端到端的文本無關說話人确認的深度神經網絡嵌入
論文:Snyder D, Ghahremani P, Povey D, et al. Deep neural network-based speaker embeddings for end-to-end speaker verification. 2016 IEEE Workshop on Spoken Language Technology, SLT 2016 - Proceedings[C]. 2017: 165–170.
摘要
在文本無關的說話人确認中,D. Snyder 研究了一種深度神經網絡(Deep Neural Network, DNN)的端到端系統。該系統由一個 DNN 組成,該模型将長度可變的語音投影為說話人嵌入,進而進行相似度計算。端到端系統的最大特點是相似度計算公式整合在優化目标中。結果表明:1)大量的說話人的訓練資料集顯著提升文本無關的說話人确認系統;2)DNN 嵌入對時長魯棒,适用于短時語音段的說話人特征提取;3)DNN 嵌入與 i-vector 在得分上是互補的。
方法
論文介紹了兩種文本無關的說話人确認方法,其中 i-vector 系統作為基準系統,端到端系統是提出的方法:
- i-vector 系統:
- 模型:輸入(60-d) ↦ \mapsto ↦ UBM(4096-c) ↦ \mapsto ↦ i-vector 提取器(600-d) ↦ \mapsto ↦ PLDA
- 輸入:共 60 維,20 MFCC + Delta + Acceleration,25 ms 幀長,平均歸一化,3s滑窗,基于GMM的VAD
- UBM:4096個全方差 GMM 成分
- i-vector:600 維,中心化,長度歸一化
- PLDA:剪切的訓練資料,開始的1-20s,短時語音訓練(1-20s)或者混合時長(增加 full)的訓練
- 端到端系統:
- 模型:輸入(180-d) ↦ \mapsto ↦ 端到端 DNN
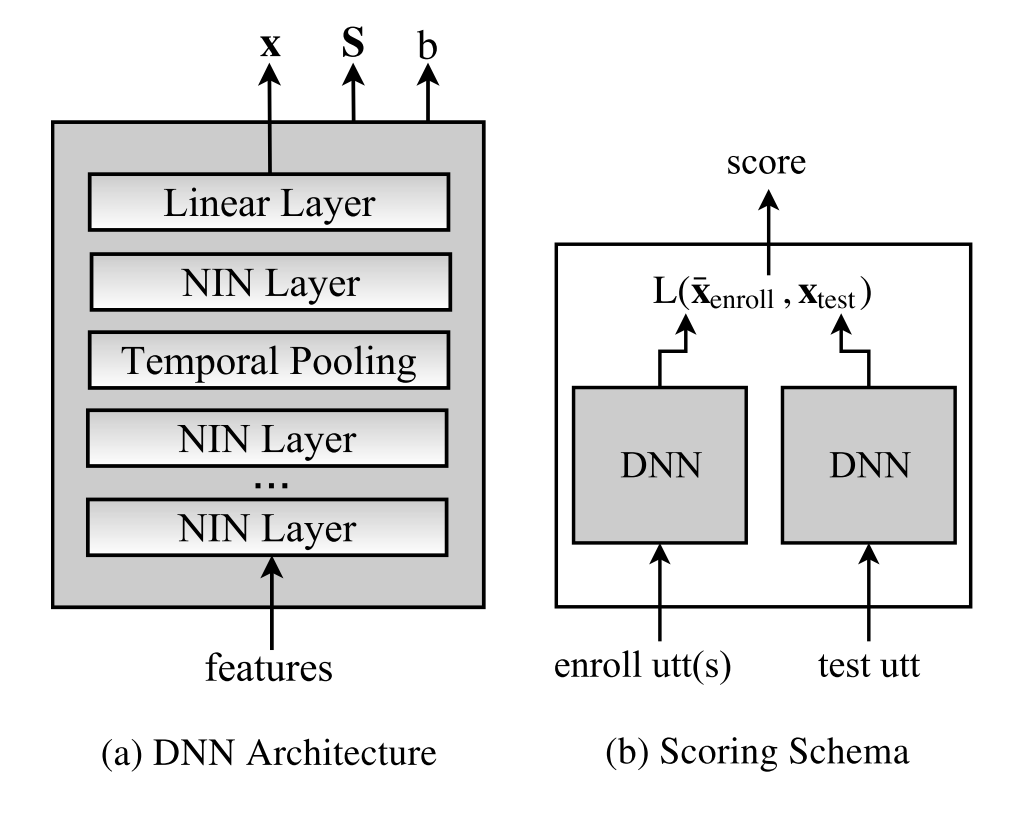
端到端的文本無關說話人确認的深度神經網絡嵌入端到端的文本無關說話人确認的深度神經網絡嵌入 - 輸入:共 180 維,20 MFCC,25 ms 幀長,滑窗 3s 平均歸一化,9 幀被拼接在一起,拼接後,執行與 i-vector 系統相同的 VAD
- 端到端 DNN:
- 結構:4 隐藏層 + 時間池化層 + 線性層,輸出嵌入 x;激活函數采用 network-in-network (NIN),共6,700,000 變量
- 獨立變量:對稱矩陣 S、補償 b,與輸入無關
-
優化目标:
E = − ∑ x,y ∈ P same ln ( P r ( x,y ) ) − K ∑ x,y ∈ P diff ln ( 1 − P r ( x,y ) ) E=-\sum_{\textbf{x,y}\in P_{\text{same}}}\ln(Pr(\textbf{x,y}))-K\sum_{\textbf{x,y}\in P_{\text{diff}}}\ln(1-Pr(\textbf{x,y})) E=−x,y∈Psame∑ln(Pr(x,y))−Kx,y∈Pdiff∑ln(1−Pr(x,y))
P r ( x,y ) = 1 1 + e − L ( x,y ) Pr(\textbf{x,y})=\frac{1}{1+e^{-L(\textbf{x,y})}} Pr(x,y)=1+e−L(x,y)1
L ( x,y ) = x T y − x T Sx − y T Sy + b L(\textbf{x,y})=\textbf{x}^T\textbf{y}-\textbf{x}^T\textbf{S}\textbf{x}-\textbf{y}^T\textbf{S}\textbf{y}+b L(x,y)=xTy−xTSx−yTSy+b
其中 x 與 y 是說話人嵌入, P same P_{\text{same}} Psame 與 P diff P_{\text{diff}} Pdiff 分别表示成對的相同說話人和成對的不同說話人的資料集, K K K 用來權衡 P same P_{\text{same}} Psame 與 P diff P_{\text{diff}} Pdiff 比重,因為 P same P_{\text{same}} Psame 一般少于 P diff P_{\text{diff}} Pdiff
- 相似度計算: L ( x,y ) L(\textbf{x,y}) L(x,y),該公式是類似 PLDA 量化方法
- 訓練政策:訓練政策包含 x 與 y 配對的方法和訓練步驟,訓練步驟分兩部:
- 2 epochs 長時語音(10-30 s),
- 2 epochs 短時(1-20 s)或長時(1-30 s)語音。
- 說話人嵌入:30s 以内語音段,注冊嵌入采用平均多個語音段的嵌入
- 模型:輸入(180-d) ↦ \mapsto ↦ 端到端 DNN
資料集
論文采用的資料集是 8kHz 的美式英語電話語音,其中訓練集的說話人與評測集的說話人之間沒有重疊的,而且測試語音段通過截斷前 T 秒,并經過了基于GMM的VAD來判斷是否是語音。資料集的設計主要是針對說話人規模和語音時長。
| 資料集/統計資訊 | 說話人數量 | 記錄數 | 人均記錄數 | 平均時長(s) |
|---|---|---|---|---|
| 5,000 人的訓練集(train5k) | 5,000 | 25,000 | 4.93 | 81 |
| 15,000 人的訓練集(train15k) | 15,000 | 53,000 | 3.53 | 84 |
| 102,000 人的訓練集(train102k) | 102,000 | 226,000 | 2.22 | 91 |
| 注冊集 | 2,419 | 2,915 | 1.21 | 91 |
| 測試集 | 2,419 | 2,419 | 1 | 1-92 |
系統及其結果
論文三種了三種場景:時長魯棒性、訓練資料規模和系統融合,評測名額采用了等誤差率(EER/%),其中 ivec 表示 i-vector 系統,dnn 表示端到端 DNN 系統,1-20s 表示訓練集的時長不低于 20s,1-30s 表示語音時長不低于 30s,full 表示全長的時長,pool 表示彙總分析(pooled results),即将所有的結果放在一起進行評估,fusion 表示得分融合,即利用均值和方差進行歸一化,并疊加在一起。
結果:
- 1-20s 的訓練效果比較好。
- 少量的訓練集,i-vector 優于 DNN 系統,尤其是在長時語音。
- 大量的說話人有利于文本無關的說話人确認系統。
- DNN嵌入對時長變化更加魯棒,适用于短時語音的說話人特征提取。
| 1s | 2s | 3s | 5s | 10s | 20s | full | pool | ||
|---|---|---|---|---|---|---|---|---|---|
| ivec102k | 1-20s | 14.1 | 8.7 | 6.7 | 4.9 | 3.7 | 3.2 | 2.8 | 8.5 |
| 1-20s+full | 15.0 | 9.4 | 7.0 | 5.1 | 3.8 | 3.1 | 2.6 | 10.0 | |
| full | 16.4 | 9.9 | 7.3 | 5.2 | 3.8 | 2.8 | 2.4 | 10.6 | |
| dnn102k | 1-20s | 12.6 | 7.5 | 6.0 | 4.2 | 3.4 | 2.6 | 2.5 | 6.0 |
| 1-30s | 13.8 | 8.7 | 6.2 | 4.6 | 3.4 | 2.6 | 2.4 | 6.6 |
| 訓練集 | 嵌入 | 1s | 2s | 3s | 5s | 10s | 20s | full | pool |
|---|---|---|---|---|---|---|---|---|---|
| train5k | ivec | 14.8 | 11.4 | 9.0 | 7.0 | 5.4 | 4.4 | 3.5 | 8.6 |
| dnn | 17.5 | 12.6 | 10.7 | 8.7 | 7.2 | 6.4 | 6.2 | 10.6 | |
| train15k | ivec | 13.8 | 9.0 | 7.0 | 5.1 | 3.9 | 3.0 | 2.7 | 8.0 |
| dnn | 14.2 | 10.7 | 8.0 | 6.5 | 5.4 | 4.9 | 4.9 | 8.3 | |
| train105k | ivec | 14.1 | 8.7 | 6.7 | 4.9 | 3.7 | 3.2 | 2.8 | 8.5 |
| dnn | 12.6 | 7.5 | 6.0 | 4.2 | 3.4 | 2.6 | 2.5 | 6.0 |
| 系統/時長 | 1s | 2s | 3s | 5s | 10s | 20s | full | pool |
|---|---|---|---|---|---|---|---|---|
| ivec102k | 14.1 | 8.7 | 6.7 | 4.9 | 3.7 | 3.2 | 2.8 | 8.5 |
| dnn102k | 12.6 | 7.5 | 6.0 | 4.2 | 3.4 | 2.6 | 2.5 | 6.0 |
| fusion | 10.2 | 6.1 | 4.3 | 3.4 | 2.4 | 1.9 | 1.6 | 5.3 |
參考文獻
[1] Snyder D, Ghahremani P, Povey D, et al. Deep neural network-based speaker embeddings for end-to-end speaker verification. 2016 IEEE Workshop on Spoken Language Technology, SLT 2016 - Proceedings[C]. 2017: 165–170.
[2] Ghahremani P, Manohar V, Povey D, et al. Acoustic modelling from the signal domain using CNNs. Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, 2016, 08-12-September-2016(2012): 3434–3438.
作者資訊:
CSDN:https://blog.csdn.net/i_love_home?viewmode=contents
Github:https://github.com/mechanicalsea
2019級同濟大學博士研究所學生 王瑞 [email protected]
研究方向:說話人識别、說話人分離
![深度學習與圍棋:為AlphaGo訓練深度神經網絡13.1.1 AlphaGo的網絡架構13.1.2 AlphaGo棋盤編碼器13.1.3 訓練AlphaGo風格的政策網絡[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)