端 到 端 神 經 機 器 翻 譯(End-to-End NeuralMachine Translation)是從 2013 年興起的一種全新機器翻譯方法,其基本思想是使用神經網絡直接将源語言文本映射成目智語言文本。與統計機器翻譯不同,不再有人工設計的詞語對齊、短語切分、句法樹等隐結構(latent structure),不再需要人工設計特征,端到端神經機器翻譯僅使用一個非線性的神經網絡便能直接實作自然語言文本的轉換。
英 國 牛 津 大 學 的 Nal Kalchbrenner 和 PhilBlunsom 于 2013 年首先提出了端到端神經機器翻譯[10] 。他們為機器翻譯提出一個“編碼 - 解碼”的新架構:給定一個源語言句子,首先使用一個編碼器将其映射為一個連續、稠密的向量,然後再使用一個解碼器将該向量轉化為一個目智語言句子。Kalchbrenner 和 Blunsom 在論文中所使用的編碼器是卷積神經網絡(Convolutional NeuralNetwork),解碼器是遞歸神經網絡(RecurrentNeural Network)。使用遞歸神經網絡具有能夠捕獲全部曆史資訊和處理變長字元串的優點。這是一個非常大膽的新架構,用非線性模型取代統計機器翻譯的線性模型;用單個複雜的神經網絡取代隐結構流水線;用連接配接編碼器和解碼器的向量來描述語義等價性;用遞歸神經網絡捕獲無限長的曆史資訊。然而,端到端神經機器翻譯最初并沒有獲得理想的翻譯性能,一個重要原因是訓練遞歸神經網絡時面臨着“梯度消失”和“梯度爆炸”問題。是以,雖然遞歸神經網絡理論上能捕獲無限長的曆史資訊,但實際上難以真正處理長距離的依賴關系。
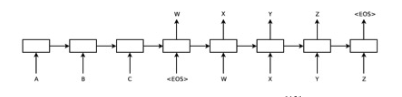
為此,美國 Google 公司的 Ilya Sutskever 等人 于 2014 年 将 長 短 期 記 憶(Long Short-TermMemory) [11] 引入端到端神經機器翻譯[12] 。長短期記憶通過采用設定門開關(gate)的方法解決了訓練遞歸神經網絡時的“梯度消失”和“梯度爆炸”問題,能夠較好地捕獲長距離依賴。圖 2 給出了Sutskever 等人提出的架構。與 Kalchbrenner 和Blunsom 的工作不同,無論是編碼器還是解碼器,Sutskever 等人都采用了遞歸神經網絡。給定一個源語言句子“A B C”,該模型在尾部增加了一個表示句子結束的符号“〈EOS〉”。當編碼器為整個句子生成向量表示後,解碼器便開始生成目智語言句子,整個解碼過程直到生成“〈EOS〉”時結束。需要注意的是,當生成目智語言詞“X”時,解碼器不但考慮整個源語言句子的資訊,還考慮已經生成的部分譯文(即“W”)。由于引入了長短期記憶,端到端神經機器翻譯的性能獲得了大幅度提升,取得了與傳統統計機器翻譯相當甚至更好的準确率。然而,這種新的架構仍面臨一個重要的挑戰,即不管是較長的源語言句子,還是較短的源語言句子,編碼器都需将其映射成一個次元固定的向量,這對實作準确的編碼提出了極大的挑戰。
針對編碼器生成定長向量的問題,YoshuaBengio 研究組提出了基于注意力(attention)的端到端神經網絡翻譯[13] 。所謂注意力,是指當解碼器在生成單個目智語言詞時,僅有小部分的源語言詞是相關的,絕大多數源語言詞都是無關的。例如,在圖 2 中,當生成目智語言詞“money”時,實際上隻有“錢”是與之密切相關的,其餘的源語言詞都不相關。是以,Bengio 研究組主張為每個目智語言詞動态生成源語言端的上下文向量,而不是采用表示整個源語言句子的定長向量。為此,他們提出了一套基于内容(content-based)的注意力計算方法。實驗表明,注意力的引入能夠更好地處理長距離依賴,顯著提升端到端神經機器翻譯的性能[14] 。
雖然端到端神經機器翻譯近年來獲得了迅速的發展,但仍存在許多重要問題有待解決。
● 可解釋性差:傳統的統計機器翻譯在設計模型時,往往會依據語言學理論設計隐結構和特征。端到端神經網絡翻譯重在設計神經網絡架構。但是由于神經網絡内部全部是向量,從語言學的角度來看可解釋性很差,如何根據語言學知識設計新架構成為挑戰,系統調試也困難重重。
● 訓練複雜度高:端到端神經機器翻譯的訓練複雜度與傳統統計機器翻譯相比具有數量級上的提升,必須使用較大規模的 GPU 叢集才能獲得較理想的實驗周期。是以,計算資源成為開展端到端神經機器翻譯研究的最大門檻。
![吳恩達logistic回歸實作[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)