另一种算法暴露在对黑人的歧视之下。最近,一位用户在Facebook上观看了一段以黑人为主题的视频后,被问及他是否"愿意继续观看灵长类动物视频"。作为回应,Facebook道歉,称这是一个"不可接受的错误",并正在调查其算法功能。
此前,Twitter和谷歌被发现歧视黑人。据悉,算法偏差与ai的核心技术之一机器学习技术有关。例如,如果机器学习使用具有来自现实世界的偏差的数据集,则算法将了解它们。换句话说,如果人工智能歧视黑人和女性,很大一部分原因是现实生活中已经存在对黑人和女性的歧视。
1 这不是黑人第一次遇到算法偏差
最近,在Facebook上观看了一名黑人男子与白人平民和警察争吵的视频后,一名用户在Facebook上收到了一个关于"他们是否愿意继续观看灵长类动物视频"的询问。该视频于去年6月27日由《每日邮报》发布,不包含与灵长类动物相关的内容。
据"纽约时报"报道,Facebook周五道歉,称其为"不可接受的错误",并表示正在调查其算法建议,以防止这种情况再次发生。Facebook发言人丹尼·利弗(Dani Lever)在一份声明中表示:"虽然我们已经改进了人工智能,但我们知道它并不完美,还有很多需要改进的地方。我们向任何可能看到这些冒犯性建议的人道歉。"
Facebook前员工达西·格罗夫斯(Darci Groves)在Twitter上发布了该推荐的截图。一些网民发布了对歧视表示愤怒的信息,而另一些人则质疑该视频是否以黑人和白人为特色,"或者将白人视为'灵长类动物'"。"
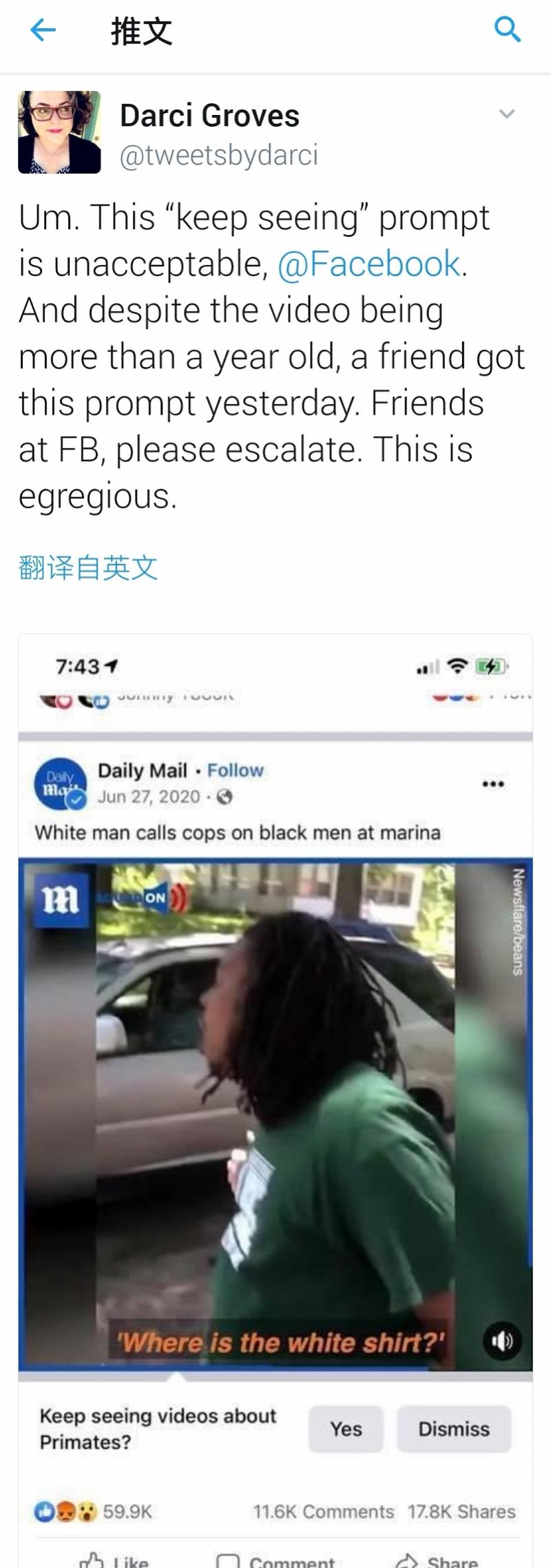
Facebook前员工Darci Groves在推特上写道。
但这并不是黑人第一次遇到算法偏见。今年五月,Twitter的研究小组发表了一篇论文,表明Twitter的缩略图算法在剪切图片时有利于白人和女性,在剪切多人照片时更有利于黑人。然后,Twitter删除了在移动应用程序上自动裁剪照片的功能,并发起了算法偏见黑客竞赛,以寻找代码中可能存在的偏见。
2015年,Google Photos还将两名黑人的照片标记为"大猩猩"。为了修复该错误,Google从搜索结果中删除了该标签,这也导致没有图片被标记为大猩猩,黑猩猩或猴子。
OpenAI在二月份发表的一篇论文用数据量化了AI系统可能的算法偏差。他们发现,一些人工智能系统将黑人识别为非人类的概率最高,为14.4%,几乎是排名第二的印度人的两倍。

根据该论文,一些人工智能系统有24.9%的机会将白人识别为与犯罪有关,14.4%的黑人识别为非人类。
2 算法了解现实社会中现有的偏见
一般来说,人工智能系统开发人员不会故意在算法中注入偏见。那么算法偏差从何而来呢?
腾讯研究院在2019年对这个问题进行了分析。他们认为这与人工智能的核心技术机器学习有关。有三个主要环节可以将偏差注入算法:数据集构建,目标设置和特征选择(工程师)以及数据标签(标记器)。
在数据集构建过程中,一方面,一些少数群体需要获得的数据较少,需要做的数据较少,因此AI的训练较少,从而进一步边缘化了算法中的少数群体。另一方面,数据集来自真实社会,现实社会中存在偏见,算法也会学习这些偏见。换句话说,如果人工智能歧视黑人和女性,很大一部分原因是现实生活中已经存在对黑人和女性的歧视。
此外,开发人员在设置目标或选择标签时可能会产生个人偏见。数据标注者在标记数据时,不仅面临着"猫或狗"这个容易判断的问题,还面临着"美或丑"的价值判断。这也可能是算法偏差的主要来源。
算法偏差具有不可知和未知的特征,这对开发人员构成了挑战。"很难在机器学习模型中找到偏见,"Twitter在今年发布的一份声明中表示。很多时候,当意想不到的道德风险被发现时,技术已经走向了公众。"
然而,算法偏见的危险正在出现。今年4月,美国联邦贸易委员会(Federal Trade Commission)警告称,如果将具有种族和性别偏见的人工智能工具用于信贷、住房或就业决策,则可能违反消费者保护法。
8月27日,国家互联网信息办公室发布了《互联网信息服务算法推荐管理条例(征求意见稿)》,探讨监管算法的弊端。值得一提的是,算法推荐服务商应遵守法律法规,尊重社会公德和伦理,加强对用户模型和用户标签的管理,不得设置歧视性或偏见性的用户标签。
撰稿:南都记者 马家璇