python有六大数据类型:
数字型Number,其中包括int,float,bool,complex; 其余的5种数据类型均为容器类型包括: 字符串型str; 元组tuple; 列表list; 集合set; 字典dict
下面对各数据类型进行详细介绍
Number
(1)int
为整型,包括正整数,0,负整数
通过type()可以获取变量的类型,id()可以查看变量的地址
二进制整型: intvar = Ob10101
八进制整型: intvar = Oo101
十六进制整型: intvar = Ox1017a
(2)float
为浮点型,即小数.
表示方法有两种:floatvar = 0.45 科学计数法: floatvar = 4.5e-1
(3)bool
为布尔型值,只有两种:True或者False
布尔值为False的情况如下: 0, 0.0, False, 0j, [], (), set(), {}, None
(4)complex
为复数类型
两种表示方式comvar = 1+2j 或者 comvar = complex(1,2)
str
字符串类型:用单引号,双引号或三引号引起来的变量即为字符串
特点:有序,可按下标进行获取,不可修改;
相关操作:
- 字符串拼接:+
- 字符串的重复:*
- 字符串的跨行拼接
- 字符串的索引:正向,逆向
- 字符串的切片:
- [开始索引:]
- [:结束索引]
- [开始索引:结束索引]
- [开始索引:结束索引:间隔值]
- [:]或[::]
相关函数
- 字符串首字母转为大写strval.capitalize()
- 每个单词首字母转为大写: strval.tittle()
- 判断字符串是否都是大写:strval.isupper()
- 判断字符串是否小写:strval.islower()
- 判断是否以纯数字组成:isdecimal()
- 每个字母转化为大写:strval.upper()
- 每个字母转化为小写:strval.lower()
- 大小写互换:strval.swapcase()
- 计算字符串长度:len(strval)
- 统计某个字符数量:strval.count(‘m’)
-
查找某个字符串第一次出现的位置:strval.find(‘目标’,开始索引,结束索引)
找不到则返回-1
- index与find功能一样,但index找不到会直接报错
- 判断字符串是否以某个字符或字符串开头:strvar.startswith(‘jjjj’);结尾endswith()
- 填充字符串,原字符串居中,默认填充空格
strvar = '1234
strvar.center(10) # 原字符串+填充字符串长度=10
strvar.center(10,'*')
>>> ***1234***
当原字符串居左strvar.ljust(10);当原字符串居右strvar.rjust()
- 默认从字符串收尾去掉空白符:strval.strip();去掉指定字符strval.strip(’#’);当去掉左边时:lstrip();去掉右边:rstrip()
- 按照某个字符将字符串分割成列表(不指定字符则默认按照空白符进行对字符串进行分割);listval = strval.split()
- 按某个字符将列表拼接成字符串(容器类型数据都可进行拼接);strval = ‘_’.join(listvar)
- replace()把就字符替换成新字符;str1 = str2.replace(‘旧字符’, ‘新字符’, 替换的次数(默认全都替换))
-
format字符串的格式化
(1)顺序传参
(2)索引传参
(3)关键字传参
(4)容器类型数据(列表或元组)传参
(5)如果是字典传参则键不需要加引号
format填充符号的使用
^原字符串居中;<原字符串居左;>原字符串居右;
修饰要传递的关键字参数:
strval = '{who:*^10}在{where:#>10}买了大别墅'.format(who='王小凡', where='深圳湾壹号')
print(strval)
>>> ***王小凡****在#####深圳湾壹号买了大别墅
进制转换等特殊符号的使用
:d 整型占位符, :2d占用两位,不够的拿空格来补,默认居右
:f浮点型占位符;:2f保留两位小数
:s字符串占位符
:,金钱占位符 123,456,456
list
列表类型
特点:有序,可获取,可修改
列表的相关使用方法
- 列表的拼接:+
- 列表的重复:*
- 列表的切片
- 列表的获取:lst[0]
- 列表的修改:(可切片,配合步长);元组中某个元素是列表时该列表可以修改
- 列表的删除:del lst
列表的相关函数
不需要使用变量对结果来进行接收,数据在原列表上进行变动
-
增
(1)append向列表的末尾添加新元素
(2)insert在指定的索引之前添加元素
(2)extend迭代追加所有元素,要求数据的类型是可迭代的
-
删
(1)pop 通过指定索引删除元素,若无索引移除最后一个;
(2)remove 通过给予的值来删除,如果有多个相同的值,默认删除第一个;
(3)clear清空列表
lst = [3,4,5]
res = lst.pop()
print(lst, res)
>>> [3, 4] 5
-
其他
(1)index获取某个值的索引,找不到则报错lst.index(值, start, end)
(2)count计算某个元素出现的次数(不可以指定范围)
(3)reverse列表翻转操作,无返回值
(3)sort()列表排序,默认从小到大排(无返回值);第一位相同的情况下比较第二位
lst.sort(reverse = True) # 从大到小
print(lst)
tuple
元组类型(不可变数据类型),逗号是区分的关键;
特点: 有序,可获取,不可修改
方法同列表
set
集合类型
特点:无序,自动去重
dict
字典类型
特点: 无序,键不可重复
注意:字典中的键和集合中的值数据类型必须是可哈希的,即必须是不可变数据类型如:Number(int, float, bool, complex), str, tuple
字典相关方法:
-
增
(1)dic[‘a’] = ‘6788’
(2)fromkeys()使用一组键和默认值创建字典:
dic = {}
lst = [1,2,3]
dic = dic.fromkeys(lst,None) # 三个键指向的值是同一个
print(dic)
-
删
(1)pop()通过键去删除键值对(若没有该键,可设置默认值预防报错)
dic = {'a': [], 'b': 90}
res = dic.pop('a') # res为被删除的值
print(dic, res)
res = dic.pop('c', None) # 当被删除的键不存在时需要设置默认值,否则会报错
print(dic, res)
(2)popitem()删除最后一个键值对
(3)clear()清空字典
-
改
(1)update()批量更新,有该键则更新,没有则添加
dic1 = {1:34}
dic_new = {'a': 'new_world'}
# 方法一
dic1.update(dic_new)
print(dic1)
>>> {1: 34, 'a': 'new_world'}
# 方法二
dic1.update(key_word = 'my_head')
print(dic1)
>>> {1: 34, 'a': 'new_world', 'key_word': 'my_head'}
-
查
dic.get(‘aaa’) #如果没有各个键会返回None不会报错
- keys()将字典的键返回组成一个可迭代对象;
- dic.values()将字典的值返回组成一个可迭代对象
- dic.items()将字典的键值对凑成一个个元组,组成一个可迭代对象
print(dic1.items(),type(dic1.items()))
>>> dict_items([(1, 34), ('a', 'new_world'), ('key_word', 'my_head')]) <class 'dict_items'>
可变数据类型与不可变数据类型
数据类型可变与不可变与python中的内存地址相关:
1,不可变数据类型
不可变数据类型包括Number,str, tuple
a = 45
b = 45
c = b
d = b + 1
print(id(a), id(b), id(c), id(d))
>>>4556717488 4556717488 4556717488 4556717520
上述,变量a,b,c都指向了引用了同一个对象45,他们所指向的地址是相同的,变量d指向的新的对象,地址发生了改变.当没有变量引用时对象才会进行内存回收.
对于不可变数据类型,创建了该对象之后,无论多少个变量指向这个对象,地址是唯一的,当该对象的内容发生改变时相当于重新创建了一个对象,并且地址发生改变.从而可以将不可变数据类型理解为变量所引用的地址处的值是不可变的.
优点: 无论引用多少次,相同的对象只占用了一块内存;
缺点: 当需要对引用对象的值进行运算从而值发生改变时,需要创建新的对象.
2, 可变数据类型
可变数据类型包括list, dict, set
listvar1 = [1,2,3]
listvar2 = [1,2,3]
var = listvar2
print(id(listvar1), id(listvar2), id(var))
>>> 140304263987976 140304264044872 140304264044872
listvar2.append(56)
print(id(listvar2))
>>> 140304264044872
当变量listvar1,listvar2赋值是相同的列表时,他们所指向的地址不同,说明他们指向的是两个不同的对象;当针对于变量listvar2的值进行操作后,其值改变但是内存地址没有变,并没有创建新的对象而是在原有对象上进行了修改.
对于可变数据类型,可变可以理解为同一个对象(同一地址)的值可以改变,而不会重新创建对象.
python中的不可变数据类型,不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象,内部会有一个引用计数来记录有多少个变量引用这个对象;可变数据类型,允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
深拷贝和浅拷贝
(1)浅拷贝
示例: 当含有不可变数据类型时:
list1 = ['asdfg', 2, 3]
list2 = list1.copy()
print(id(list1), id(list2))
>>> 140503248118152 140503246732296
print(id(list1[0]), id(list2[0]))
>>> 140503226332416 140503226332416
list2[0] += 'hello world'
print(list1, list2)
>>> ['asdfg', 2, 3] ['asdfghello world', 2, 3]
print(id(list1[0]), id(list2[0]))
>>> 140503226332416 140503248103728
示例: 当含有可变数据类型时:
list1 = [[1,2,3], 2, 3]
list2 = list1.copy()
print(id(list1), id(list2))
>>> 140614529960968 140614531392136
print(id(list1[0]), id(list2[0]))
>>> 140614531391880 140614531391880
list2[0].append(34)
print(list1, list2)
>>> [[1, 2, 3, 34], 2, 3] [[1, 2, 3, 34], 2, 3]
print(id(list1[0]), id(list2[0]))
>>> 140614531391880 140614531391880
list2是对于list1的浅拷贝, 此时两个变量的地址不同;可以看到但其中的元素仍然指向的是相同的地址; 当对于变量list2中的第一个元素进行append操作后,可以看到,原来的list1第一个元素也发生了相应的变化,因为他们指向的是同一个地址
浅拷贝只能拷贝容器中不可变数据类型(地址暂时未变,值发生变化自然会变),而对于容器中的可变数据类型仍然指向原来的地址,当值发生改变时原来的变量也会发生相应的变化.
(2)深拷贝
深拷贝会将不可变数据类型和可变数据类型都进行拷贝, 可变数据类型的地址发生变化,不可变数据类型的地址暂时不变.
# 深拷贝
import copy
list3 = [1,2,3,[4,5,6]]
list4 = copy.deepcopy(list3)
print(id(list4[-1]))
>>> 140442270122824
list4[-1].append(9)
print(list3, id(list3[-1]))
>>> [1, 2, 3, [4, 5, 6]] 140442270122760
print(list4, id(list4[-1]))
>>> [1, 2, 3, [4, 5, 6, 9]] 140442270122824
list3的最后一个元素为可变数据类型列表,当进行深拷贝之后,在新的列表list4中该元素的地址是新开辟的一块内存地址,因而当数据发生变化不会影响原来的list3.
python的内存管理
引用计数器为主,标记清除和分代回收 + 缓存机制
1.引用计数器(为主)
1.1 环状的双向链表refrain
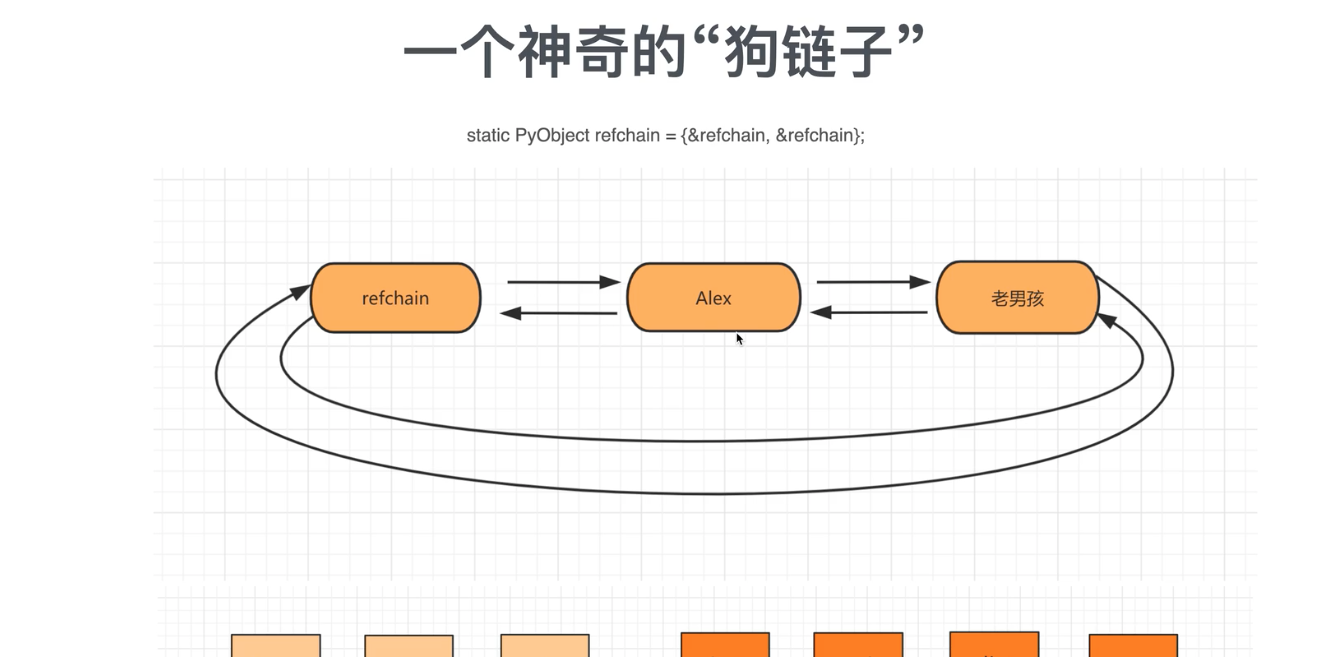
在python中创建的任何对象都会放在refchain链表中,
name = 'gdah' # 内部会创建一些数据[上一个对象,下一个对象,类型,引用个数]
new = name
age = 18 # 内部会创建一些数据[上一个对象,下一个对象,类型,引用个数, val = 18]
hobby = [1,2,3] # 内部会创建一些数据[上一个对象,下一个对象,类型,引用个数, items = 元素,元素个数]

在c源码中如何体现的每个对象都有的相同的值:PyObject结构体(4个值)
有多个元素组成的对象:PyObject结构体 + ob_size
1.2不同类型封装的结构体
data = 3.14
'''
内部会创建:
_ob_next
_ob_prev
ob_refcnt = 1
ob_type = float
ob_fval = 3.14
'''
1.3引用计数器
val1 = 3.14
val2 = 90
val3 = (4,5,6,7)
当python程序运行时,会根据数据类型的不同找到其对应的结构体,根据结构体中的字段来创建相关的数据,然后将对象添加到refchain双向链表中.
在C源码中有两个关键的结构体:PyObject,PyVarObject.
每个对象中有ob_refcnt就是引用计数器,值默认为1;当有其他变量引用对象时,引用计数器会发生变化.
- 引用
a = 90
b = a
- 删除引用
a = 90
b = a
del b # b变量删除,b对应对象引用计数器-1
del a # a变量删除,a对象引用计数器-1
# 当一个对象的引用计数器为0时,意味着没有人使用这个对象了,意味着这个对象是垃圾,进行垃圾回收
# 回收: 1.对象从refchain链表中移除 2,将对象销毁,内存归还
1.4循环引用问题
循环引用,交叉感染
v1 = [11,22,33] # refchain中创建一个列表对象,由于v1=对象,所以列表引用对象引用计数器为1.
v2 = [44,55,66] # refchain中再创建一个列表对象,该列表引用计数器为1
v1.append(v2) # 将v2追加到v1中,则v2对应的对象引用计数器加1,最终为2
v2.append(v1)
del v1 # 引用计数器-1
del v2 # 引用计数器-1
由于已经将变量v1,v2进行了del那么在程序中别的地方也无法使用这个变量,但是由于引用计数始终为1,就一直会存在于内存之中不进行回收.可能就会造成内存泄露.
标记清除
目的:为了解决引用计数器循环引用的不足.
实现: 在python的底层 再 去维护一个链表,链表中专门放那些可能存在循环引用的对象(list/tuple/dict/set).
在python内部’某种情况下’触发,回去扫描可能存在循环引用的链表中的每个元素,检查是否有循环引用,如果有则让双方的引用计数器-1;如果是0则垃圾回收.
问题:
- 什么时候扫描?
- 可能存在循环引用的链表扫描的代价大,每次扫描耗时久.
3.分代回收
将可能存在循环引用的对象维护成3个链表:
- 0代:0代中对象个数达到700个扫描一次.
- 1代:0代扫描10次,则1代扫描一次.
-
2代:1代扫描10次,则2代扫描一次.
0代中垃圾则清除,不是垃圾则升级到1代,新的对象继续加到0代…
4.小结缓存机制
在python中维护了一个refchain的双向环状链表,这个链表中存储程序创建的所有对象,每种类型的对象中都有一个ob_refcnt引用计数器的值,引用个数+1,-1,最后当引用计数器变为0时会进行垃圾回收(对象销毁,refchain中移除)
但是,在python中对于那些可以有多核元素组成的对象可能会存在循环引用的问题,为了解决这个问题python又引入了标记清除和分代回收,在其内部维护了四个链表
- refchain
- 2代,10次
- 1代,10次
-
0代,700个
在源码内部当达到各自的阈值时,就会触发扫描链表进行标记清除的动作(有循环则各自-1)
但是,源码内部在上述流程中提出了优化机制
5.Python缓存
5.1池(int)
为了避免重复创建和销毁一些常见对象,维护池.
# 启动解释器时,python内部帮我们创建:-5, -4,....257
v1 = 8 # 内存不会开辟内存,直接去池中获取
v2 = 5 # 内存不会开辟内存,直接去池中获取
5.2 free_list(float, list,tuple,dict)
当一个对象的引用计数器为0时,按理说应该回收,内部不会直接回收,而是将对象添加到free_list链表中当缓存,以后去创建对象时,不再重新开辟内存,而是直接使用free_list.
v1 = 3.14 # 开辟内存,内部存储结构体中定义那几个之后,并存到refchain中.
del v1 # refchain中移除,将对象添加到free_list中(80个),free_list满了则销毁.
v9 = 999.99 # 不会重新开辟内存,去free_list中获取对象,对象内部数据初始化,再放到refchain中.