近日收到 平安科技 海安童鞋 那里反馈的一个问题,在生产环境使用postgresql的过程中,遇到的一个有点"不可思议"的问题。
一张经常被更新的表,通过主键查询这张表的记录时,发现需要扫描异常多的数据块。
本文将为你详细剖析这个问题,同时给出规避的方法,以及内核改造的方法。
文中还涉及到索引的结构解说,仔细阅读定有收获。
.1. 和长事务有关,我在很多文章都提到过,pg在垃圾回收时,只判断垃圾版本是否是当前数据库中最老的事务之前的,如果是之后产生的,则不回收。
所以当数据库存在长事务时,同时被访问的记录被多次变更,造成一些垃圾版本没有回收。
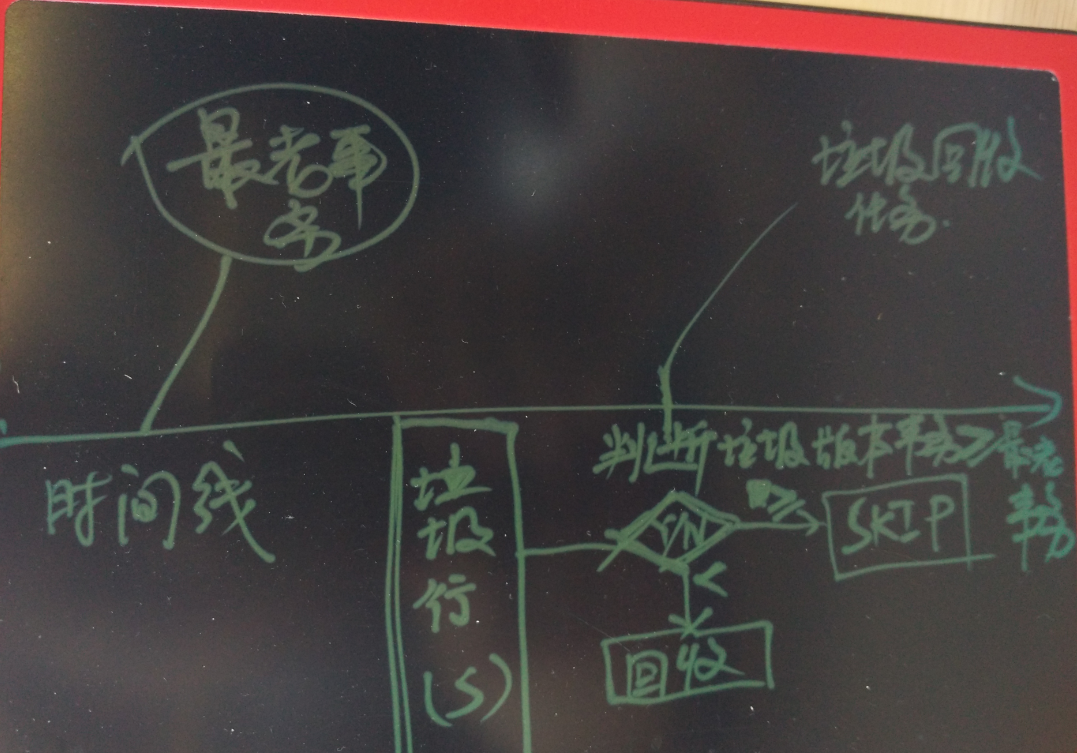
.2. pg的索引没有版本信息,所以必须要访问heap tuple获取版本。

测试表
频繁更新100条记录
开启长事务,啥也不干
经过一段时间的更新,发现需要访问很多数据块了。
观察访问很多的块是heap块
提交长事务前,使用vacuum verbose可以看到无法回收这些持续产生的垃圾page(包括index和heap的page)。
提交长事务
等待autovacuum进程回收垃圾,delete half index page。
访问的数据块数量下降了。
使用pageinspect观察测试过程中索引页的内容变化
创建extension
开启长事务
测试60秒更新
观察需要扫描多少数据块
观察索引页, root=412, 层级=2
查看root页内容
查看最左branch 页内容
查看包含最小值的最左叶子节点内容
查看包含最小值的最右叶子节点内容
查看这些叶子索引页包含data='01 00 00 00 00 00 00 00'的item有多少条,可以对应到需要扫描多少heap page
2652与前面执行计划中看到的2651对应。
等待autovacuum结束
观察现在需要扫描多少块
查看现在的索引页内容,half page已经remove掉了
再观察索引页内容,已经被autovacuum收缩了
src/backend/access/nbtree/nbtpage.c
contrib/pageinspect/btreefuncs.c
1. b-tree原理
<a href="https://yq.aliyun.com/articles/54437">https://yq.aliyun.com/articles/54437</a>
1. 频繁更新的表,数据库的优化手段
1.1 监控长事务,绝对控制长事务
1.2 缩小autovacuum naptime (to 1s) ,
1.3 如果事务释放并且表上面已经出发了vacuum后,还是要查很多的page,说明index page没有delete和收缩,可能是index page没有达到compact的要求,如果遇到这种情况,需要reindex。
2. postgresql 9.6通过快照过旧彻底解决这个长事务引发的坑爹问题。
9.6 vacuum的改进如图
如何判断snapshot too old如图
<a href="https://www.postgresql.org/docs/9.6/static/runtime-config-resource.html#runtime-config-resource-async-behavior">https://www.postgresql.org/docs/9.6/static/runtime-config-resource.html#runtime-config-resource-async-behavior</a>
3. 9.6的垃圾回收机制也还有改进的空间,做到更细粒度的版本控制,改进方法以前分享过,在事务列表中增加记录事务隔离级别,通过隔离级别判断需要保留的版本,而不是简单的通过最老事务来判断需要保留的垃圾版本。
祝大家玩得开心,欢迎随时来 阿里云促膝长谈 业务需求 ,恭候光临。
阿里云的小伙伴们加油,努力做 最贴地气的云数据库 。