2015年12月,也就是在一年前,開發了半年的雲存儲服務上線。這對于付出了半年努力的我們來說,是一件鼓舞人心的事件。因為這個服務在我們手上經曆了從0到1的過程。這是我們自己的一小步,卻是整個雲存儲服務的一大步。
我們開發的是一款視訊監控類的軟體,分為視訊采集端跟觀看端。采集端可以是專業攝像頭,手機,無人機等各類智能裝置,觀看端一般是手機或者電腦。最基礎的功能,就是視訊觀看,采集端實時采集圖像,編碼,傳輸,觀看端進行點播服務。同時采集端可以監測視訊畫面的運動幅度,然後觸發報警,并且會錄制報警視訊。我們的雲存儲服務就是将錄制的報警視訊上傳到雲端,并且在觀看端提供檢視功能
第一個版本叫2.0,至于為什麼叫2.0,或許這隻是一個代号而已。
整個系統的架構如下:
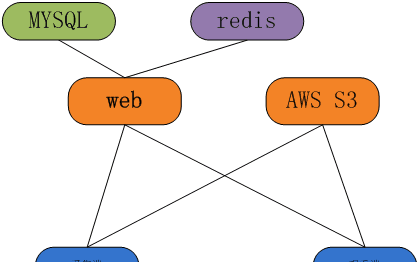
整個系統由用戶端, web伺服器, 資料庫, 檔案存儲伺服器構成。檔案伺服器使用的是亞馬遜的S3,對于小公司來說,選擇亞馬遜比自建存儲的成本要低得多。
我們要求系統要盡可能及時的上傳報警視訊。一個報警視訊大概錄制30s,及時意味着報警一旦觸發就要開始上傳,而不是等報警視訊錄制結束了再上傳錄制下來的報警檔案。而且在有些裝置上,如攝像頭,是可以沒有存儲卡的,但是也得能上傳,是以選擇上傳報警視訊檔案的方式就不可取了。而在s3服務使用的是http協定上傳檔案,必須在上傳檔案之前告訴伺服器檔案的大小,即http頭裡面的content-length資訊。為了解決這個問題,我們使用了分片上傳的方式。就是首先根據視訊的分辨率大小,計算出一個檔案size,這個大約能存儲10s左右的視訊。在上傳過程中,計算已經上傳的資料量大小,當一個分片存儲滿之後,再開始另一個分片。在最後一個分片時,可能報警視訊已經錄制結束了,但是分片還沒存滿,這時候就用空資料填充。當然空資料的位置也得記錄下來,這樣觀看端在播放時,就不至于把空資料當作正常資料,導緻播放失敗。除了正常的視訊資料,在每段報警視訊的最後還得記錄視訊中的I幀位置資訊,主要是用于在播放時拖動,尋找位置資訊。這一點是參考mp4檔案的錄制方式,由于我們使用的并不是标準的mp4格式,是以在上傳視訊的過程中,得将I幀的位置資訊記錄下來,待整個視訊上傳結束後,将位置資訊存儲在視訊的尾部,最後不足一個分片的部分,再用空資料填上。
整個采集端來說,上傳檔案到亞馬遜S3的過程就是如此,那麼跟web伺服器又是怎麼互動的呢?
第一步,采集端在觸發了一個報警時,要向web伺服器申請一個EVENTID,作為這個報警事件的唯一辨別,在之後上傳檔案都跟這個EVENTID綁定。觀看端在播放時,根據這個EVENTID查到它對應的視訊檔案,然後去亞馬遜S3上下載下傳播放。
第二步,當采集端向亞馬遜上傳一個分片檔案時,需要生成一個uri,然後才能向這個uri PUT資料。uri的生成,采集端可以直接向亞馬遜申請,但是考慮到申請uri需要攜帶亞馬遜的賬戶秘鑰,放在用戶端做不安全,是以申請uri還是放在web伺服器上。當采集端需要上傳檔案,向web伺服器去申請。每次采集端申請uri時,帶上EVENTID,以及一個分片index,即告訴web伺服器你要申請的是哪個eventid的第一個分片。生成的uri格式如下
http://xxxxxxxxxxxxxxxxxxxxxxxx/eventid/index.avi。前面的xxxx表示你在 s3上面建立的存儲桶,index即是第幾個檔案, avi是檔案的字尾名(這裡是一個假設,叫什麼都可以)。每開始一個新的分片,index自動加1,這樣在隻需要記錄一個最終的index即可。下載下傳時,根據最終的index大小,就可以把所有的檔案都下載下傳下來。當申請到uri之後,采集端就可以通過http協定向這個uri上傳資料了。
第三步,在每個uri上傳結束之後,向web伺服器report一次 event資訊。這個event資訊,即是第一步開始時申請的eventid。彙報的資訊,包括這個event 的觸發時間,類型,視訊時長,視訊分辨率,音頻的采樣率,以及index。可以看到,每個uri上傳結束都彙報一次的資訊,其實也隻有index的值不同,其他的值都一樣。本來是可以等到在一個視訊完全上傳結束之後,一次性彙報一次event資訊就OK了。但是考慮到,當一個視訊正在上傳的過程中,采集端軟體crash了,或者小偷進來後裡面将監控裝置砸了,是以要每上傳一個分片都要彙報一次。這樣,觀看端檢視時,就可以看到一個未完成的視訊了。除了這點外,也要注意到可能一個分片都沒上傳上去,就發生意外,是以我們在每次報警一觸發,就立即抓一幅圖檔,上傳到S3上。
上面基本就是整個系統上傳部分的流程。web伺服器負責生成eventid, 申請uri,以及寫資料庫。資料庫隻要存儲一張event表項就可以了,表項裡面記錄了這個event 的詳細資訊。
在2.0版本中,雖然使用了redis緩存,用來降低mysql的通路壓力,但是緩存的使用很簡單,僅僅存儲了一個采集端每天的event個數。這樣觀看端查詢時,可以一次性擷取到最近30天,每天的event個數。因為我們隻給使用者保留最近30天的資料,在redis上做了個數統計,就不用再去資料庫讀表統計了。
接下來再說說觀看端的查詢流程
首先,就是去查詢采集端最近一個月每天的event個數。
然後,再具體檢視某一天的報警時,帶上日期,起 始時間段,去伺服器查詢event清單。在傳回結果之後,将event資訊作本地緩存。如果下次再查詢,先檢視本地緩存中是否存在,如果有就直接傳回。
最後,根據web伺服器傳回的event資訊,包括了這個event對應着亞馬遜伺服器上的uri,通過uri下載下傳視訊資料播放。同時也将視訊資料緩存到本地檔案中,供下次檢視時使用。
2.0版本完成了0到1 的跨越,但是整個系統與服務還處于初級階段。在剛上線之後,就開始了3.0的開發工作。
3.0版本的主要目的是完成視訊資料與事件的分離。在2.0 版本中,我們以事件為機關,向AWS 上傳檔案,這種業務模型有着一定局限性,檔案資料強依賴事件。理想的狀态應該是,檔案資料應該是一個整體,而不應該按照事件來劃分。事件隻需要記錄,其對應的檔案資料即可。對于一個事件,我們隻需要在資料庫儲存它的一些基本資訊(比如時間,類型等等),然後記錄下這個事件對應的資料在雲端的位置。這樣做有兩個好處:
1 資料與事件解耦,雲端存儲的隻是一堆檔案,易于維護
2 資料可以複用,比如兩個事件發生的時間有重疊,在2.0版本,重疊的資料就要上傳兩次,浪費了存儲空間

如圖所示,我們在上傳本地資料檔案時,依然使用分片方式上傳。每讀取一幀資料,判斷一下資料的時間戳有沒有到達事件的開始時間。如果到達,那麼就向web伺服器彙報一次事件資訊,并且記錄下這個事件的開始在該分片檔案中所處的位置。同樣,判斷目前正在處理的事件,比較時間戳,是否已經達到結束時間。如果已經結束,同樣記錄一個結束位置。一個分片檔案可能對應多個event,有些event在這個分片檔案的某個地方開始,有些event在這個分片檔案的某個地方結束,還有些event可能占有整個分片檔案。當一個分片檔案上傳結束時,需要向web伺服器彙報分片檔案資訊,包括一些基本資訊(大小,媒體參數,以及檔案的uri等),以及分片檔案與event的映射關系,即event的位置資訊。在資料庫的設計中,event存儲一個表項,分片檔案存儲一個表項,映射關系存儲一個表項。
關系如下圖所示:
在event與file的映射表項中,存儲了event與file id,以及這個event的開始位于file的位置(start_pos)以及結束位置file中的位置(end_pos)。如果這個event不在這個file中開始,也不在這個file中結束,那麼說明這個file處于這個event的中間,既不是第一個分片,也不是最後一個分片,那麼start_pos就是0,end_pos就是分片檔案大小,即分片的結束。index就是這個分片檔案是該event的第幾個分片檔案。
當我們觀看某個雲視訊時,隻需要在資料庫中按照event進行查找,即可以傳回這個event的所有分片檔案。觀看端拿到這些分片檔案資訊去亞馬遜S3下載下傳,就行播放。
對于資料庫的影響:
2.0版本中,對于一個event在上傳一個分片檔案之後,就要向web伺服器彙報一次。web伺服器判斷該event是否是第一次彙報,如果是在資料庫插入一行新的表項;如果不是,則要更新之前插入的表項
3.0版本中,分片檔案每次彙報,隻需要插入表項即可,沒有更新操作。event資訊在開始的時候彙報一次,在結束的時候需要更新一次。
整體來說,3.0版本中減少了資料庫的update操作。搞過資料庫的人都知道,更新操作比插入對資料庫的消耗大得多,從某種意義上來說也變相減輕了資料庫的負載。
在3.0版本中,我們修改了redis的使用政策。2.0版本僅僅用redis來統計每天的event數量,但是其實在查詢的時候,我們并不需要關心有多個數量。移動端查詢時,是按業來查詢的,每次查詢10個,每次向下翻頁就再查詢10個,無法再翻頁時,就說明已經查詢出當天所有資料了。為了提高查詢性能,我們将event的資訊存儲在redis裡面。包括event 的觸發時間,時長,icon資訊。按照日期+cid(采集端的id,唯一辨別)+type(event類型)作為key, value是一個list類型的值,儲存當天所有的event id資訊。然後再用eventid作key, value儲存event的詳細資訊。這樣在查詢時,先按照cid+日期+類型找到清單key,從裡面讀取一頁的資料。然後再根據這一頁的資料,去查詢裡面每個event的詳細資訊。這樣在查詢清單時就不要再通路資料庫了。
濃縮視訊,壓倒資料庫的最後一根稻草
3.0版本上線三個月之後,系統運作的還算良好,但是我們發現資料庫表項在飛速膨脹。我們的雲服務使用者已經有幾萬個,每個采集端每天平均都要上傳幾十條視訊,是以按照這種速度,單表記錄很快就來到了将近1000w。在mysql上,1000萬幾乎就是單表記錄上限了。搞web的兄弟發現這一趨勢後,做了分表方案。按照采集端的cid尾數 即(0-9),将event,file,以及映射表分成了10張表。雖然是解決了存儲方面的問題,但是随着使用雲服務的使用者在不斷增加,資料庫的通路壓力也在漸增。在3.0版本,我們新增了濃縮視訊功能,就是将一天中的視訊變化壓縮成很短的幾分鐘。由于短視訊每天才産生一個,是以我們在當天錄制完之後,第二天的0點之後開始上傳前一天産生的濃縮視訊。這個功能在3.0版本上運作了一段時間,剛開始沒有問題。但是在不知不覺中,卻為自己刨了一個大坑。那段時間營運部門搞促銷活動,使用者登入送積分,用積分贈送雲服務。突然有一天,測試人員早上過來後發現前一天的濃縮視訊沒有上傳,翻開采集端日志一看,在淩晨0點之後那段時間,所有的web請求全部失敗了。讓運維同學檢視了下淩晨那段時間發生了啥,一看驚呆了,在0點0分0秒那一刻,瞬間湧入了上萬的請求。web伺服器還好,有負載均衡,但是資料庫隻有一台,1s之内成千上萬的請求,資料庫不死才怪。由于在采集端做了失敗重試,請求失敗之後又會接着再次請求,資料庫幾乎一直在"卧倒"狀态。幸好的是,采集端做了重試次數限制,是以基本在淩晨1點之後請求數也就慢慢降下來了。而這一切,都是由于濃縮視訊集中在淩晨那段時間上傳導緻的。做促銷活動的那幾天,每天都會送出1w多的雲服務,一下子就把資料庫壓垮了。其實解決這個問題的方法很簡單,對于濃縮視訊來說,我們隻要保證上傳了就可以,沒必要非得全部擠在0點這個時間。我們把上傳的時間随機延長至0~5點之間任何一個時間點,保證使用者在早上起來後能檢視到即可。很快就出了更新版本,伺服器的通路壓力随即降了下來,服務也回歸正常。但是還是有一種隐約的不安,因為使用者還在快速增長,不知道哪一天伺服器又會遇到類似的問題。
3.0版本告一段落之後,随即開始了4.0版本的規劃。4.0版本主要要解決的,就是伺服器的通路壓力,包括web伺服器以及資料庫。主要的性能瓶頸還在資料庫上, web伺服器作水準擴容很簡單,因為在web伺服器前面有nginx作為接入層做負載均衡,新增一台web伺服器直接在nginx上加個配置就行了。但是資料庫因為還沒有做分庫,是以隻能先優化單台資料庫的性能。使用Innodb引擎寫性能每秒幾百個,還能再撐一段時間。運作雲存儲服務的采集端大約有幾萬台,每秒鐘的并發請求量還沒那麼大。但是資料量增長太快卻是一個問題,雖然已經按照采集端的cid做了分表,但是表項的資料按照現在的增長速度很快又會到千萬。分表也不可能這樣無限制的做下去,但是分表政策卻是可以調整的。其實我們的雲服務有一個特點,就是資料隻儲存30天,查詢的時候也是按天來查詢,是以優先應該選擇按天來分表才對。30天過後,直接删除掉老的表項,這樣資料就不會無限量的膨脹。每天建一張表,資料量也不會達到單表上限。僅僅是這樣實作一下其實也不複雜,但是考慮到版本相容就沒那麼簡單了。資料庫還是隻有一台,使用者如果還是使用3.0的版本,我們也得按照新的分表方式來寫表。這樣就帶來一個問題,即按時間分表,到底是按照event的觸發時間來分表,還是按照event的上傳時間來分表?這到底有什麼差別呢。一般情況下,采集端在觸發報警時,要立馬上傳視訊。但是如果當時斷網了,我們也會緩存在本地,等到網絡恢複了再上傳。是以有可能在當天觸發的報警視訊在第二天才能上傳,也有可能更晚。剛開始想按照event的上傳時間來做分表,這樣做隻要在伺服器端判斷下目前時間,将請求直接插入到對應日期的表項中就行了。但是這種做法,查詢性能就比較差了。查詢的時候按日期查詢,這個日期是event的觸發時間。我們并不能确切地知道這一天的報警視訊到底被存儲在哪些表項當中。隻能周遊這一天的前後幾張表,都查詢一遍。很顯然這會影響到查詢性能。于是就考慮按照event的觸發時間來做分表。但是又有另外一個問題,每個event在剛開始上傳時,需要向web伺服器彙報一次event資訊,結束時要再彙報一次,更新event的上傳狀态和總時長。在開始彙報時,帶了event的觸發時間資訊,但是在結束彙報時并沒有帶時間資訊,隻有event id。因為在3.0版本中,是根據cid來分表的,在結束彙報時帶了cid資訊。但是按照4.0版本的分表方式,老版本的采集端在結束時彙報,緊靠cid資訊就不知道到哪張表裡去更新了。簡單的方法就是從當天的表項,往前周遊,直到查到為止。但是這樣效率就很低了,更新一次帶來的性能壓力太大。後來想到了利用redis緩存,其實在event第一次彙報資訊時,我們就已經将這些資訊記錄在redis裡面了,是以隻要根據eventid 在redis裡面查到event的觸發時間,然後就可以直接插入到資料庫中。這是為了相容3.0版本的政策,但是在4.0版本中,我們直接在申請eventid時,就帶上了日期資訊,保證擷取到的eventid的前面幾位就是event的觸發時間日期。這樣根據eventid就可以知道分表資訊了,省略了查詢緩存的過程。4.0版本的優化大概就是這樣了。但是這還遠未結束,僅僅的分表政策終究是有它的極限的,單台資料庫的讀寫性能就擺在那裡,下一步要做分庫才行。為了提高性能,還可以使用異步化寫入,即資料先儲存到緩存中,然後批量寫資料庫,降低資料庫的峰值壓力。
總結:
很多時候, 我們談到高并發 高負載,就會想到叢集 ,分布式等一些高大上的名詞。但是如果連單機性能都沒有做好,談那些也就是空中樓閣了。記得之前看到,說通路量排名全世界前20的網站stackoverflow,隻有區區20多台伺服器,而且用的是.net。可見對業務本身的優化,比基礎設施的建設更加重要。業務優化應該達到兩個目的:第一,使你的代碼運作性能更高;第二,使得整體的業務架構易于擴充。談叢集,分布式部署,也不是一蹴而就。在開發代碼時,就要考慮到能夠水準擴充等因素。這樣在未來,擴充叢集時,便也輕松了許多