本节书摘来自华章出版社《编译与反编译技术实战 》一书中的第3章,第3.2节,庞建民 主编 ,刘晓楠 陶红伟 岳 峰 戴超 编著,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
手工构造词法分析器首先需要将描述单词符号的正规文法或者正规式转化为状态转换图,然后再依据状态转换图进行词法分析器的构造。状态转换图是一个有限方向图,结点代表状态,用圆圈表示;状态之间用箭弧连接,箭弧上的标记(字符)代表射出结点状态下可能出现的输入字符或字符类。一张转换图只包含有限个状态,其中有一个为初态,至少要有一个终态(用双圈表示)。大多数程序语言的单词符号都可以用状态转换图予以识别。具体过程如下:
1)从初始状态出发。
2)读入一个字符。
3)按当前字符转入下一状态。
4)重复步骤2~3直到无法继续转移为止。
在遇到读入的字符是单词的分界符时,若当前状态是终止状态,说明读入的字符组成了一个单词;否则,说明输入字符串不符合词法规则。
这里我们以一个c语言子集作为例子,说明如何基于状态转换图手工编写词法分析器,该语言子集几乎包含了c语言所有的单词符号。主要步骤是,首先给出描述该子集中各种单词符号的词法规则,其次构造其状态转换图,然后根据状态转换图编写词法分析器。
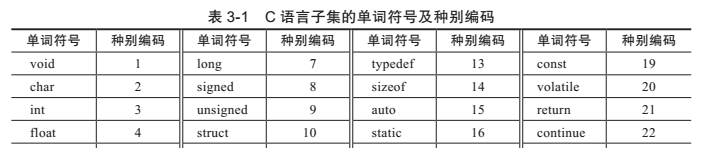
表3-1列出了这个c语言子集的所有单词符号以及它们的种别编码。该语言子集所包含的单词符号有:
1)标识符:以字母、下划线开头的字母、数字和下划线组成的符号串。
2)关键字:标识符的子集,c语言的关键字共有32个(为了测试加入了输入输出函数,共计34个)。
3)无符号十进制整数:由0到9数字组成的字符串。
4)算符和界符:“{”“}”“[”“]”“(”“)”“.”“->”“~”“++”“--”“!”“&”“*”“/”“%”“+”
“-”“<<”“>>”“>”“>=”“<”“<=”“==”“!=”“^”“|”“&&”“||”“?”“=”“/=”“*=”“%=”“+=”“-=”“&=”“^=”“|=”“,”“#”“;”“:”,共计44个。
表3-1 c语言子集的单词符号及种别编码

下面为产生该c语言子集中所涉及的单词符号的文法的产生式。
1)关键字文法:
2)标识符文法:
3)无符号整数文法:
4)算符和界符的文法:
依据上述文法可得到如图3-2所示的状态转换图。其中,终态上的星号(*)表示此时还要把超前读出的字符退回,即搜索指针回调一个字符位置。在状态2时,所识别出的标识符应先与表的前34项逐一比较,若匹配,则该标识符是一个保留字,否则就是标识符。如果是标识符,则返回相应的种别编码和标识符本身。在状态4时,将识别的常数种别编码和常数值返回。在状态7、12、16、19、23时,为了识别相应的算符需进行超前搜索。
状态转换图非常易于实现,最简单的方法是为每个状态编写一段程序。对于不含回路的分支状态来说,可以用一个switch()语句或一组if-else语句实现;对于含回路的状态来说,可以让它对应一个while语句。图3-3给出了整个词法分析器的程序设计流程图。
为便于阅读,对下面程序中所涉及的变量和过程进行以下说明:
1)ch字符变量:存放最新读入的源程序字符。
2)strtoken 字符数组:存放构成单词符号的字符串。
3)void initialization()子程序:对单词符号设定种别编码。
4)getnextchar () 子程序过程:把下一个字符读入ch中。
5)getbc()子程序过程:每次调用时,检查ch的字符是否为空白符、回车或者制表符,若是则反复调用getnextchar (),直至ch中读入一非上述符号。
6)concat()子程序过程:把ch中的字符连接到strtoken。
7)isletter()、isdigital()和isunderline布尔函数:判断ch中字符是否为字母、数字或下划线。
8)reserve_string() 整型函数:对于strtoken中的字符串判断它是否为保留字,若它是保留字则给出它的编码,否则返回0。
9)reserve_operator()整型函数:返回strtoken中所识别出的算符和界符编码。
10)retract() 子程序:把搜索指针回调一个字符位置。
11)error():出现非法字符:显示出错信息。
对应于图3-2的词法分析器构造如下: