python有六大資料類型:
數字型Number,其中包括int,float,bool,complex; 其餘的5種資料類型均為容器類型包括: 字元串型str; 元組tuple; 清單list; 集合set; 字典dict
下面對各資料類型進行詳細介紹
Number
(1)int
為整型,包括正整數,0,負整數
通過type()可以擷取變量的類型,id()可以檢視變量的位址
二進制整型: intvar = Ob10101
八進制整型: intvar = Oo101
十六進制整型: intvar = Ox1017a
(2)float
為浮點型,即小數.
表示方法有兩種:floatvar = 0.45 科學計數法: floatvar = 4.5e-1
(3)bool
為布爾型值,隻有兩種:True或者False
布爾值為False的情況如下: 0, 0.0, False, 0j, [], (), set(), {}, None
(4)complex
為複數類型
兩種表示方式comvar = 1+2j 或者 comvar = complex(1,2)
str
字元串類型:用單引号,雙引号或三引号引起來的變量即為字元串
特點:有序,可按下标進行擷取,不可修改;
相關操作:
- 字元串拼接:+
- 字元串的重複:*
- 字元串的跨行拼接
- 字元串的索引:正向,逆向
- 字元串的切片:
- [開始索引:]
- [:結束索引]
- [開始索引:結束索引]
- [開始索引:結束索引:間隔值]
- [:]或[::]
相關函數
- 字元串首字母轉為大寫strval.capitalize()
- 每個單詞首字母轉為大寫: strval.tittle()
- 判斷字元串是否都是大寫:strval.isupper()
- 判斷字元串是否小寫:strval.islower()
- 判斷是否以純數字組成:isdecimal()
- 每個字母轉化為大寫:strval.upper()
- 每個字母轉化為小寫:strval.lower()
- 大小寫互換:strval.swapcase()
- 計算字元串長度:len(strval)
- 統計某個字元數量:strval.count(‘m’)
-
查找某個字元串第一次出現的位置:strval.find(‘目标’,開始索引,結束索引)
找不到則傳回-1
- index與find功能一樣,但index找不到會直接報錯
- 判斷字元串是否以某個字元或字元串開頭:strvar.startswith(‘jjjj’);結尾endswith()
- 填充字元串,原字元串居中,預設填充空格
strvar = '1234
strvar.center(10) # 原字元串+填充字元串長度=10
strvar.center(10,'*')
>>> ***1234***
當原字元串居左strvar.ljust(10);當原字元串居右strvar.rjust()
- 預設從字元串收尾去掉空白符:strval.strip();去掉指定字元strval.strip(’#’);當去掉左邊時:lstrip();去掉右邊:rstrip()
- 按照某個字元将字元串分割成清單(不指定字元則預設按照空白符進行對字元串進行分割);listval = strval.split()
- 按某個字元将清單拼接成字元串(容器類型資料都可進行拼接);strval = ‘_’.join(listvar)
- replace()把就字元替換成新字元;str1 = str2.replace(‘舊字元’, ‘新字元’, 替換的次數(預設全都替換))
-
format字元串的格式化
(1)順序傳參
(2)索引傳參
(3)關鍵字傳參
(4)容器類型資料(清單或元組)傳參
(5)如果是字典傳參則鍵不需要加引号
format填充符号的使用
^原字元串居中;<原字元串居左;>原字元串居右;
修飾要傳遞的關鍵字參數:
strval = '{who:*^10}在{where:#>10}買了大别墅'.format(who='王小凡', where='深圳灣壹号')
print(strval)
>>> ***王小凡****在#####深圳灣壹号買了大别墅
進制轉換等特殊符号的使用
:d 整型占位符, :2d占用兩位,不夠的拿空格來補,預設居右
:f浮點型占位符;:2f保留兩位小數
:s字元串占位符
:,金錢占位符 123,456,456
list
清單類型
特點:有序,可擷取,可修改
清單的相關使用方法
- 清單的拼接:+
- 清單的重複:*
- 清單的切片
- 清單的擷取:lst[0]
- 清單的修改:(可切片,配合步長);元組中某個元素是清單時該清單可以修改
- 清單的删除:del lst
清單的相關函數
不需要使用變量對結果來進行接收,資料在原清單上進行變動
-
增
(1)append向清單的末尾添加新元素
(2)insert在指定的索引之前添加元素
(2)extend疊代追加所有元素,要求資料的類型是可疊代的
-
删
(1)pop 通過指定索引删除元素,若無索引移除最後一個;
(2)remove 通過給予的值來删除,如果有多個相同的值,預設删除第一個;
(3)clear清空清單
lst = [3,4,5]
res = lst.pop()
print(lst, res)
>>> [3, 4] 5
-
其他
(1)index擷取某個值的索引,找不到則報錯lst.index(值, start, end)
(2)count計算某個元素出現的次數(不可以指定範圍)
(3)reverse清單翻轉操作,無傳回值
(3)sort()清單排序,預設從小到大排(無傳回值);第一位相同的情況下比較第二位
lst.sort(reverse = True) # 從大到小
print(lst)
tuple
元組類型(不可變資料類型),逗号是區分的關鍵;
特點: 有序,可擷取,不可修改
方法同清單
set
集合類型
特點:無序,自動去重
dict
字典類型
特點: 無序,鍵不可重複
注意:字典中的鍵和集合中的值資料類型必須是可哈希的,即必須是不可變資料類型如:Number(int, float, bool, complex), str, tuple
字典相關方法:
-
增
(1)dic[‘a’] = ‘6788’
(2)fromkeys()使用一組鍵和預設值建立字典:
dic = {}
lst = [1,2,3]
dic = dic.fromkeys(lst,None) # 三個鍵指向的值是同一個
print(dic)
-
删
(1)pop()通過鍵去删除鍵值對(若沒有該鍵,可設定預設值預防報錯)
dic = {'a': [], 'b': 90}
res = dic.pop('a') # res為被删除的值
print(dic, res)
res = dic.pop('c', None) # 當被删除的鍵不存在時需要設定預設值,否則會報錯
print(dic, res)
(2)popitem()删除最後一個鍵值對
(3)clear()清空字典
-
改
(1)update()批量更新,有該鍵則更新,沒有則添加
dic1 = {1:34}
dic_new = {'a': 'new_world'}
# 方法一
dic1.update(dic_new)
print(dic1)
>>> {1: 34, 'a': 'new_world'}
# 方法二
dic1.update(key_word = 'my_head')
print(dic1)
>>> {1: 34, 'a': 'new_world', 'key_word': 'my_head'}
-
查
dic.get(‘aaa’) #如果沒有各個鍵會傳回None不會報錯
- keys()将字典的鍵傳回組成一個可疊代對象;
- dic.values()将字典的值傳回組成一個可疊代對象
- dic.items()将字典的鍵值對湊成一個個元組,組成一個可疊代對象
print(dic1.items(),type(dic1.items()))
>>> dict_items([(1, 34), ('a', 'new_world'), ('key_word', 'my_head')]) <class 'dict_items'>
可變資料類型與不可變資料類型
資料類型可變與不可變與python中的記憶體位址相關:
1,不可變資料類型
不可變資料類型包括Number,str, tuple
a = 45
b = 45
c = b
d = b + 1
print(id(a), id(b), id(c), id(d))
>>>4556717488 4556717488 4556717488 4556717520
上述,變量a,b,c都指向了引用了同一個對象45,他們所指向的位址是相同的,變量d指向的新的對象,位址發生了改變.當沒有變量引用時對象才會進行記憶體回收.
對于不可變資料類型,建立了該對象之後,無論多少個變量指向這個對象,位址是唯一的,當該對象的内容發生改變時相當于重新建立了一個對象,并且位址發生改變.進而可以将不可變資料類型了解為變量所引用的位址處的值是不可變的.
優點: 無論引用多少次,相同的對象隻占用了一塊記憶體;
缺點: 當需要對引用對象的值進行運算進而值發生改變時,需要建立新的對象.
2, 可變資料類型
可變資料類型包括list, dict, set
listvar1 = [1,2,3]
listvar2 = [1,2,3]
var = listvar2
print(id(listvar1), id(listvar2), id(var))
>>> 140304263987976 140304264044872 140304264044872
listvar2.append(56)
print(id(listvar2))
>>> 140304264044872
當變量listvar1,listvar2指派是相同的清單時,他們所指向的位址不同,說明他們指向的是兩個不同的對象;當針對于變量listvar2的值進行操作後,其值改變但是記憶體位址沒有變,并沒有建立新的對象而是在原有對象上進行了修改.
對于可變資料類型,可變可以了解為同一個對象(同一位址)的值可以改變,而不會重新建立對象.
python中的不可變資料類型,不允許變量的值發生變化,如果改變了變量的值,相當于是建立了一個對象,而對于相同的值的對象,在記憶體中則隻有一個對象,内部會有一個引用計數來記錄有多少個變量引用這個對象;可變資料類型,允許變量的值發生變化,即如果對變量進行append、+=等這種操作後,隻是改變了變量的值,而不會建立一個對象,變量引用的對象的位址也不會變化,不過對于相同的值的不同對象,在記憶體中則會存在不同的對象,即每個對象都有自己的位址,相當于記憶體中對于同值的對象儲存了多份,這裡不存在引用計數,是實實在在的對象。
深拷貝和淺拷貝
(1)淺拷貝
示例: 當含有不可變資料類型時:
list1 = ['asdfg', 2, 3]
list2 = list1.copy()
print(id(list1), id(list2))
>>> 140503248118152 140503246732296
print(id(list1[0]), id(list2[0]))
>>> 140503226332416 140503226332416
list2[0] += 'hello world'
print(list1, list2)
>>> ['asdfg', 2, 3] ['asdfghello world', 2, 3]
print(id(list1[0]), id(list2[0]))
>>> 140503226332416 140503248103728
示例: 當含有可變資料類型時:
list1 = [[1,2,3], 2, 3]
list2 = list1.copy()
print(id(list1), id(list2))
>>> 140614529960968 140614531392136
print(id(list1[0]), id(list2[0]))
>>> 140614531391880 140614531391880
list2[0].append(34)
print(list1, list2)
>>> [[1, 2, 3, 34], 2, 3] [[1, 2, 3, 34], 2, 3]
print(id(list1[0]), id(list2[0]))
>>> 140614531391880 140614531391880
list2是對于list1的淺拷貝, 此時兩個變量的位址不同;可以看到但其中的元素仍然指向的是相同的位址; 當對于變量list2中的第一個元素進行append操作後,可以看到,原來的list1第一個元素也發生了相應的變化,因為他們指向的是同一個位址
淺拷貝隻能拷貝容器中不可變資料類型(位址暫時未變,值發生變化自然會變),而對于容器中的可變資料類型仍然指向原來的位址,當值發生改變時原來的變量也會發生相應的變化.
(2)深拷貝
深拷貝會将不可變資料類型和可變資料類型都進行拷貝, 可變資料類型的位址發生變化,不可變資料類型的位址暫時不變.
# 深拷貝
import copy
list3 = [1,2,3,[4,5,6]]
list4 = copy.deepcopy(list3)
print(id(list4[-1]))
>>> 140442270122824
list4[-1].append(9)
print(list3, id(list3[-1]))
>>> [1, 2, 3, [4, 5, 6]] 140442270122760
print(list4, id(list4[-1]))
>>> [1, 2, 3, [4, 5, 6, 9]] 140442270122824
list3的最後一個元素為可變資料類型清單,當進行深拷貝之後,在新的清單list4中該元素的位址是新開辟的一塊記憶體位址,因而當資料發生變化不會影響原來的list3.
python的記憶體管理
引用計數器為主,标記清除和分代回收 + 緩存機制
1.引用計數器(為主)
1.1 環狀的雙向連結清單refrain
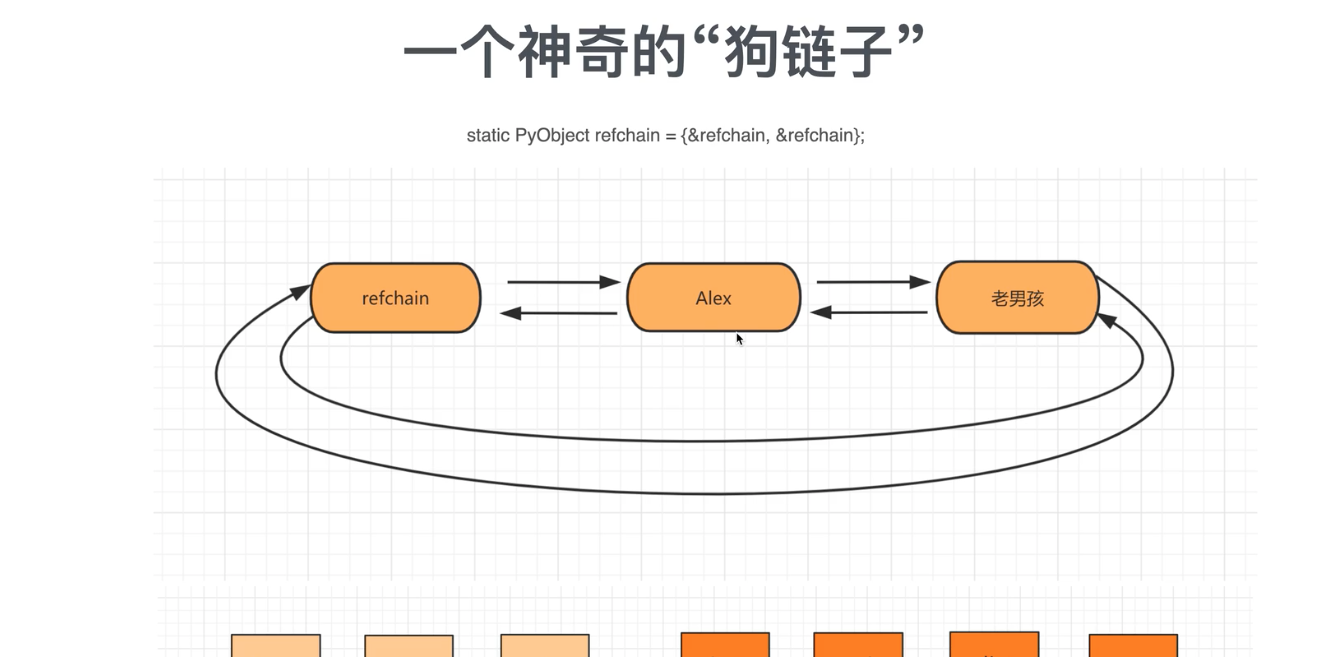
在python中建立的任何對象都會放在refchain連結清單中,
name = 'gdah' # 内部會建立一些資料[上一個對象,下一個對象,類型,引用個數]
new = name
age = 18 # 内部會建立一些資料[上一個對象,下一個對象,類型,引用個數, val = 18]
hobby = [1,2,3] # 内部會建立一些資料[上一個對象,下一個對象,類型,引用個數, items = 元素,元素個數]

在c源碼中如何展現的每個對象都有的相同的值:PyObject結構體(4個值)
有多個元素組成的對象:PyObject結構體 + ob_size
1.2不同類型封裝的結構體
data = 3.14
'''
内部會建立:
_ob_next
_ob_prev
ob_refcnt = 1
ob_type = float
ob_fval = 3.14
'''
1.3引用計數器
val1 = 3.14
val2 = 90
val3 = (4,5,6,7)
當python程式運作時,會根據資料類型的不同找到其對應的結構體,根據結構體中的字段來建立相關的資料,然後将對象添加到refchain雙向連結清單中.
在C源碼中有兩個關鍵的結構體:PyObject,PyVarObject.
每個對象中有ob_refcnt就是引用計數器,值預設為1;當有其他變量引用對象時,引用計數器會發生變化.
- 引用
a = 90
b = a
- 删除引用
a = 90
b = a
del b # b變量删除,b對應對象引用計數器-1
del a # a變量删除,a對象引用計數器-1
# 當一個對象的引用計數器為0時,意味着沒有人使用這個對象了,意味着這個對象是垃圾,進行垃圾回收
# 回收: 1.對象從refchain連結清單中移除 2,将對象銷毀,記憶體歸還
1.4循環引用問題
循環引用,交叉感染
v1 = [11,22,33] # refchain中建立一個清單對象,由于v1=對象,是以清單引用對象引用計數器為1.
v2 = [44,55,66] # refchain中再建立一個清單對象,該清單引用計數器為1
v1.append(v2) # 将v2追加到v1中,則v2對應的對象引用計數器加1,最終為2
v2.append(v1)
del v1 # 引用計數器-1
del v2 # 引用計數器-1
由于已經将變量v1,v2進行了del那麼在程式中别的地方也無法使用這個變量,但是由于引用計數始終為1,就一直會存在于記憶體之中不進行回收.可能就會造成記憶體洩露.
标記清除
目的:為了解決引用計數器循環引用的不足.
實作: 在python的底層 再 去維護一個連結清單,連結清單中專門放那些可能存在循環引用的對象(list/tuple/dict/set).
在python内部’某種情況下’觸發,回去掃描可能存在循環引用的連結清單中的每個元素,檢查是否有循環引用,如果有則讓雙方的引用計數器-1;如果是0則垃圾回收.
問題:
- 什麼時候掃描?
- 可能存在循環引用的連結清單掃描的代價大,每次掃描耗時久.
3.分代回收
将可能存在循環引用的對象維護成3個連結清單:
- 0代:0代中對象個數達到700個掃描一次.
- 1代:0代掃描10次,則1代掃描一次.
-
2代:1代掃描10次,則2代掃描一次.
0代中垃圾則清除,不是垃圾則更新到1代,新的對象繼續加到0代…
4.小結緩存機制
在python中維護了一個refchain的雙向環狀連結清單,這個連結清單中存儲程式建立的所有對象,每種類型的對象中都有一個ob_refcnt引用計數器的值,引用個數+1,-1,最後當引用計數器變為0時會進行垃圾回收(對象銷毀,refchain中移除)
但是,在python中對于那些可以有多核元素組成的對象可能會存在循環引用的問題,為了解決這個問題python又引入了标記清除和分代回收,在其内部維護了四個連結清單
- refchain
- 2代,10次
- 1代,10次
-
0代,700個
在源碼内部當達到各自的門檻值時,就會觸發掃描連結清單進行标記清除的動作(有循環則各自-1)
但是,源碼内部在上述流程中提出了優化機制
5.Python緩存
5.1池(int)
為了避免重複建立和銷毀一些常見對象,維護池.
# 啟動解釋器時,python内部幫我們建立:-5, -4,....257
v1 = 8 # 記憶體不會開辟記憶體,直接去池中擷取
v2 = 5 # 記憶體不會開辟記憶體,直接去池中擷取
5.2 free_list(float, list,tuple,dict)
當一個對象的引用計數器為0時,按理說應該回收,内部不會直接回收,而是将對象添加到free_list連結清單中當緩存,以後去建立對象時,不再重新開辟記憶體,而是直接使用free_list.
v1 = 3.14 # 開辟記憶體,内部存儲結構體中定義那幾個之後,并存到refchain中.
del v1 # refchain中移除,将對象添加到free_list中(80個),free_list滿了則銷毀.
v9 = 999.99 # 不會重新開辟記憶體,去free_list中擷取對象,對象内部資料初始化,再放到refchain中.