本節書摘來自華章計算機《spark與hadoop大資料分析》一書中的第2章,第2.1節,作者:文卡特·安卡姆(venkat ankam) 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
apache hadoop 是一個軟體架構,可以在具有數千個節點和 pb 級資料的大型叢集上進行分布式處理。apache hadoop 叢集可以使用故障率一般較高的低價通用硬體來建構。hadoop 的設計能夠在沒有使用者幹預的情況下優雅地處理這些故障。此外,hadoop 采用了讓計算貼近資料(move computation to the data)的方法,進而顯著降低了網絡流量。它的使用者能夠快速開發并行的應用程式,進而專注于業務邏輯,而無需承擔分發資料、分發用于并行處理的代碼以及處理故障等繁重的工作。apache hadoop 主要包含四個項目:hadoop common、hadoop 分布式檔案系統( hadoop distributed file system,hdfs)、yarn(yet another resource negotiator)和 mapreduce。
簡而言之,hdfs 用于存儲資料,mapreduce 用于處理資料,yarn 則用來管理叢集的資源(cpu 和記憶體)及支援 hadoop 的公共實用程式。apache hadoop 可以與許多其他項目內建,如 avro、hive、pig、hbase、zookeeper 和 apache spark。
hadoop 帶來的主要是以下三個元件:
可靠的分布式資料存儲架構:hdfs
用于并行處理資料的架構:mapreduce、crunch、cascading、hive、tez、impala、pig、mahout、spark 和 giraph
用于叢集資源管理的架構:yarn 和 slider
讓我們來了解一下 hadoop 在經濟、業務和技術領域應用的驅動因素:
經濟:每tb的處理成本低于商業解決方案。這是因為它的開源軟體和低價通用硬體。
業務:大規模存儲并處理所有資料的能力産生了更高的業務價值。
技術:存儲并處理任何種類、容量、速度和真實性(大資料的所有四個v:variety、volume、velocity和veracity)的大資料的能力。
hadoop 的典型特點如下所示:
通用:hadoop 可以利用本地的低價通用硬體或任何雲服務進行安裝。
健壯性:它可以在軟體層處理硬體故障而無需使用者幹預,也能在無需使用者幹預的情況下優雅地處理故障。
可擴充:它可以支援新節點向外擴充,以增加叢集的容量。
簡單:開發人員可以隻專注于業務邏輯,而無需關注可擴充性、容錯和多線程。
資料的局部性:資料大小高達 pb,而代碼大小高達數kb位元組。将代碼移動到資料區塊所在的節點,能夠顯著減少網絡上的流量。
2.1.1 hadoop 分布式檔案系統
hdfs 是一種分布式檔案系統,能在低價通用硬體的大型叢集上提供很高的可擴充性和可靠性。
hdfs 檔案會劃分為大區塊分布在叢集中,每個區塊的大小通常為 128 mb。每個區塊都會被複制(通常是 3 份),以便處理硬體故障以及管理節點(namenode)展現的區塊布局,并通過 mapreduce 架構把計算轉移到資料上,如圖2-1所示。
在圖2-1中,當存儲 file1 時,由于其大小(100 mb)小于預設塊大小(128 mb),是以它被劃分在單個區塊(b1)中,并且在節點 1、節點 2 和節點 3 上被複制。區塊 1(b1)被複制在第一個節點(節點 1)上,然後節點 1 複制到節點 2 上,節點 2 再複制到節點 3 上。由于 file2 的大小(150 mb)大于塊大小,是以 file2 被分成兩個區塊,然後區塊 2(b2)和區塊 3(b3)都會在三個節點( b2 複制到節點 1、節點 3 和節點 4,b3 複制到節點 1 、節點 2 和節點 3 )上進行複制。區塊的中繼資料(檔案名、區塊、位置、建立的日期和大小)會存儲在管理節點中,如上圖所示。hdfs 具有較大的區塊大小,進而減少了讀取完整檔案所需的磁盤尋道次數。
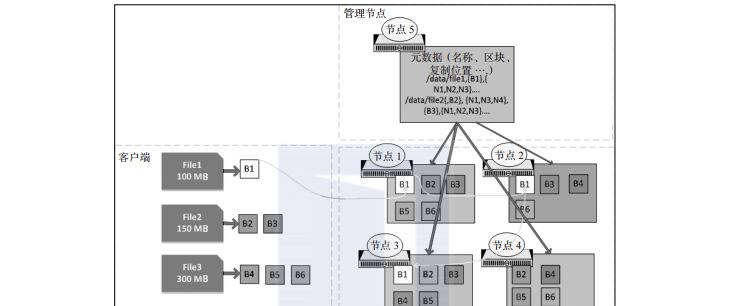
圖2-1 hdfs 架構
這樣建立出的某個檔案對使用者來說似乎像是單個檔案。不過,它是作為區塊存儲在資料節點上,還有中繼資料存儲在管理節點中。如果我們由于任何原因丢失了管理節點,存儲在資料節點上的區塊就會變得無用,因為沒有辦法識别屬于該檔案名的區塊。是以,建立管理節點的高可用性和中繼資料的備份在任何 hadoop 叢集中都是非常重要的。
2.1.2 hdfs 的特性
hdfs 正在成為标準的企業級大資料存儲系統,因為它具有無限的可擴充性,同時提供了企業級大資料應用所需的大多數功能。下表列出了 hdfs 的一些重要特性:

2.1.3 mapreduce
mapreduce(mr)是一個架構,用于針對存儲在 hdfs 上的 tb 級或 pb 級資料編寫批量處理模式的分析應用程式。mr任務通常會利用映射器任務以并行方式處理 hdfs 中的輸入檔案的每個區塊(不包括複制的副本)。mr 架構對映射器的輸出進行排序和混排,并将其彙總到化簡器任務,進而産生輸出。該架構負責計算所需任務的數量、排程任務、監控它們,并在出現故障時重新執行它們。開發人員隻需要專注于編寫業務邏輯,所有繁雜的工作都由 hdfs 和 mr 架構完成。
例如,在圖2-1 中,如果送出了一個處理 file1 的 mr 任務,則将建立一個映射器任務并在節點1、2 或 3 的其中任何一個運作,以實作資料的本地化。對于 file2 的處理,會根據資源的可用性建立兩個映射器任務,其中映射器任務 1 會在節點 1、3 或 4 上運作,而映射器任務 2 在節點 1、2 或 3 上運作。映射器的輸出會被排序和混排後交給化簡器任務。預設情況下,化簡器的數量為 1。但是,化簡器任務的數量也可以增加,這樣就可以在化簡器的級别進行并行處理。
2.1.4 mapreduce 的特性
mr為你提供了建構大資料應用程式所需的卓越功能。下表描述了 mr 的主要特性和技術,如排序和連接配接(join):
2.1.5 mapreduce v1與mapreduce v2對比
apache hadoop 的 mapreduce 是一個核心處理引擎,它支援大規模資料負載的分布式處理。mr 已經在 hadoop 0.23 版本中進行了徹底的改造,現在稱為 mapreduce 2.0(mr v2)或 yarn。
mapreduce v1 也稱為經典 mapreduce,它有三個主要組成部分:
用來開發基于 mr 的應用程式的一套 api
用來執行映射器、混排資料和執行化簡器的一個架構
用于排程和監視資源的一個資源管理架構
mapreduce v2 也稱為 nextgen,它把資源管理轉移到了 yarn,如圖2-2 所示。
mapreduce v1 面臨的挑戰
mapreduce v1 面臨三個挑戰:
在叢集上為 map 和 reduce 分别配置的 cpu 資源不夠靈活,導緻叢集使用率不高
圖2-2 mapreduce v1 對比 mapreduce v2
下表顯示了 v1 和 v2 之間的差異:
2.1.6 yarn
yarn 是一套資源管理架構,它讓企業能夠同時以多種方式處理資料,對共享的資料集進行批處理、互動式分析或實時分析。hdfs 為大資料提供了可擴充、具備容錯能力且經濟實用的存儲,而 yarn 為叢集提供了資源的管理。圖2-3 顯示了如何在 hadoop 2.0 中的 hdfs 和 yarn 架構上運作多個架構的典型情況。yarn 就像一個用于 hadoop 的作業系統,它可以高效地管理叢集中的資源(cpu 和記憶體)。像 mapreduce 和 spark 這樣的應用程式會請求 yarn 為它的任務配置設定資源。yarn 會在節點可用的資源總量中按照所請求的記憶體和虛拟 cpu 數量,在節點上配置設定容器。
yarn 起初的目的是将作業追蹤器 jobtracker / 任務追蹤器 tasktracker (它們是 mapreduce v1 的一部分)這樣兩個主要職責拆分為單獨的實體:
資料總管(resourcemanager)
每個應用有一個應用管理器(applicationmaster)
每個節點有一個從機節點管理器(slave nodemanager)
在節點管理器上為每個應用程式運作一個容器(container)
圖2-3 hadoop 1.0 和 2.0 架構
資料總管會追蹤整個叢集的資源的可用性,并在應用管理器送出請求時向應用程式提供資源。
應用管理器負責協商應用程式運作其任務所需的資源。應用管理器還跟蹤并監控應用程式的進度。請注意,在 mr v1 中,這個監控功能是由任務追蹤器和作業追蹤器處理的,會導緻作業追蹤器需要重載。
節點管理器負責啟動由資料總管提供的容器,監控從機節點上的資源使用情況,并向資料總管報告。
應用程式容器負責運作應用程式的任務。yarn 還具有可插拔的排程器(fair scheduler 和 capacity scheduler),用來控制不同應用程式的資源配置設定。yarn 應用程式生命周期的詳細步驟如圖2-4所示,圖中的一個應用程式有兩個資源請求:
我們對前面這個圖的解釋如下所示:
用戶端送出 mr 或 spark 作業
yarn 的資料總管在一個節點管理器上建立一個應用管理器
應用管理器與資料總管協商資源
資料總管提供資源,節點管理器建立容器,應用管理器在容器中啟動任務(map、reduce 或 spark 任務)
一旦任務完成,容器和應用管理器将被終止
讓我們總結以上關于 yarn 的要點:
mapreduce v2 是基于 yarn 的:
yarn 用資料總管和節點管理器替換了 mr v1 的任務追蹤器/作業追蹤器體系結構
資料總管負責排程和資源配置設定
應用管理器負責在容器中排程任務并監視任務
為什麼用 yarn ?
更好的可擴充性
高效的資源管理
運作多個架構所需的靈活性
從使用者的角度來看:
沒有重大的變化—相同的api、cli和web管理界面
向後相容 mr v1,無需任何更改
圖2-4 yarn 應用程式生命周期
2.1.7 hadoop上的存儲選擇
xml 和 json 檔案是公認的行業标準格式。那麼,為什麼我們不能在hadoop 上使用 xml 或 json 檔案呢?xml 和 json 有許多缺點,包括以下幾點:
由于把模式和資料一起存儲,資料量會更大
不支援模式演進
壓縮之後,檔案不能在 hadoop 上進行拆分
通過網絡傳輸資料時效率不高
當我們在 hadoop 上存儲資料和建構應用程式時,會遇到一些基本問題:什麼樣的存儲格式對我的應用程式有用?哪種壓縮編解碼器(codec)适合我的應用程式?hadoop 為你提供了針對不同用例而建構的各種檔案格式。選擇正确的檔案格式和壓縮編解碼器可為你正在處理的用例提供最佳性能。讓我們逐個講解這些檔案格式,并了解何時使用它們。
檔案格式
檔案格式可以劃分為兩類。hadoop 可以存儲所有資料,無論資料存儲的格式是怎樣的。資料可以使用标準檔案格式以原始形式存儲,或存儲為特殊的 hadoop 容器檔案格式,這些容器檔案格式在某些特定用例的場景中具有優勢,因為當資料被壓縮時它們仍然是可以拆分的。總體而言,有兩種類型的檔案格式:标準檔案格式和 hadoop檔案格式。
标準檔案格式
結構化的文本資料:csv、tsv、xml和json檔案
非結構化的文本資料:日志檔案和文檔
非結構化的二進制資料:圖像、視訊和音頻檔案
hadoop 檔案格式:支援可拆分的壓縮
基于檔案的結構:
順序檔案(sequence file)
序列化的格式:
thrift
協定緩沖區(protocol buffers)
avro
列格式:
rcfile
orcfile
parquet
讓我們來看一下 hadoop 檔案格式的特性及其适用的用例。
順序檔案
順序檔案把資料存儲為二進制的鍵值對。它僅支援 java 語言,不支援模式演進。即使資料是被壓縮的,它也支援分拆檔案。
讓我們看一下順序檔案的用例:
小檔案問題:平均來說,每個檔案在記憶體中占用600位元組的空間。100萬個100 kb 的檔案需要在管理節點上占用572 mb的主記憶體。此外,對應的mr作業将建立 100萬個映射器。
解決方案:建立一個順序檔案,用檔案名作為鍵,檔案的内容作為值,如下表所示。在管理節點中隻需要600位元組的記憶體空間,對應的mr作業将建立762個具有128 mb區塊大小的映射器:
鍵 值 鍵 值 鍵 值
file1.txt file1.txt 的内容 file2.txt file2.txt 的内容 filen.txt filen.txt 的内容
協定緩沖區和thrift
協定緩沖區(protocol buffer)由google開發,并于2008年開源。thrift則是由 facebook開發的,提供了比協定緩沖區更多的功能和語言支援。它們都是在通過網絡發送資料時提供高性能的序列化架構。avro則是專為hadoop設計的序列化專用格式。
協定緩沖區和 thrift 的一般使用模式如下:
對 hadoop 專用的格式使用 avro,對非 hadoop 項目使用協定緩沖區和 thrift。
avro 是一種基于行的資料序列化系統,用于存儲并通過網絡高效地發送資料。avro 具備以下的優勢:
豐富的資料結構
緊湊、快速的二進制資料格式
與任何語言都能簡單內建
支援模式演進
與 hive、tez、impala、pig 和 spark 之間具備良好的互操作性
avro 的一個用例如下所示:
把資料倉庫轉移到hadoop:将資料轉移到執行提取、轉換和加載(extract, transform, and load,etl)任務的 hadoop。資料模式會頻繁更改。
解決方案:用 sqoop 将資料導入為支援模式演進、占用更少存儲空間和 etl 任務執行更快的 avro 檔案。
parquet 是一種列格式,可以在不符合查詢條件的列上跳過讀寫和解壓縮(如果适用的話)。它在對列進行壓縮方面通常也很有效,因為在同一列裡的列資料比由行組成的區塊中的資料更為相似。
parquet 的一個用例如下所示:
hadoop上的bi通路:使用者使用商務智能(business intelligence,bi)工具(如 tableau)通路在hadoop上建立的資料集市。使用者查詢一律隻需要幾列結果。這樣的查詢性能比較差。
解決方案:将資料存儲在parquet中,它是一種柱形格式,可以為bi查詢提供高性能。
rcfile 和 orcfile
記錄列檔案(record columnar file,rcfile)是 hive 的首選柱形格式,提供了高效的查詢處理。在 hive 0.11中引入了優化行列(optimized row columnar,orc)格式,具備比 rcfile 格式更好的壓縮和效率。orcfile 具有輕量級索引,可以利用它跳過不相關的列。
orc 和 parquet檔案的一個用例如下所示:
orc檔案和parquet檔案都是列格式,并在讀取資料時跳過列和行(謂詞下推)。選擇orc還是parquet取決于應用的具體情況以及為項目其他元件進行內建的需求。orc的常見用例與前面描述的parquet用例相同,利用bi工具向最終使用者公開資料。
壓縮格式
hadoop 存儲可以使用各種壓縮格式。不過,如果 hadoop 存儲很便宜的話,為什麼還需要壓縮我們的資料呢?以下清單回答了你的問題:
壓縮的資料可以加速i/o操作
壓縮的資料可以節約存儲空間
壓縮資料可以加快通過網絡傳輸資料的速度
不過,資料壓縮和解壓縮會增加 cpu 時間。了解這些權衡因素對于優化在 hadoop 上運作的作業的性能非常重要。
标準壓縮格式
下表顯示了hadoop平台上可用的标準壓縮格式:
用于壓縮的推薦使用模式如下:
僅用于存儲:利用 gzip(高壓縮比)
用于etl任務:使用 snappy(最佳壓縮比和速度)
總體而言,始終要在 hadoop 上壓縮資料,以獲得更好的性能。選擇正确的壓縮編解碼器取決于壓縮比與速度之間的權衡。