非聚集索引,這個是大家都非常熟悉的一個東西,有時候我們由于業務原因,sql寫的非常複雜,需要join很多張表,然後就淚流滿面了。。。這時候就
有DBA或者資深的開發給你看這個猥瑣的sql,通過執行計劃一分析。。。或許就看出了不該有的表掃描。。。萬惡之源。。。然後給你在關鍵的字段加上非
聚集索引後。。。才發現提速比阿斯頓馬丁還要快。。。那麼一個問題來了,為什麼非聚集索引能提速這麼快。。。怎麼做到的???是不是非常的好奇???
這篇我們來解開神秘面紗。
一:現象
先讓我們一睹非聚集索引的真容,看看到底在執行計劃看來是個什麼玩意。。。我這裡有個product表,裡面灌了8w多資料,然後在Name列上建立
一個非聚集索引,就像下圖一樣:
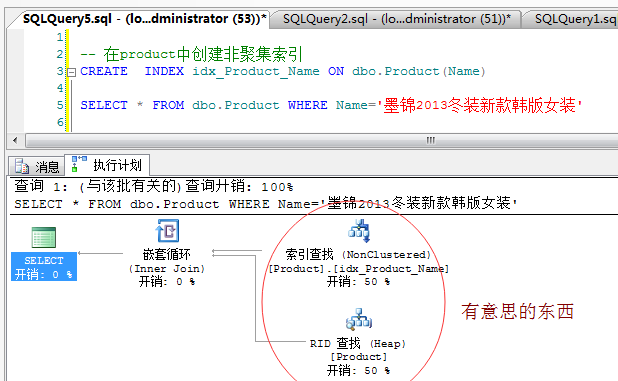
從上圖中看到了兩個好玩的東西,一個就是我想看到的“索引查找[nonclustered]”,這個大家很熟悉,也是這篇要說的,然後我們還看到了一個“RID查找”,
乍一看這是什麼雞巴玩意。。。非聚集索引跟它扯上什麼關系了???
二:什麼是RID
通過前面幾篇,我想大家都知道了資料頁中的記錄是如何尋找的?秘密就是通過slot槽位中的偏移量決定的,那問題來了,如果上升到資料頁層面,我
隻需要(pageID:slotID)就可以找到記錄了,對不對?那如果我上升了檔案層面,那是不是隻需要知道(fileID:pageID:slotID)就可以找到資料頁中的
記錄了?其實這裡的RID就是站在檔案的高度通過(fileID:pageID:slotID)找到表記錄的。。。既RID=RowID=(fileID:pageID:slotID),如果你非要眼見
為實的話,在sq中l還真提供了這麼個函數(sys.fn_PhysLocFormatter(%%physloc%%)),我們看下圖:

看了上面的圖,是不是很興奮,一目了然,比如productID=18088這條記錄,然來是在1号檔案,34941号資料頁,0号槽位上,productID=18089
是在1号槽位上,好了,當你知道RID是個什麼東西的時候,我想你已經離徹底了解非聚集索引不遠啦。。。
三:非聚集索引
有一點我們肯定知道,就是非聚集索引是可以加速查找的,要是跟表掃描那樣的龜速,那也就失去了索引的目的,既然能加速,是因為它和聚集索
引一樣,在底層都玩起了B樹,首先我們插入一些樣例資料。
上面的sql,我故意在Name列設定為900個char,這也是索引的上限值,這樣的話,我DBCC就可以導出很多資料頁和索引頁了。
可以看到,當我dbcc ind 的時候,發現Person表中已經有4個資料頁,5個索引頁,其中151号資料頁是表跟蹤頁,174号為索引跟蹤頁,這也就
說明當我建立索引後,引擎給我們配置設定了專門的索引頁來存放我們建立的Name索引,那下一步就是我們來看看這些索引中都存放着什麼,這也是我
非常關心的,接下來我導出173号索引頁。
從上面至少可以發現三個有趣的現象:
<1>:173号索引頁中slot0和slot1槽位指向記錄的内容已經有序了,比如:aaaaa,bbbbb。。。。這樣。。。。原來非聚集索引也是有序呀。。。
<2>:6161616161就是16進制的aaaaa。
9400000001000000 :這幾個數字非常重要,因為是16進制表示,是以2位16進制表示一個位元組,是以可以這麼解釋,前面4個位元組表示
pageID,中間2個位元組表示fileID,後面2個位元組表示slot,看到這裡你是不是想起了RID。。。因為RID就是這三樣的組合。。。原來非聚集索
引的記錄存放的就是“key+RowID”呀。。。。
<3>:通過最後的槽位清單,可以得知173号索引頁上存放着8條索引記錄。
好了,看完了葉子節點,我們再看分支節點,也就是IndexLevel=1的那條索引資料頁,也就是78号。ok,dbcc看看吧。
當看到這個清單的時候,不知道你腦子裡面是不是有一幅圖出來了,就像上一篇看到聚集索引一樣,因為它的結構和聚集索引非常像,隻不過
非聚集索引這裡多了一個RID而已。。。最後我也把圖貢獻一下。
總結一下:在走非聚集索引的時候,比如你的條件是where name='jjjjj' 時,它的邏輯是這樣的,根據78号索引資料頁的key的範圍,然後通過
rowid走到了79号索引資料頁,然後在79号索引資料頁中順利的找到了jjjjj,這時候就可以拿出jjjjj的rowid去表資料頁中直接定位記錄,
最後輸出。。。。。這個也就是部落格開頭的地方為什麼會出現RID的查找。。。