本節書摘來自華章出版社《編譯與反編譯技術實戰 》一書中的第3章,第3.2節,龐建民 主編 ,劉曉楠 陶紅偉 嶽 峰 戴超 編著,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
手工構造詞法分析器首先需要将描述單詞符号的正規文法或者正規式轉化為狀态轉換圖,然後再依據狀态轉換圖進行詞法分析器的構造。狀态轉換圖是一個有限方向圖,結點代表狀态,用圓圈表示;狀态之間用箭弧連接配接,箭弧上的标記(字元)代表射出結點狀态下可能出現的輸入字元或字元類。一張轉換圖隻包含有限個狀态,其中有一個為初态,至少要有一個終态(用雙圈表示)。大多數程式語言的單詞符号都可以用狀态轉換圖予以識别。具體過程如下:
1)從初始狀态出發。
2)讀入一個字元。
3)按目前字元轉入下一狀态。
4)重複步驟2~3直到無法繼續轉移為止。
在遇到讀入的字元是單詞的分界符時,若目前狀态是終止狀态,說明讀入的字元組成了一個單詞;否則,說明輸入字元串不符合詞法規則。
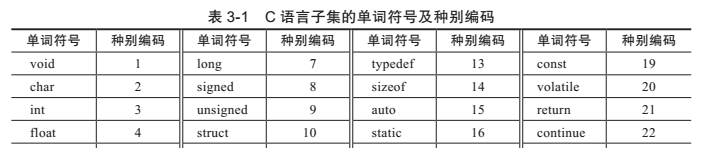
這裡我們以一個c語言子集作為例子,說明如何基于狀态轉換圖手工編寫詞法分析器,該語言子集幾乎包含了c語言所有的單詞符号。主要步驟是,首先給出描述該子集中各種單詞符号的詞法規則,其次構造其狀态轉換圖,然後根據狀态轉換圖編寫詞法分析器。
表3-1列出了這個c語言子集的所有單詞符号以及它們的種别編碼。該語言子集所包含的單詞符号有:
1)辨別符:以字母、下劃線開頭的字母、數字和下劃線組成的符号串。
2)關鍵字:辨別符的子集,c語言的關鍵字共有32個(為了測試加入了輸入輸出函數,共計34個)。
3)無符号十進制整數:由0到9數字組成的字元串。
4)算符和界符:“{”“}”“[”“]”“(”“)”“.”“->”“~”“++”“--”“!”“&”“*”“/”“%”“+”
“-”“<<”“>>”“>”“>=”“<”“<=”“==”“!=”“^”“|”“&&”“||”“?”“=”“/=”“*=”“%=”“+=”“-=”“&=”“^=”“|=”“,”“#”“;”“:”,共計44個。
表3-1 c語言子集的單詞符号及種别編碼

下面為産生該c語言子集中所涉及的單詞符号的文法的産生式。
1)關鍵字文法:
2)辨別符文法:
3)無符号整數文法:
4)算符和界符的文法:
依據上述文法可得到如圖3-2所示的狀态轉換圖。其中,終态上的星号(*)表示此時還要把超前讀出的字元退回,即搜尋指針回調一個字元位置。在狀态2時,所識别出的辨別符應先與表的前34項逐一比較,若比對,則該辨別符是一個保留字,否則就是辨別符。如果是辨別符,則傳回相應的種别編碼和辨別符本身。在狀态4時,将識别的常數種别編碼和常數值傳回。在狀态7、12、16、19、23時,為了識别相應的算符需進行超前搜尋。
狀态轉換圖非常易于實作,最簡單的方法是為每個狀态編寫一段程式。對于不含回路的分支狀态來說,可以用一個switch()語句或一組if-else語句實作;對于含回路的狀态來說,可以讓它對應一個while語句。圖3-3給出了整個詞法分析器的程式設計流程圖。
為便于閱讀,對下面程式中所涉及的變量和過程進行以下說明:
1)ch字元變量:存放最新讀入的源程式字元。
2)strtoken 字元數組:存放構成單詞符号的字元串。
3)void initialization()子程式:對單詞符号設定種别編碼。
4)getnextchar () 子程式過程:把下一個字元讀入ch中。
5)getbc()子程式過程:每次調用時,檢查ch的字元是否為空白符、回車或者制表符,若是則反複調用getnextchar (),直至ch中讀入一非上述符号。
6)concat()子程式過程:把ch中的字元連接配接到strtoken。
7)isletter()、isdigital()和isunderline布爾函數:判斷ch中字元是否為字母、數字或下劃線。
8)reserve_string() 整型函數:對于strtoken中的字元串判斷它是否為保留字,若它是保留字則給出它的編碼,否則傳回0。
9)reserve_operator()整型函數:傳回strtoken中所識别出的算符和界符編碼。
10)retract() 子程式:把搜尋指針回調一個字元位置。
11)error():出現非法字元:顯示出錯資訊。
對應于圖3-2的詞法分析器構造如下: