数据量大就分表,并发高就分库。
如果是创业公司。比如注册用户20w,
每天日活1w, 每天单表1000, 高峰期每秒并发 10 ,这个时候,一般不需要考虑分库分表,如果注册用户2000w, 日活100w,
单表10w条,高峰期每秒并发1000,此时就要考虑分库分表。当然多加几台机器,使用负载均衡可以扛住,但是每天单表数据增加,磁盘资源会被消耗掉,高峰期如果要5000
怎么办,系统肯定撑不住。也就是说,数据增加,请求量增大,并发增大,单个数据库肯定不行。
如果单表数据达到 几千万了,数据量比较大,会极大影响 sql 查询性能, 后面的sql 执行会很慢,经验来说,单表数据几百万,就要考虑分表了。
所谓的分表,就是将一个表的数据存放到多个表中, 查询的时候就查一个表。比如按照用户 id 来分表,将一个用户的数据存放在一个表中,然后对这个用户操作时操作那个表就好。一般来说,每个表的数据固定在 200w 以内比较好。
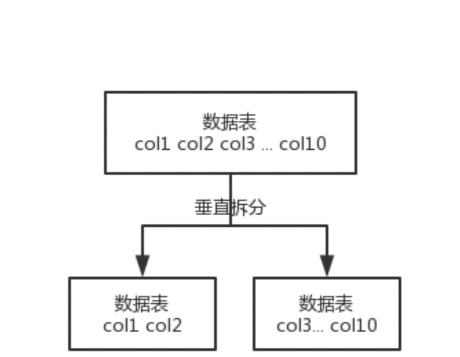
所谓的垂直拆分,就是将一个表中的列拆分到多个表中,也就是说将一个大表拆分成多个小表。
常用的列放在一个表,不常用的列放在其他表
关系紧密的列放在一个表
大字段列单独存放
在这里插入图片描述
表结构保持不变, 对数据进行拆分,将表中对某些行拆分到其他表中。

分库, 经验来说,一个库对并发最多到 2000, 一定要扩容,一个健康的单库并发控制在1000 qps 左右,如果超过,那么将一个库的数据拆分到多个库。
代表产品是 mycat, sql组合,数据库路由,执行结果合并都放到一个代理服务中。
无代码侵入性, 支持多种语言
需要额外引入中间件, 容易造成流量瓶颈
常见的有 sharing-jdbc, 业务端系统只要引入一个 jar 包即可,按照规范配置路由规则, jar 包中处理数据库路由,sql 组合,执行结果合并等操作。
简单,容易上手,引入 jar 包即可,无流量瓶颈
升级麻烦,升级 jar 包时,往往需要升级服务
数据尽量均匀等分布在不同等库或者不同表,避免数据倾斜。
跨库操作尽量少
这个字段的值不会变化。
hash 分片
range 分片(范围分片)
增量数据监听 binlog,通过 canal 增量迁移数据
全量迁移历史数据
开启双写,关闭增量迁移任务。
读业务切换到新库
线上运行一段时间,没有问题后,下线老库。
简单来说,对新库,老库都操作。要注意的是不允许老数据覆盖新数据。
如何设计可以动态扩容缩容的分库分表方案?
https://mp.weixin.qq.com/s/m6j5nixyxc8zyoghnokaba