另一種算法暴露在對黑人的歧視之下。最近,一位使用者在Facebook上觀看了一段以黑人為主題的視訊後,被問及他是否"願意繼續觀看靈長類動物視訊"。作為回應,Facebook道歉,稱這是一個"不可接受的錯誤",并正在調查其算法功能。
此前,Twitter和谷歌被發現歧視黑人。據悉,算法偏差與ai的核心技術之一機器學習技術有關。例如,如果機器學習使用具有來自現實世界的偏差的資料集,則算法将了解它們。換句話說,如果人工智能歧視黑人和女性,很大一部分原因是現實生活中已經存在對黑人和女性的歧視。
1 這不是黑人第一次遇到算法偏差
最近,在Facebook上觀看了一名黑人男子與白人平民和警察争吵的視訊後,一名使用者在Facebook上收到了一個關于"他們是否願意繼續觀看靈長類動物視訊"的詢問。該視訊于去年6月27日由《每日郵報》釋出,不包含與靈長類動物相關的内容。
據"紐約時報"報道,Facebook周五道歉,稱其為"不可接受的錯誤",并表示正在調查其算法建議,以防止這種情況再次發生。Facebook發言人丹尼·利弗(Dani Lever)在一份聲明中表示:"雖然我們已經改進了人工智能,但我們知道它并不完美,還有很多需要改進的地方。我們向任何可能看到這些冒犯性建議的人道歉。"
Facebook前員工達西·格羅夫斯(Darci Groves)在Twitter上釋出了該推薦的截圖。一些網民釋出了對歧視表示憤怒的資訊,而另一些人則質疑該視訊是否以黑人和白人為特色,"或者将白人視為'靈長類動物'"。"
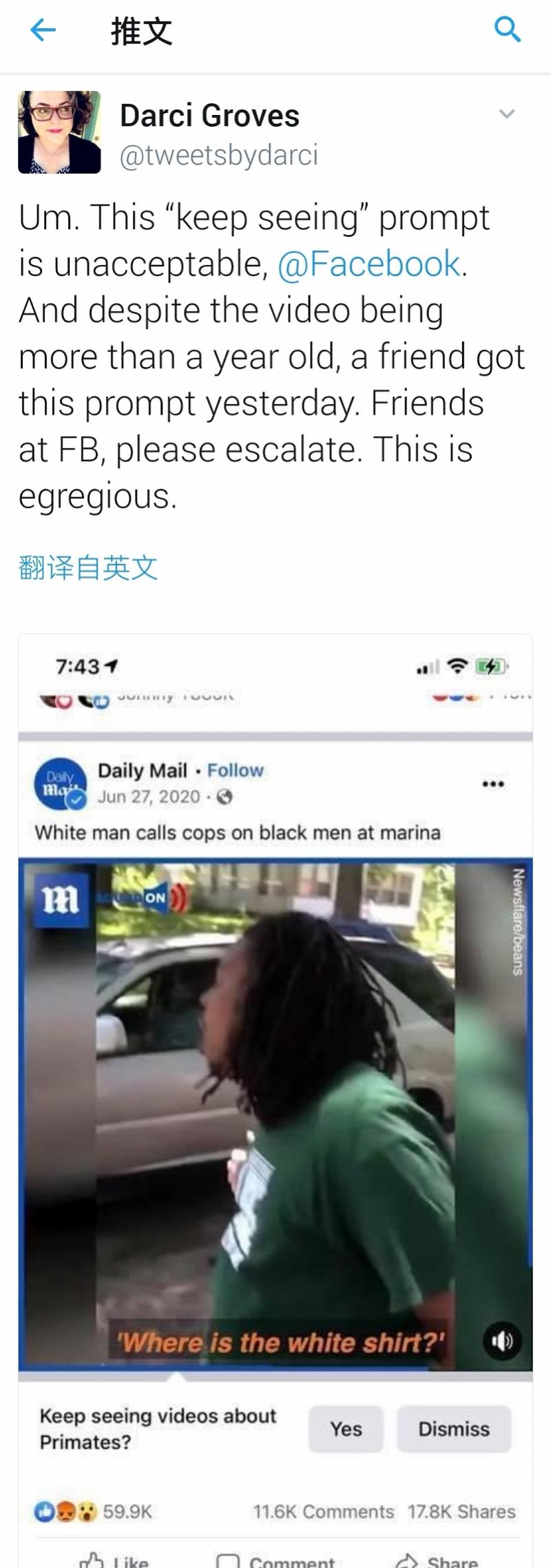
Facebook前員工Darci Groves在推特上寫道。
但這并不是黑人第一次遇到算法偏見。今年五月,Twitter的研究小組發表了一篇論文,表明Twitter的縮略圖算法在剪切圖檔時有利于白人和女性,在剪切多人照片時更有利于黑人。然後,Twitter删除了在移動應用程式上自動裁剪照片的功能,并發起了算法偏見黑客競賽,以尋找代碼中可能存在的偏見。
2015年,Google Photos還将兩名黑人的照片标記為"大猩猩"。為了修複該錯誤,Google從搜尋結果中删除了該标簽,這也導緻沒有圖檔被标記為大猩猩,黑猩猩或猴子。
OpenAI在二月份發表的一篇論文用資料量化了AI系統可能的算法偏差。他們發現,一些人工智能系統将黑人識别為非人類的機率最高,為14.4%,幾乎是排名第二的印度人的兩倍。

根據該論文,一些人工智能系統有24.9%的機會将白人識别為與犯罪有關,14.4%的黑人識别為非人類。
2 算法了解現實社會中現有的偏見
一般來說,人工智能系統開發人員不會故意在算法中注入偏見。那麼算法偏差從何而來呢?
騰訊研究院在2019年對這個問題進行了分析。他們認為這與人工智能的核心技術機器學習有關。有三個主要環節可以将偏差注入算法:資料集建構,目标設定和特征選擇(工程師)以及資料标簽(标記器)。
在資料集建構過程中,一方面,一些少數群體需要獲得的資料較少,需要做的資料較少,是以AI的訓練較少,進而進一步邊緣化了算法中的少數群體。另一方面,資料集來自真實社會,現實社會中存在偏見,算法也會學習這些偏見。換句話說,如果人工智能歧視黑人和女性,很大一部分原因是現實生活中已經存在對黑人和女性的歧視。
此外,開發人員在設定目标或選擇标簽時可能會産生個人偏見。資料标注者在标記資料時,不僅面臨着"貓或狗"這個容易判斷的問題,還面臨着"美或醜"的價值判斷。這也可能是算法偏差的主要來源。
算法偏差具有不可知和未知的特征,這對開發人員構成了挑戰。"很難在機器學習模型中找到偏見,"Twitter在今年釋出的一份聲明中表示。很多時候,當意想不到的道德風險被發現時,技術已經走向了公衆。"
然而,算法偏見的危險正在出現。今年4月,美國聯邦貿易委員會(Federal Trade Commission)警告稱,如果将具有種族和性别偏見的人工智能工具用于信貸、住房或就業決策,則可能違反消費者保護法。
8月27日,國家網際網路資訊辦公室釋出了《網際網路資訊服務算法推薦管理條例(征求意見稿)》,探讨監管算法的弊端。值得一提的是,算法推薦服務商應遵守法律法規,尊重社會公德和倫理,加強對使用者模型和使用者标簽的管理,不得設定歧視性或偏見性的使用者标簽。
撰稿:南都記者 馬家璇