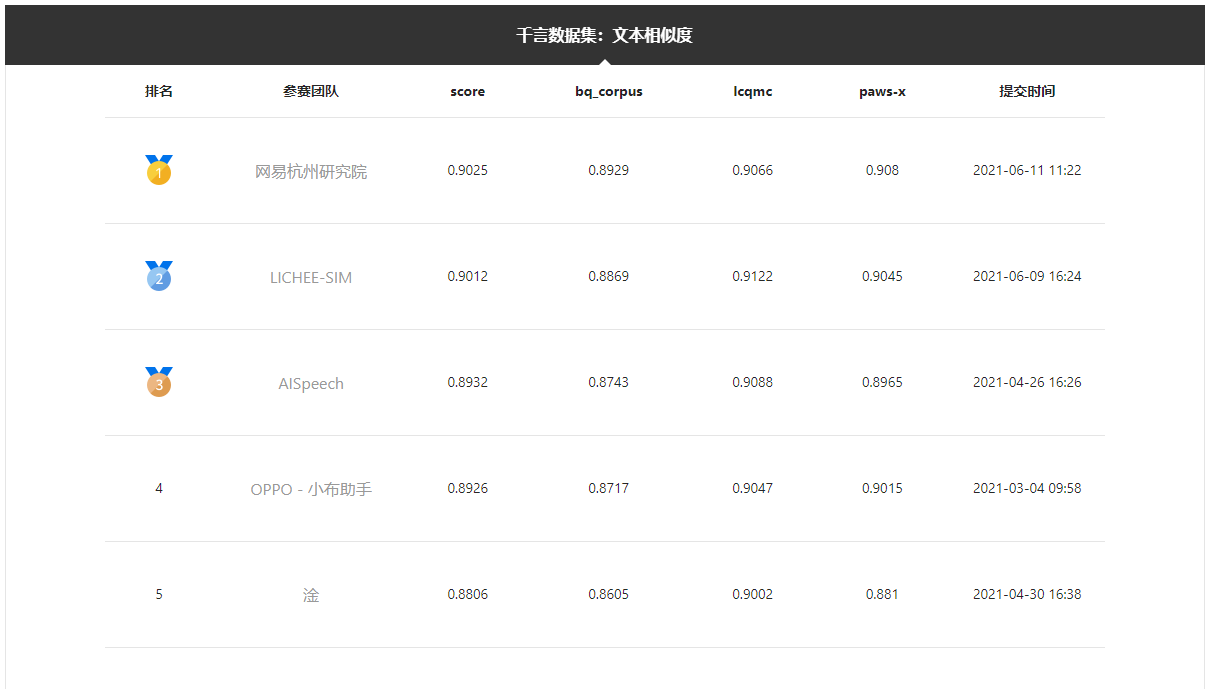
榜單中“網易杭州研究院”為網易易智團隊
“千言資料集”系列評測是中文自然語言處理領域的大規模賽事,其中文本相似度開源項目收集了來自哈爾濱工業大學的LCQMC、BQ Corpus,以及谷歌的PAWS-X(中文)等公開資料集,期望對文本相似度模型效果進行綜合的評價,推動文本相似度在自然語言處理領域的應用和發展。
據了解,這些公開資料集在相關論文的支撐下,對現有的公開文本相似度模型進行了較全面的評估,具有較高的權威性,代表了文本相似度技術研究的最高水準。

哈爾濱工業大學(深圳)LCQMC資料集任務示例
在本次文本相似度測評中,網易易智結合了多年技術經驗積累,和大規模預訓練語言模型的運用,再加上對比賽任務進行的針對性優化,取得了目前的優異成績。
網易易智的參賽隊伍表示,這次比賽任務主要有2個難點。一個難點是BQ Corpus資料集是金融領域的資料,該資料集涉及到金融行業的大量知識,而通用預訓練語言模型難以捕捉到特定行業的潛在知識。為此,團隊采用半監督學習等方式,從網易内部多個業務場景中挖掘出泛金融領域知識,進而獲得金融領域預訓練語言模型,最終在該任務上較大幅度領先于其他參賽團隊。
而另一個難點是PAWS-X資料集的品質問題,該資料來自于英文的翻譯,翻譯内容與真實中文有出入,尤其會對算法造成幹擾的是實體詞(如人名、地名)的翻譯不統一,即相同的人名,前一個句子保留英文原文,後一個句子卻音譯為中文。針對這個資料特點,網易易智利用自研的NER(命名實體識别)服務進行實體詞的識别與歸一化,并利用自研的中文文本糾錯服務糾正其中的錯别字、語病之後,再進行模型訓練,最終在該任務上也取得了第一。
網易易智基于文本相似度等系列NLP技術建構了一套智能對話系統,服務集團内部多個業務,如嚴選客服、IT咨詢等,并與七魚業務聯合打造智能客服機器人産品,服務集團外部客戶。
以九陽股份有限公司為例,其核心訴求之一,是通過高效、精準、人性化的咨詢服務保障使用者的購物體驗,如使用者對于小家電産品功能、操作、價格、優惠活動、養護、維修等問題的咨詢。
為此,九陽接入了網易七魚線上機器人,在問題比對率可高達90%以上的基礎上,提供更懂使用者的智能服務體驗。**基于網易易智文本相似度算法,七魚線上機器人實作了核心語義比對,進而達成BOT、FAQ等功能。此外,通過語義比對技術,七魚線上機器人還實作了對知識庫的智能挖掘與生成。**借助這些能力,七魚線上機器人可以高效、精準地解答不同場景下的客戶問題。
而在快遞領域,申通快遞也接入了七魚智能客服應對快遞咨詢問題,這是一個與上述金融、小家電完全不同的領域,然而運用網易易智同樣的技術原理,智能客服快速實作了相似的效果。
文本相似度技術的商業價值并不局限于智能客服領域。據網易易智負責人介紹,文本相似度技術大類歸于文本比對,除了對話引擎裡,該技術在網易内部還有更多的應用落地,如網易雲音樂中的評論智能挖掘、直播/短視訊中的歌詞比對以及知識公路業務中的視訊選題相似度檢測等創新解決方案應用。
而從整個技術領域來看,作為一門讓機器了解人類語言的技術,NLP素有“人工智能皇冠上的明珠”之稱,既是難以攻克的前沿課題,也對數字業務創新具有重要的意義。除了文本相似度,網易易智也一直在探索NLP技術與業務創新的最大公約數,并取得了一些階段性的成果。
例如,語義解析技術在軟體測試中的使用,顯著提升自動化水準、實作降本增效,這對于數字化軟體品質的保障非常有利;文本糾錯技術在網易新聞等文稿審校場景中大規模使用,将拼寫及文法等錯誤及時發現并予以糾正,大幅提升使用者閱讀體驗,同時降低内容生産的工作量。
未來,網易易智還将聯合網易數帆旗下有數團隊,探索NLP在大資料系統中的應用,如支援業務人員與分析系統的自然語言互動,使得企業能夠更好地發揮大資料的價值。