機器之心報道
編輯:杜偉
當一個領域的規模越來越大,每年發表的論文越多越多時,對于該領域來說,是好事還是壞事呢?
一周前,計算機視覺領域經典之作、何恺明的 ResNet 論文的被引次數突破了 10 萬+,而這距離他送出這篇論文僅過去六年。這一工作的熱度如此之高,既顯示出了 ResNet 本身的久經考驗,也印證了 AI 領域,特别是計算機視覺如今的火熱程度。
然而,ResNet 高被引的背後也讓我們看到了一個問題,那就是計算機視覺領域每年産出那麼多的新論文,為何研究者往往還是選擇它作為引文呢?對高被引經典論文的趨向性究竟會給領域帶來進步還是停滞呢?新發表的論文是否還有可能成為下一個經典之作呢?
在近日發表在 SCI 期刊 PNAS 上的一篇論文《Slowed Canonical Progress in Large Fields of Science》中,來自美國西北大學和芝加哥大學的兩位研究者對上述問題進行了解答,并深入探讨了科學領域發表論文的數量、品質以及被引情況之間的錯綜複雜的關聯。
對科學進步有種很直接的觀點,那就是多多益善。一個領域發表的論文越多,科學進步的速度就越快;研究者數量越多,覆寫的面就越廣。即使并非每篇論文都産生重大的影響,但它們都成為了聚成沙堆的沙粒,增加了出現質變的可能性。在這一過程中,科學景觀得到了重新配置,結構性探究中出現了新的範式。
更多論文的發表也增加了「它們之中至少有一篇包含重要創新」的可能性。一個颠覆性的全新想法可以動搖現狀,将人們的注意力從以往工作中吸引過來,并獲得大量的新引用。
領域内流行的政策很好地反映了這種多多益善的觀點。人們會根據學者的生産力對他們進行評估和獎勵,一段時間内發表更多的論文是他們獲得終身教職和職位晉升的最可靠途徑。數量仍是大學和公司展開比較的标杆,其中發表作品、專利、科學家和經費的總量仍是重中之重。
品質也主要通過數量進行判斷。被引次數用來衡量一個領域内個人、團隊和學術期刊的重要性。在論文層面,人們往往假定最好和最優價值的論文會吸引更多的關注,進而塑造了該領域的研究軌迹。
在文中,他們預測,當每年發表論文的數量非常大時,新論文的快速流動會迫使學界關注那些被廣泛引用的論文,由此減少了對不太成熟的論文的關注,即使它們當中有些提出了新穎、有用和具有潛在變革性的想法。大量新發表論文的出現并沒有引起領域範式的更快更疊,反而鞏固了那些高引用量的論文,阻止新工作成為被引用最多且廣為人知的領域經典之作。
研究者通過實驗分析驗證了這些觀點,表明了科研機關對數量的關注可能阻礙基礎性進步。随着每個領域每年所發表作品的持續增長,這種不利影響将加劇。并且,考慮到推動「發表數量至上」領域認知的根深蒂固、錯綜複雜的結構,這種情況将不可避免。重構科學生産力價值鍊的政策措施需要進行調整,以使大衆重新聚焦于那些有潛力的新想法。
這篇文章主要講了啥?
本文重點研究了領域大小,即給定的一年内某個領域發表論文數量的多少産生的影響。以往的研究發現,很多學科的引用不平等現象正在加劇,至少部分受到了偏好的影響。然而,一篇論文往往無法在過去幾年保持它們的引用水準和排名。颠覆性論文能夠取代以往的工作,被引次數的自然波動也會影響論文排名。
因而,研究者預測,當領域足夠大時,變革動力會出現變化。引用最多的論文将根深蒂固,在未來獲得不成比例的引用量。新論文無法通過偏好依附積累引用數,也就不可能成為經典。新發表的論文很少能夠對已成型的學術桎梏産生影響。
他們給出了支撐以上預測的兩個機制。一方面,當一個領域短時間内發表了很多論文時,學者不得不訴諸于啟發式方法來對該領域進行持續性的了解。認知超載的評審人和讀者在讀新論文時不考慮裡面的新想法,隻會将它們與現有的範例論文聯系起來。不符合現有模式的新想法有極大可能不會被發表、閱讀或引用。
面對這種變革動力,論文作者不得不牢牢地将他們的工作與知名論文聯系起來。這些知名論文充當起了「知識徽章」,界定了如何了解新工作,不鼓勵他們研究太過新穎且不易于與現有經典之作聯系起來的想法。這樣一來,突破性新想法的産生以及被發表和廣泛閱讀的機率下降,并且每一篇新論文的發表也将不成比例地增加高被引論文的引用量。
另一方面,如果新想法的到來速度太快,它們之間的競争可能會阻礙任何新想法在領域内廣為人知和廣泛接受。至于為什麼會這樣呢?研究者以某個領域中傳播想法的沙堆模型為例進行解讀。
當沙子慢慢落在沙堆上時,一次一粒,等到沙堆運動停止時再落下一粒。随着時間推移,沙堆達到了無标度臨界狀态,其中一粒沙子都能夠引起整個沙堆區域的崩塌。但當沙子以極快的速度落下時,相鄰的小型崩塌會互相幹擾,導緻任何一粒沙子都無法觸發沙堆範圍内的位移。這意味着,沙子掉落的速度越快,每個新沙粒能夠影響的區域就越小。論文也一樣,如果論文出現的速度太快,則任何一篇新論文都無法通過局部擴散和偏好依附成為經典。
這兩方面的論點衍生出了六個預測,其中兩個分别是最高引的論文将長期處于主導地位以及新發表論文的徒勞無功和它們自身颠覆性的降低。
總之,相較于一個領域每年發表的論文很少,當該領域每年産出的論文很多時,則将面臨以下六種情況:
新論文将更有可能引用最高引的論文而不是低引用的論文;
每年最高引的論文清單幾乎不會出現變化,導緻經典論文始終是那些;
一篇新論文成為經典之作的機率将下降;
進入高引用論文清單的新論文不會通過循序累積的傳播方式實作;
新發表論文中發展現有科研想法的比例增加,而颠覆現有想法的比例下降;
一篇新論文成為颠覆性工作的機率降低。
用到了哪些資料與方法?
研究者使用 Web of Science 資料集,分析了1960 至 2014 年間發表的論文,共計 90,637,277 篇論文和 1,821,810,360 個引用。Web of Science 将學術領域,或者某些情況下大的子領域,劃分為不同的學科。是以,研究者的分類中共有 241 個學科,并将它們作為領域級分析的基礎。其中,一篇焦點論文每年從同一主題新發表論文中收到的被引次數構成了研究者主要的興趣變量。
為了計算 10 個最大的非綜合學科(non-multidisciplinary)學科的 1-decay rate(λ),對于每個學科,研究者以發表論文數量的 10 log 劃分年份,截點分别為 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5 和 5.5,并以 field-year 中被引最多的百分位劃分論文年份,截點分别為 1, 2, 3, …, 100。對于每個(發表論文的記錄數量)×(引用數百分位),他們将第二年一篇論文的被引次數回歸到焦點年份論文的被引次數。這一回歸的系數産生 1-λ。
此外,為了計算所有學科的 1-λ(圖下圖 2D 所示),研究者選取了第 1、2、5、10 和 25 個百分位數中被引最多的前 100 篇論文。他們通過發表論文數量的 base 10 log(截點分别為 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5 和 5.5)對 subject-years 進行分類。對于每個 bin× 選取的百分位,研究者将第二年一篇論文的被引次數回歸到焦點年份論文的被引次數。這一回歸的系數産生 1–λ。
這些預測得到證明了嗎?
研究者的所有預測都在 Web of Science 資料集的引用模式中得到了證明,具體如下圖 1 至 4 所示。随着領域變得越來越多,被引次數最多的論文始終成為主導,在引用分布上占據絕對優勢。相比之下,新論文成為高引的可能性降低,并且無法随時間推移而逐漸累積關注度。發表論文往往在發展現有想法,而不具備颠覆性,也很少能夠産生具有開拓性的新的研究潮流。
具體而言,被引次數最多的論文在更大的領域獲得了不成比例的更高的引用份額。最大領域引用份額的基尼系數約為 0.5,如下圖 1A 所示。高引論文不成比例的被引次數又導緻不平等關注的加劇。
例如,當電氣與電子工程領域每年發表 10,000 篇論文左右時,前 0.1% 和前 1% 高被引論文占了總被引次數的 1.5% 和 8.6%。當該領域每年發表 50,000 篇論文時,前 0.1% 和前 1% 高被引論文占了總被引次數的 3.5% 和 11.9%。當該領域規模更大,每年發表 100,000 篇論文時,前 0.1% 和前 1% 高被引論文占了總被引次數的 5.7% 和 16.7%。
相比之下,排名最後 50% 的被引最少論文在總被引次數中所占份額下降,每年發表 10,000 篇論文時的占比為 43.7%,每年發表論文達到 50,000 和 100,000 時,這一比例僅略高于 20%。
當跨越時間檢視領域資料時,我們會發現存在這樣的模式:當每年發表的論文數量較多時,被引用最多的 top-50 論文之間的排名相關性增加(圖. 1B)。在随後幾年斯皮爾曼排名相關性中,在一個領域中被引用最多的 top-50 清單從發表 1,000 篇論文時的 0.25 增加到 100,000 篇論文時的 0.74。
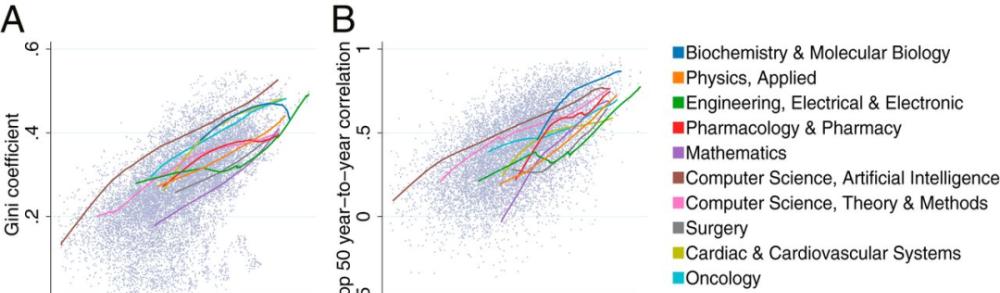
圖 1
當領域範圍很廣時,被引用最多的論文的被引次數保持逐年增長,而所有其他論文的被引次數都會下降。下圖 2 為論文當年與上一年被被引次數的預測比率。在論文發表很少的年份,被被引次數最多的論文的比率明顯低于 1,與被被引次數較少的論文的比率沒有太大差別。然而,在發表論文數量較多的年份,被被引次數最多的論文的比率接近 1,明顯高于被被引次數少的論文。
在非常大的領域年中,發表了大約 100,000 篇論文,平均而言,被引用最多的論文的被引次數沒有逐年下降。相比之下,排名在 top 1% 之外的論文,平均每年損失約 17% 的被引次數,而處于 top 5% 及以下的論文則趨向于每年損失 25% 的被引次數。

圖 2
當同一領域同時發表許多論文時,單篇論文的引用量達到 top 0.1% 的可能性會減少,這種現象在同一年的不同領域或不同年的同一領域都适用,如圖 3A 所示。一般來說,較大領域論文被引用最多,很少是通過局部擴散等過程完成。
圖 3B 顯示了一篇文章進入相關領域的平均時間(以年為機關),條件是該論文成為該領域中被引次數最多的論文之一。當一個領域很小時,論文會随着時間的推移緩慢上升到被被引次數最多的 top 0.1%。我們以 1980 年在小領域(回歸預測)發表的論文為例,假如同一領域發表了 1000 篇論文,想要成為被引用最多的論文,平均需要 9 年時間。相比之下,在最大領域經典論文會迅速登上引用榜首,這與學者通過閱讀他人著作中引用的參考資料發現新著作的累積過程不一緻。同樣的回歸預測,在每年發表 100,000 篇論文的大領域中,論文達到引用量 top 0.1% 的時間平均不到一年。
圖 3
同一年發表的大多數論文都建立在現有文獻的基礎上,而不是中斷(disrupt)現有文獻(圖 4A)。邏輯拟合預測顯示,當該領域一年發表 1,000 篇論文時,49% 的論文具有中斷度量(disruption measure) D > 0(相反,51% D0 時,新發表論文的中斷度量在更大的領域中也會減弱。圖 4B 顯示了按領域年排列的新論文比例,這些論文在中斷度量的 top-5 百分位中排名。Lowess 估計顯示,具有 top-5 百分位中斷度量的新論文比例從該領域年發表的 1,000 篇論文時的 8.8% 減少到每年 10,000 篇論文時的 3.6% 和 100,000 篇論文時的 0.6%。
圖 4
使用 NVIDIA Riva 快速建構企業級 ASR 語音識别助手
NVIDIA Riva 是一個使用 GPU 加速,能用于快速部署高性能會話式 AI 服務的 SDK,可用于快速開發語音 AI 的應用程式。Riva 的設計旨在幫助開發者輕松、快速地通路會話 AI 功能,開箱即用,通過一些簡單的指令和 API 操作就可以快速建構進階别的語音識别服務。該服務可以處理數百至數千音頻流作為輸入,并以最小延遲傳回文本。
12月29日19:30-21:00,本次線上分享主要介紹:
自動語音識别簡介
NVIDIA Riva介紹與特性
快速部署NVIDIA Riva
啟動NVIDIA Riva用戶端快速實作語音到文字的轉錄
使用Python快速搭建基于NVIDIA Riva自動語音識别服務應用