本节书摘来自华章计算机《spark与hadoop大数据分析》一书中的第2章,第2.1节,作者:文卡特·安卡姆(venkat ankam) 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
apache hadoop 是一个软件框架,可以在具有数千个节点和 pb 级数据的大型集群上进行分布式处理。apache hadoop 集群可以使用故障率一般较高的低价通用硬件来构建。hadoop 的设计能够在没有用户干预的情况下优雅地处理这些故障。此外,hadoop 采用了让计算贴近数据(move computation to the data)的方法,从而显著降低了网络流量。它的用户能够快速开发并行的应用程序,从而专注于业务逻辑,而无需承担分发数据、分发用于并行处理的代码以及处理故障等繁重的工作。apache hadoop 主要包含四个项目:hadoop common、hadoop 分布式文件系统( hadoop distributed file system,hdfs)、yarn(yet another resource negotiator)和 mapreduce。
简而言之,hdfs 用于存储数据,mapreduce 用于处理数据,yarn 则用来管理集群的资源(cpu 和内存)及支持 hadoop 的公共实用程序。apache hadoop 可以与许多其他项目集成,如 avro、hive、pig、hbase、zookeeper 和 apache spark。
hadoop 带来的主要是以下三个组件:
可靠的分布式数据存储框架:hdfs
用于并行处理数据的框架:mapreduce、crunch、cascading、hive、tez、impala、pig、mahout、spark 和 giraph
用于集群资源管理的框架:yarn 和 slider
让我们来了解一下 hadoop 在经济、业务和技术领域应用的驱动因素:
经济:每tb的处理成本低于商业解决方案。这是因为它的开源软件和低价通用硬件。
业务:大规模存储并处理所有数据的能力产生了更高的业务价值。
技术:存储并处理任何种类、容量、速度和真实性(大数据的所有四个v:variety、volume、velocity和veracity)的大数据的能力。
hadoop 的典型特点如下所示:
通用:hadoop 可以利用本地的低价通用硬件或任何云服务进行安装。
健壮性:它可以在软件层处理硬件故障而无需用户干预,也能在无需用户干预的情况下优雅地处理故障。
可扩展:它可以支持新节点向外扩展,以增加集群的容量。
简单:开发人员可以只专注于业务逻辑,而无需关注可扩展性、容错和多线程。
数据的局部性:数据大小高达 pb,而代码大小高达数kb字节。将代码移动到数据区块所在的节点,能够显著减少网络上的流量。
2.1.1 hadoop 分布式文件系统
hdfs 是一种分布式文件系统,能在低价通用硬件的大型集群上提供很高的可扩展性和可靠性。
hdfs 文件会划分为大区块分布在集群中,每个区块的大小通常为 128 mb。每个区块都会被复制(通常是 3 份),以便处理硬件故障以及管理节点(namenode)体现的区块布局,并通过 mapreduce 框架把计算转移到数据上,如图2-1所示。
在图2-1中,当存储 file1 时,由于其大小(100 mb)小于默认块大小(128 mb),因此它被划分在单个区块(b1)中,并且在节点 1、节点 2 和节点 3 上被复制。区块 1(b1)被复制在第一个节点(节点 1)上,然后节点 1 复制到节点 2 上,节点 2 再复制到节点 3 上。由于 file2 的大小(150 mb)大于块大小,所以 file2 被分成两个区块,然后区块 2(b2)和区块 3(b3)都会在三个节点( b2 复制到节点 1、节点 3 和节点 4,b3 复制到节点 1 、节点 2 和节点 3 )上进行复制。区块的元数据(文件名、区块、位置、创建的日期和大小)会存储在管理节点中,如上图所示。hdfs 具有较大的区块大小,从而减少了读取完整文件所需的磁盘寻道次数。
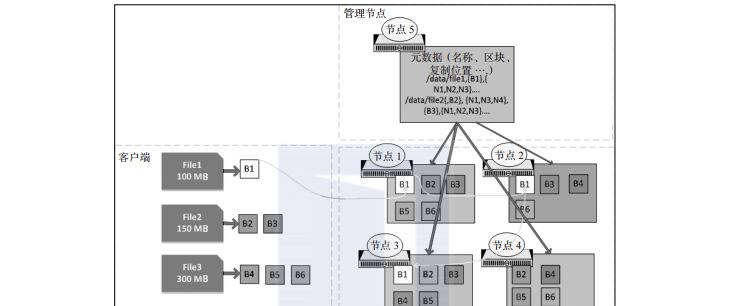
图2-1 hdfs 架构
这样创建出的某个文件对用户来说似乎像是单个文件。不过,它是作为区块存储在数据节点上,还有元数据存储在管理节点中。如果我们由于任何原因丢失了管理节点,存储在数据节点上的区块就会变得无用,因为没有办法识别属于该文件名的区块。因此,创建管理节点的高可用性和元数据的备份在任何 hadoop 集群中都是非常重要的。
2.1.2 hdfs 的特性
hdfs 正在成为标准的企业级大数据存储系统,因为它具有无限的可扩展性,同时提供了企业级大数据应用所需的大多数功能。下表列出了 hdfs 的一些重要特性:

2.1.3 mapreduce
mapreduce(mr)是一个框架,用于针对存储在 hdfs 上的 tb 级或 pb 级数据编写批量处理模式的分析应用程序。mr任务通常会利用映射器任务以并行方式处理 hdfs 中的输入文件的每个区块(不包括复制的副本)。mr 框架对映射器的输出进行排序和混排,并将其汇总到化简器任务,从而产生输出。该框架负责计算所需任务的数量、调度任务、监控它们,并在出现故障时重新执行它们。开发人员只需要专注于编写业务逻辑,所有繁杂的工作都由 hdfs 和 mr 框架完成。
例如,在图2-1 中,如果提交了一个处理 file1 的 mr 任务,则将创建一个映射器任务并在节点1、2 或 3 的其中任何一个运行,以实现数据的本地化。对于 file2 的处理,会根据资源的可用性创建两个映射器任务,其中映射器任务 1 会在节点 1、3 或 4 上运行,而映射器任务 2 在节点 1、2 或 3 上运行。映射器的输出会被排序和混排后交给化简器任务。默认情况下,化简器的数量为 1。但是,化简器任务的数量也可以增加,这样就可以在化简器的级别进行并行处理。
2.1.4 mapreduce 的特性
mr为你提供了构建大数据应用程序所需的卓越功能。下表描述了 mr 的主要特性和技术,如排序和连接(join):
2.1.5 mapreduce v1与mapreduce v2对比
apache hadoop 的 mapreduce 是一个核心处理引擎,它支持大规模数据负载的分布式处理。mr 已经在 hadoop 0.23 版本中进行了彻底的改造,现在称为 mapreduce 2.0(mr v2)或 yarn。
mapreduce v1 也称为经典 mapreduce,它有三个主要组成部分:
用来开发基于 mr 的应用程序的一套 api
用来执行映射器、混排数据和执行化简器的一个框架
用于调度和监视资源的一个资源管理框架
mapreduce v2 也称为 nextgen,它把资源管理转移到了 yarn,如图2-2 所示。
mapreduce v1 面临的挑战
mapreduce v1 面临三个挑战:
在集群上为 map 和 reduce 分别配置的 cpu 资源不够灵活,导致集群利用率不高
图2-2 mapreduce v1 对比 mapreduce v2
下表显示了 v1 和 v2 之间的差异:
2.1.6 yarn
yarn 是一套资源管理框架,它让企业能够同时以多种方式处理数据,对共享的数据集进行批处理、交互式分析或实时分析。hdfs 为大数据提供了可扩展、具备容错能力且经济实用的存储,而 yarn 为集群提供了资源的管理。图2-3 显示了如何在 hadoop 2.0 中的 hdfs 和 yarn 框架上运行多个框架的典型情况。yarn 就像一个用于 hadoop 的操作系统,它可以高效地管理集群中的资源(cpu 和内存)。像 mapreduce 和 spark 这样的应用程序会请求 yarn 为它的任务分配资源。yarn 会在节点可用的资源总量中按照所请求的内存和虚拟 cpu 数量,在节点上分配容器。
yarn 起初的目的是将作业追踪器 jobtracker / 任务追踪器 tasktracker (它们是 mapreduce v1 的一部分)这样两个主要职责拆分为单独的实体:
资源管理器(resourcemanager)
每个应用有一个应用管理器(applicationmaster)
每个节点有一个从机节点管理器(slave nodemanager)
在节点管理器上为每个应用程序运行一个容器(container)
图2-3 hadoop 1.0 和 2.0 框架
资源管理器会追踪整个集群的资源的可用性,并在应用管理器发出请求时向应用程序提供资源。
应用管理器负责协商应用程序运行其任务所需的资源。应用管理器还跟踪并监控应用程序的进度。请注意,在 mr v1 中,这个监控功能是由任务追踪器和作业追踪器处理的,会导致作业追踪器需要重载。
节点管理器负责启动由资源管理器提供的容器,监控从机节点上的资源使用情况,并向资源管理器报告。
应用程序容器负责运行应用程序的任务。yarn 还具有可插拔的调度器(fair scheduler 和 capacity scheduler),用来控制不同应用程序的资源分配。yarn 应用程序生命周期的详细步骤如图2-4所示,图中的一个应用程序有两个资源请求:
我们对前面这个图的解释如下所示:
客户端提交 mr 或 spark 作业
yarn 的资源管理器在一个节点管理器上创建一个应用管理器
应用管理器与资源管理器协商资源
资源管理器提供资源,节点管理器创建容器,应用管理器在容器中启动任务(map、reduce 或 spark 任务)
一旦任务完成,容器和应用管理器将被终止
让我们总结以上关于 yarn 的要点:
mapreduce v2 是基于 yarn 的:
yarn 用资源管理器和节点管理器替换了 mr v1 的任务追踪器/作业追踪器体系结构
资源管理器负责调度和资源分配
应用管理器负责在容器中调度任务并监视任务
为什么用 yarn ?
更好的可扩展性
高效的资源管理
运行多个框架所需的灵活性
从用户的角度来看:
没有重大的变化—相同的api、cli和web管理界面
向后兼容 mr v1,无需任何更改
图2-4 yarn 应用程序生命周期
2.1.7 hadoop上的存储选择
xml 和 json 文件是公认的行业标准格式。那么,为什么我们不能在hadoop 上使用 xml 或 json 文件呢?xml 和 json 有许多缺点,包括以下几点:
由于把模式和数据一起存储,数据量会更大
不支持模式演进
压缩之后,文件不能在 hadoop 上进行拆分
通过网络传输数据时效率不高
当我们在 hadoop 上存储数据和构建应用程序时,会遇到一些基本问题:什么样的存储格式对我的应用程序有用?哪种压缩编解码器(codec)适合我的应用程序?hadoop 为你提供了针对不同用例而构建的各种文件格式。选择正确的文件格式和压缩编解码器可为你正在处理的用例提供最佳性能。让我们逐个讲解这些文件格式,并了解何时使用它们。
文件格式
文件格式可以划分为两类。hadoop 可以存储所有数据,无论数据存储的格式是怎样的。数据可以使用标准文件格式以原始形式存储,或存储为特殊的 hadoop 容器文件格式,这些容器文件格式在某些特定用例的场景中具有优势,因为当数据被压缩时它们仍然是可以拆分的。总体而言,有两种类型的文件格式:标准文件格式和 hadoop文件格式。
标准文件格式
结构化的文本数据:csv、tsv、xml和json文件
非结构化的文本数据:日志文件和文档
非结构化的二进制数据:图像、视频和音频文件
hadoop 文件格式:支持可拆分的压缩
基于文件的结构:
顺序文件(sequence file)
序列化的格式:
thrift
协议缓冲区(protocol buffers)
avro
列格式:
rcfile
orcfile
parquet
让我们来看一下 hadoop 文件格式的特性及其适用的用例。
顺序文件
顺序文件把数据存储为二进制的键值对。它仅支持 java 语言,不支持模式演进。即使数据是被压缩的,它也支持分拆文件。
让我们看一下顺序文件的用例:
小文件问题:平均来说,每个文件在内存中占用600字节的空间。100万个100 kb 的文件需要在管理节点上占用572 mb的主内存。此外,对应的mr作业将创建 100万个映射器。
解决方案:创建一个顺序文件,用文件名作为键,文件的内容作为值,如下表所示。在管理节点中只需要600字节的内存空间,对应的mr作业将创建762个具有128 mb区块大小的映射器:
键 值 键 值 键 值
file1.txt file1.txt 的内容 file2.txt file2.txt 的内容 filen.txt filen.txt 的内容
协议缓冲区和thrift
协议缓冲区(protocol buffer)由google开发,并于2008年开源。thrift则是由 facebook开发的,提供了比协议缓冲区更多的功能和语言支持。它们都是在通过网络发送数据时提供高性能的序列化框架。avro则是专为hadoop设计的序列化专用格式。
协议缓冲区和 thrift 的一般使用模式如下:
对 hadoop 专用的格式使用 avro,对非 hadoop 项目使用协议缓冲区和 thrift。
avro 是一种基于行的数据序列化系统,用于存储并通过网络高效地发送数据。avro 具备以下的优势:
丰富的数据结构
紧凑、快速的二进制数据格式
与任何语言都能简单集成
支持模式演进
与 hive、tez、impala、pig 和 spark 之间具备良好的互操作性
avro 的一个用例如下所示:
把数据仓库转移到hadoop:将数据转移到执行提取、转换和加载(extract, transform, and load,etl)任务的 hadoop。数据模式会频繁更改。
解决方案:用 sqoop 将数据导入为支持模式演进、占用更少存储空间和 etl 任务执行更快的 avro 文件。
parquet 是一种列格式,可以在不符合查询条件的列上跳过读写和解压缩(如果适用的话)。它在对列进行压缩方面通常也很有效,因为在同一列里的列数据比由行组成的区块中的数据更为相似。
parquet 的一个用例如下所示:
hadoop上的bi访问:用户使用商务智能(business intelligence,bi)工具(如 tableau)访问在hadoop上创建的数据集市。用户查询一律只需要几列结果。这样的查询性能比较差。
解决方案:将数据存储在parquet中,它是一种柱形格式,可以为bi查询提供高性能。
rcfile 和 orcfile
记录列文件(record columnar file,rcfile)是 hive 的首选柱形格式,提供了高效的查询处理。在 hive 0.11中引入了优化行列(optimized row columnar,orc)格式,具备比 rcfile 格式更好的压缩和效率。orcfile 具有轻量级索引,可以利用它跳过不相关的列。
orc 和 parquet文件的一个用例如下所示:
orc文件和parquet文件都是列格式,并在读取数据时跳过列和行(谓词下推)。选择orc还是parquet取决于应用的具体情况以及为项目其他组件进行集成的需求。orc的常见用例与前面描述的parquet用例相同,利用bi工具向最终用户公开数据。
压缩格式
hadoop 存储可以使用各种压缩格式。不过,如果 hadoop 存储很便宜的话,为什么还需要压缩我们的数据呢?以下列表回答了你的问题:
压缩的数据可以加速i/o操作
压缩的数据可以节约存储空间
压缩数据可以加快通过网络传输数据的速度
不过,数据压缩和解压缩会增加 cpu 时间。了解这些权衡因素对于优化在 hadoop 上运行的作业的性能非常重要。
标准压缩格式
下表显示了hadoop平台上可用的标准压缩格式:
用于压缩的推荐使用模式如下:
仅用于存储:利用 gzip(高压缩比)
用于etl任务:使用 snappy(最佳压缩比和速度)
总体而言,始终要在 hadoop 上压缩数据,以获得更好的性能。选择正确的压缩编解码器取决于压缩比与速度之间的权衡。