端到端的文本无关说话人确认的深度神经网络嵌入
论文:Snyder D, Ghahremani P, Povey D, et al. Deep neural network-based speaker embeddings for end-to-end speaker verification. 2016 IEEE Workshop on Spoken Language Technology, SLT 2016 - Proceedings[C]. 2017: 165–170.
摘要
在文本无关的说话人确认中,D. Snyder 研究了一种深度神经网络(Deep Neural Network, DNN)的端到端系统。该系统由一个 DNN 组成,该模型将长度可变的语音投影为说话人嵌入,进而进行相似度计算。端到端系统的最大特点是相似度计算公式整合在优化目标中。结果表明:1)大量的说话人的训练数据集显著提升文本无关的说话人确认系统;2)DNN 嵌入对时长鲁棒,适用于短时语音段的说话人特征提取;3)DNN 嵌入与 i-vector 在得分上是互补的。
方法
论文介绍了两种文本无关的说话人确认方法,其中 i-vector 系统作为基准系统,端到端系统是提出的方法:
- i-vector 系统:
- 模型:输入(60-d) ↦ \mapsto ↦ UBM(4096-c) ↦ \mapsto ↦ i-vector 提取器(600-d) ↦ \mapsto ↦ PLDA
- 输入:共 60 维,20 MFCC + Delta + Acceleration,25 ms 帧长,平均归一化,3s滑窗,基于GMM的VAD
- UBM:4096个全方差 GMM 成分
- i-vector:600 维,中心化,长度归一化
- PLDA:剪切的训练数据,开始的1-20s,短时语音训练(1-20s)或者混合时长(增加 full)的训练
- 端到端系统:
- 模型:输入(180-d) ↦ \mapsto ↦ 端到端 DNN
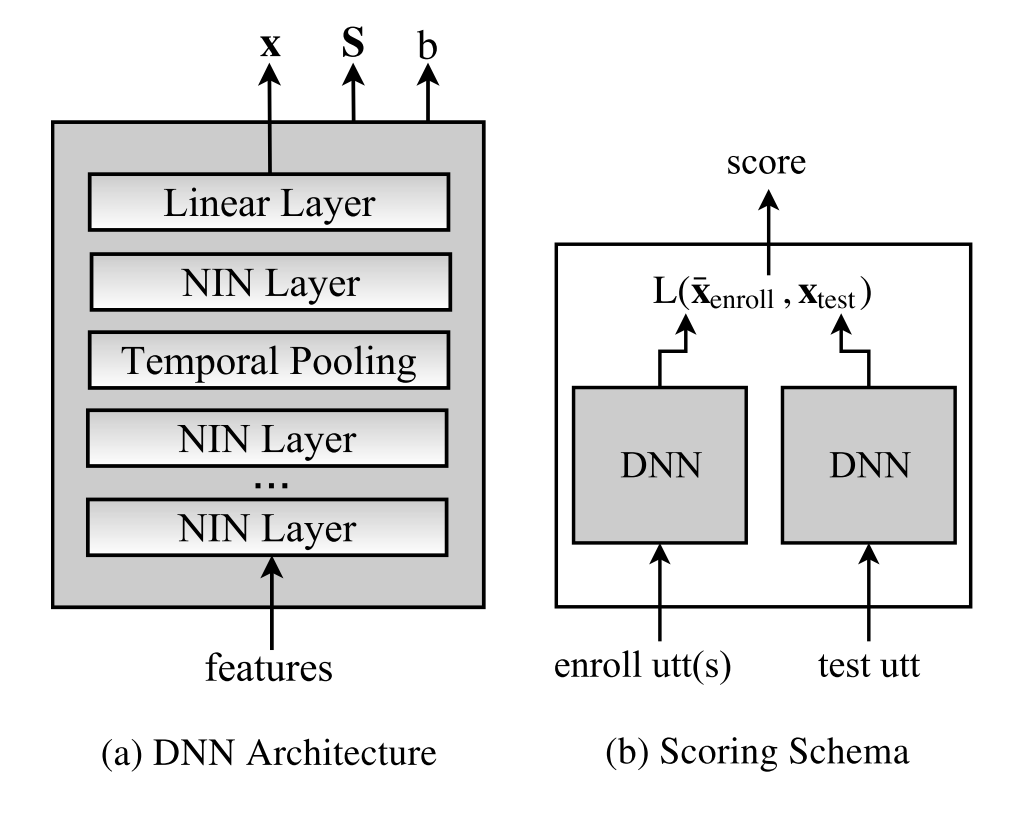
端到端的文本无关说话人确认的深度神经网络嵌入端到端的文本无关说话人确认的深度神经网络嵌入 - 输入:共 180 维,20 MFCC,25 ms 帧长,滑窗 3s 平均归一化,9 帧被拼接在一起,拼接后,执行与 i-vector 系统相同的 VAD
- 端到端 DNN:
- 结构:4 隐藏层 + 时间池化层 + 线性层,输出嵌入 x;激活函数采用 network-in-network (NIN),共6,700,000 变量
- 独立变量:对称矩阵 S、补偿 b,与输入无关
-
优化目标:
E = − ∑ x,y ∈ P same ln ( P r ( x,y ) ) − K ∑ x,y ∈ P diff ln ( 1 − P r ( x,y ) ) E=-\sum_{\textbf{x,y}\in P_{\text{same}}}\ln(Pr(\textbf{x,y}))-K\sum_{\textbf{x,y}\in P_{\text{diff}}}\ln(1-Pr(\textbf{x,y})) E=−x,y∈Psame∑ln(Pr(x,y))−Kx,y∈Pdiff∑ln(1−Pr(x,y))
P r ( x,y ) = 1 1 + e − L ( x,y ) Pr(\textbf{x,y})=\frac{1}{1+e^{-L(\textbf{x,y})}} Pr(x,y)=1+e−L(x,y)1
L ( x,y ) = x T y − x T Sx − y T Sy + b L(\textbf{x,y})=\textbf{x}^T\textbf{y}-\textbf{x}^T\textbf{S}\textbf{x}-\textbf{y}^T\textbf{S}\textbf{y}+b L(x,y)=xTy−xTSx−yTSy+b
其中 x 与 y 是说话人嵌入, P same P_{\text{same}} Psame 与 P diff P_{\text{diff}} Pdiff 分别表示成对的相同说话人和成对的不同说话人的数据集, K K K 用来权衡 P same P_{\text{same}} Psame 与 P diff P_{\text{diff}} Pdiff 比重,因为 P same P_{\text{same}} Psame 一般少于 P diff P_{\text{diff}} Pdiff
- 相似度计算: L ( x,y ) L(\textbf{x,y}) L(x,y),该公式是类似 PLDA 量化方法
- 训练策略:训练策略包含 x 与 y 配对的方法和训练步骤,训练步骤分两部:
- 2 epochs 长时语音(10-30 s),
- 2 epochs 短时(1-20 s)或长时(1-30 s)语音。
- 说话人嵌入:30s 以内语音段,注册嵌入采用平均多个语音段的嵌入
- 模型:输入(180-d) ↦ \mapsto ↦ 端到端 DNN
数据集
论文采用的数据集是 8kHz 的美式英语电话语音,其中训练集的说话人与评测集的说话人之间没有重叠的,而且测试语音段通过截断前 T 秒,并经过了基于GMM的VAD来判断是否是语音。数据集的设计主要是针对说话人规模和语音时长。
| 数据集/统计信息 | 说话人数量 | 记录数 | 人均记录数 | 平均时长(s) |
|---|---|---|---|---|
| 5,000 人的训练集(train5k) | 5,000 | 25,000 | 4.93 | 81 |
| 15,000 人的训练集(train15k) | 15,000 | 53,000 | 3.53 | 84 |
| 102,000 人的训练集(train102k) | 102,000 | 226,000 | 2.22 | 91 |
| 注册集 | 2,419 | 2,915 | 1.21 | 91 |
| 测试集 | 2,419 | 2,419 | 1 | 1-92 |
系统及其结果
论文三种了三种场景:时长鲁棒性、训练数据规模和系统融合,评测指标采用了等误差率(EER/%),其中 ivec 表示 i-vector 系统,dnn 表示端到端 DNN 系统,1-20s 表示训练集的时长不低于 20s,1-30s 表示语音时长不低于 30s,full 表示全长的时长,pool 表示汇总分析(pooled results),即将所有的结果放在一起进行评估,fusion 表示得分融合,即利用均值和方差进行归一化,并叠加在一起。
结果:
- 1-20s 的训练效果比较好。
- 少量的训练集,i-vector 优于 DNN 系统,尤其是在长时语音。
- 大量的说话人有利于文本无关的说话人确认系统。
- DNN嵌入对时长变化更加鲁棒,适用于短时语音的说话人特征提取。
| 1s | 2s | 3s | 5s | 10s | 20s | full | pool | ||
|---|---|---|---|---|---|---|---|---|---|
| ivec102k | 1-20s | 14.1 | 8.7 | 6.7 | 4.9 | 3.7 | 3.2 | 2.8 | 8.5 |
| 1-20s+full | 15.0 | 9.4 | 7.0 | 5.1 | 3.8 | 3.1 | 2.6 | 10.0 | |
| full | 16.4 | 9.9 | 7.3 | 5.2 | 3.8 | 2.8 | 2.4 | 10.6 | |
| dnn102k | 1-20s | 12.6 | 7.5 | 6.0 | 4.2 | 3.4 | 2.6 | 2.5 | 6.0 |
| 1-30s | 13.8 | 8.7 | 6.2 | 4.6 | 3.4 | 2.6 | 2.4 | 6.6 |
| 训练集 | 嵌入 | 1s | 2s | 3s | 5s | 10s | 20s | full | pool |
|---|---|---|---|---|---|---|---|---|---|
| train5k | ivec | 14.8 | 11.4 | 9.0 | 7.0 | 5.4 | 4.4 | 3.5 | 8.6 |
| dnn | 17.5 | 12.6 | 10.7 | 8.7 | 7.2 | 6.4 | 6.2 | 10.6 | |
| train15k | ivec | 13.8 | 9.0 | 7.0 | 5.1 | 3.9 | 3.0 | 2.7 | 8.0 |
| dnn | 14.2 | 10.7 | 8.0 | 6.5 | 5.4 | 4.9 | 4.9 | 8.3 | |
| train105k | ivec | 14.1 | 8.7 | 6.7 | 4.9 | 3.7 | 3.2 | 2.8 | 8.5 |
| dnn | 12.6 | 7.5 | 6.0 | 4.2 | 3.4 | 2.6 | 2.5 | 6.0 |
| 系统/时长 | 1s | 2s | 3s | 5s | 10s | 20s | full | pool |
|---|---|---|---|---|---|---|---|---|
| ivec102k | 14.1 | 8.7 | 6.7 | 4.9 | 3.7 | 3.2 | 2.8 | 8.5 |
| dnn102k | 12.6 | 7.5 | 6.0 | 4.2 | 3.4 | 2.6 | 2.5 | 6.0 |
| fusion | 10.2 | 6.1 | 4.3 | 3.4 | 2.4 | 1.9 | 1.6 | 5.3 |
参考文献
[1] Snyder D, Ghahremani P, Povey D, et al. Deep neural network-based speaker embeddings for end-to-end speaker verification. 2016 IEEE Workshop on Spoken Language Technology, SLT 2016 - Proceedings[C]. 2017: 165–170.
[2] Ghahremani P, Manohar V, Povey D, et al. Acoustic modelling from the signal domain using CNNs. Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, 2016, 08-12-September-2016(2012): 3434–3438.
作者信息:
CSDN:https://blog.csdn.net/i_love_home?viewmode=contents
Github:https://github.com/mechanicalsea
2019级同济大学博士研究生 王瑞 [email protected]
研究方向:说话人识别、说话人分离
![深度学习与围棋:为AlphaGo训练深度神经网络13.1.1 AlphaGo的网络架构13.1.2 AlphaGo棋盘编码器13.1.3 训练AlphaGo风格的策略网络[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)