数据结构之树-第一篇
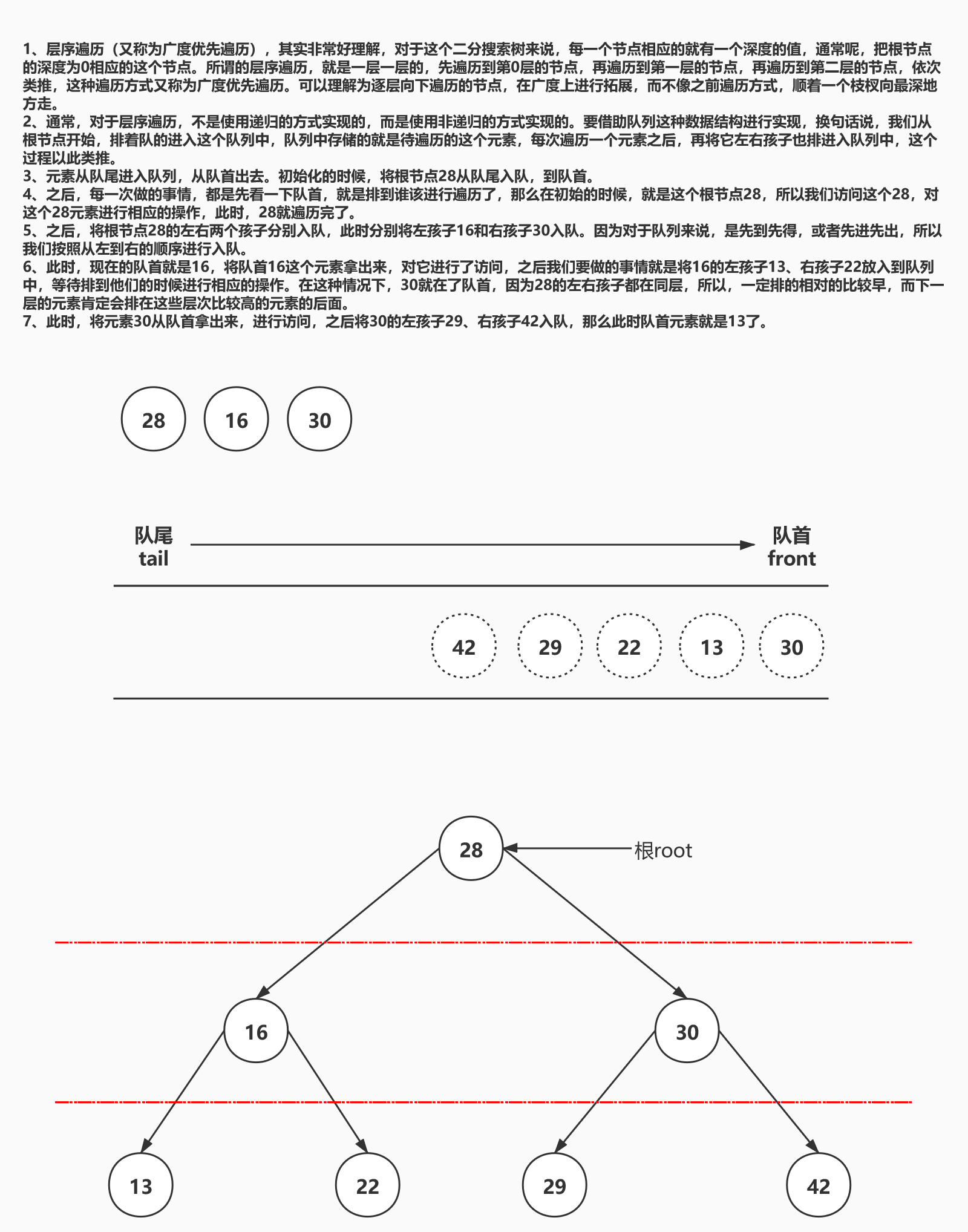
1、此时,将元素30从队首拿出来,进行访问,之后将30的左孩子29、右孩子42入队,那么此时队首元素就是13了。

1 package com.tree;
2
3
4 import java.util.*;
5
6 /**
7 * 1、二分搜索树,二分搜索树存储的内容支持泛型,但是不是支持所有的类型,应该对类型有一个限制,
8 * 这个限制是这个类型必须拥有可比较性,对泛型E进行限制,这个限制就是继承Comparable<E>接口,
9 * 这个类型E必须具有可比较性。
10 * <p>
11 * <p>
12 * 2、对于前序、中序、后序遍历来说,不管是递归写法还是非递归写法,对于我们这棵二分搜索树来说,
13 * 我们都是在遍历的过程中一扎到底,这样的一种遍历方式,其实还有另外一个名字,叫做,深度优先遍历。
14 * 对于这棵树来说,都会先来到这棵树最深的地方,直到不能再深了,才开始返回回去,
15 * 这种遍历叫做深度优先遍历。和深度优先遍历相对的是另外一种遍历方式,叫做广度优先遍历,
16 * 广度优先遍历遍历出来的结果,这个顺序其实是整个二分搜索树的层序遍历的顺序。
17 */
18 public class BinarySearchTree<E extends Comparable<E>> {
19
20 // 二分搜索树的节点类,私有内部类。
21 private class Node {
22 private E e;// 存储元素e;
23 private Node left;// 指向左子树,指向左孩子。
24 private Node right;// 指向右子树,指向右孩子。
25
26 /**
27 * 含参构造函数
28 *
29 * @param e
30 */
31 public Node(E e) {
32 this.e = e;// 用户存储的元素e。
33 left = null;// 左孩子初始化为空。
34 right = null;// 右孩子初始化为空。
35 }
36 }
37
38 private Node root;// 根节点
39 private int size;// 二分搜索树存储了多少个元素
40
41 /**
42 * 无参构造函数,和默认构造函数做的事情一样的。
43 */
44 public BinarySearchTree() {
45 // 初始化的时候,二分搜索树一个元素都没有存储
46 root = null;
47 size = 0;// 大小初始化为0
48 }
49
50 /**
51 * 返回二分搜索树的含有多少个元素
52 *
53 * @return
54 */
55 public int size() {
56 // 二分搜索树的大小
57 return size;
58 }
59
60 /**
61 * 判断二分搜索树是否为空。
62 *
63 * @return
64 */
65 public boolean isEmpty() {
66 return size == 0;
67 }
68
69 // /**
70 // * 向二分搜索树中添加新的元素e.
71 // * <p>
72 // * 在公开的二分搜索树的调用的add方法。在将递归调用中, 是将新的元素e作为node子节点插入进去的。
73 // * 这个时候,形成了一个逻辑上的不统一,递归函数中,e元素和node.e元素进行了两轮比较,第一轮比较,
74 // * 在比较完他们的大小的同时,还要看一下node的左右两边是不是为空,如果为空直接插入,
75 // * 对于第二轮比较,我们知道我们不能直接作为Node的孩子插入这个元素e,只要再次递归的调用add的函数。
76 // *
77 // * @param e
78 // */
79 // public void add(E e) {
80 // // 判断,如果根节点是空的时候,直接指向新创建的节点即可
81 // if (root == null) {
82 // // 对根节点进行特殊的处理,如果根为空的时候,就直接创建一个新的节点。
83 // root = new Node(e);
84 // // 维护size
85 // size++;
86 // } else {
87 // // 否则,根节点不是空的时候。从根节点开始添加一个元素。
88 // // 注意,由于需要递归的调用,对于每一个节点的左子树也是一个更小的二分搜索树的根节点,
89 // // 对于每一个节点的右子树也是一个更小的二分搜索树的根节点。
90 // // 所以在递归的过程中,创建一个新的递归的函数。
91 //
92 // // 如果根不为空,尝试从根节点开始插入元素e。
93 // add(root, e);
94 // }
95 //
96 // }
97 //
98 // /**
99 // * 私有的递归添加方法
100 // * <p>
101 // * 整体上是,向以node为根的二分搜索树中插入元素E,递归算法。
102 // * <p>
103 // * 之所以设置Node,就是因为在插入的过程中,我们要不断地转换到新的更小的二分搜索树中,
104 // * 去找到这个新的元素e真正应该插入的位置,那么相应的,我们在递归调用的过程中,
105 // * 相当于二分搜索树的根在逐渐变化的,所以,我们需要靠这个参数来体现这个变化。
106 // *
107 // * @param node Node结构本身都是对用户屏蔽的,用户不需要了解二分搜索树中节点的结构。
108 // * @param e
109 // */
110 // private void add(Node node, E e) {
111 // // 精髓,将新的元素e插入给node的左孩子还是node的右孩子。
112 // // 对当前的node来说,如果想插入到左边,但是左孩子不为空的话,再递归的将新的元素e插入到add(node.left, e);node的左子树。
113 // // 如果想插入到右边,但是右孩子不为空的话,再递归的将新的元素e插入到add(node.right, e);node的右子树。
114 //
115 //
116 // // 第一部分,递归终止的条件。
117 // // 先检查一下元素e,是不是等于node的元素e。
118 // if (e.equals(node.e)) {
119 // // 如果相等,说明要插入的元素已经存在于二分搜索树中了。
120 // return;
121 // // 主要的插入代码,就是下面的判断,然后将元素e进行插入到左子树还是右子树的操作。
122 // } else if (e.compareTo(node.e) < 0 && node.left == null) {
123 // // 如果待插入元素e小于node的元素e,则把元素e插入到node的左子树上面。
124 // // 由于元素E满足Comparable<E>类型的,所以应该是使用compareTo方法比较,不是基础数据类型,不能使用大于号小于号比较。
125 //
126 // // 如果此时node的左子树又等于空,直接创建一个Node,将元素存储到Node里面即可。
127 // // 此时元素e就变成了node的左孩子了。
128 // node.left = new Node(e);
129 // // 维护size的大小。
130 // size++;
131 // // return表示此次插入操作也完成了。
132 // return;
133 // } else if (e.compareTo(node.e) > 0 && node.right == null) {
134 // // 如果待插入元素e大于node节点的元素e,则把元素e插入到node的右子树上面。
135 // // 此时,如果node的右孩子又等于空,直接创建一个Node,将元素存储到Node即可。
136 // // 此时,元素就变成了node的右孩子了。
137 // node.right = new Node(e);
138 // // 维护size的大小。
139 // size++;
140 // // return表示此次插入操作也完成了。
141 // return;
142 // }
143 //
144 //
145 // // 递归的第二部分。递归调用的逻辑。
146 // if (e.compareTo(node.e) < 0) {
147 // // 如果待插入元素e小于node的元素e,递归调用add方法,参数一是向左子树添加左孩子。
148 // // 向左子树添加元素e。
149 // add(node.left, e);
150 // } else if (e.compareTo(node.e) > 0) {
151 // // 如果待插入元素e大于node的元素e,递归调用add方法,参数一是向右子树添加右孩子。
152 // // 向右子树添加元素e。
153 // add(node.right, e);
154 // }
155 // }
156
157
158 /**
159 * 向二分搜索树中添加新的元素e。
160 *
161 * @param e
162 */
163 public void add(E e) {
164 // 此时,不需要对root为空进行特殊判断。
165 // 向root中插入元素e。如果root为空的话,直接返回一个新的节点,将元素存储到该新的节点里面。
166 root = add(root, e);
167 }
168
169 /**
170 * 深入理解递归终止条件。
171 * <p>
172 * 返回插入新节点后二叉搜索树的根。
173 * <p>
174 * 向以node为根的二分搜索树中插入元素e,递归算法。
175 * <p>
176 * <p>
177 * 对于新的add递归函数,将向以node为根的二分搜索树中插入元素e,并且返回在做完这个操作以后这个二分搜索树的根节点,
178 * 如果我们传入的这个node为空的话,插入新的元素以后,就产生新的根节点,就是创建了一个Node e,
179 * 否则的话,我们来比较我们待插入的元素e和当前的node e的大小关系,如果小于零的话,向左子树添加一个左孩子,
180 * 如果大于零的话,向右子树添加一个右孩子。如果等于零的话,什么都不操作。
181 * 不管向左子树添加元素还是向右子树添加元素,插入完成之后,都将当前node的左孩子和右孩子进行重新赋值,
182 * 在重新赋值以后,这个node依赖是这个以node为根的二分搜索树。相应的根节点将他返回回去。
183 * <p>
184 * 链表的递归插入和二分搜索树的添加具有高度相似性的,在二分搜索树中需要判断一下,是要插入到左子树还是右子树。
185 *
186 * @param node
187 * @param e
188 * @return
189 */
190 private Node add(Node node, E e) {
191 // 空本身也是一种二分搜索树,空本身也是一颗二叉树,换句话说,如果走递归函数,走到node为空的时候
192 // 一定要创建一个Node节点。上面的add方法实现,其实还没有递归到底部。
193
194 // 精髓,如果待插入元素e小于node的元素e,此时不管node.left是不是为空,就再递归一层,
195 // 如果递归的这一层,node等于空的话,也就是,现在要新插入一个元素,插入到哪里,插入到空这颗
196 // 二叉树上,那么,很显然,这个位置本身就应该是这个节点。
197
198
199 // 如果按照上面的思想,如果此时node等于空的话,此时,肯定要插入一个节点。
200 if (node == null) {
201 // 维护size的大小。
202 size++;
203 // 如果此时,直接创建一个Node的话,没有和二叉树挂接起来。
204 // 如何让此节点挂接到二叉树上呢,直接将创建的节点return返回回去即可,返回给调用的上层。
205 return new Node(e);
206 }
207
208 // 递归的第二部分。递归调用的逻辑。
209 if (e.compareTo(node.e) < 0) {
210 // 如果待插入元素e小于node的元素e,递归调用add方法,参数一是向左子树添加左孩子。
211 // 向左子树添加元素e。
212 // 向左子树添加元素e的时候,为了让整颗二叉树发生改变,在node的左子树中插入元素e,
213 // 插入的结果,有可能是变化的,所以就要让node的左子树连接住这个变化。
214
215 // 注意,如果此时,node.left是空的话,这次add操作相应的就会返回一个新的Node节点,
216 // 对于这个新的节点,我们的node.left被赋值这个新的节点,相当于我们就改变了整棵二叉树。
217 node.left = add(node.left, e);
218 } else if (e.compareTo(node.e) > 0) {
219 // 如果待插入元素e大于node的元素e,递归调用add方法,参数一是向右子树添加右孩子。
220 // 向右子树添加元素e。
221 node.right = add(node.right, e);
222 }
223
224 // 注意,如果如果待插入元素e等于node的元素e,不进行任何操作。
225
226 // 最后将以node为根的二叉树返回回去。
227 // 不管在第二部分产生了什么变化,如果我们的node不为空的话,我们进去了第二部分,
228 // 向以node为根的二分搜索树中插入元素e之后,最终,插入了这个节点以后,
229 // 二分搜索树的根呢,还是这个node。
230 return node;
231 }
232
233
234 /**
235 * 查看二分搜索树中是否包含元素e
236 *
237 * @param e
238 * @return
239 */
240 public boolean contains(E e) {
241 // 递归实现,递归的过程中,就要从这个二分搜索树的根节点开始,逐渐的转移在新的二分搜索树的子树中,
242 // 缩小问题规模,缩小查询的树的规模,直到发现找到这个元素e或者找不到这个元素e。
243
244 // 整体是看以我们这整棵二分搜索树为根的二分搜索树中是否包含元素e。
245 return contains(root, e);
246 }
247
248 /**
249 * 看以node为根的二分搜索树中是否包含元素e,递归算法
250 * <p>
251 * 二分搜索树查询元素,对于查询元素来说,我们只要不停的看节点node里面保存的元素就好了。
252 * 不牵扯到二分搜索树,添加一个元素之后,又如何把它挂接到整个二分搜索树中。
253 *
254 * @param node 节点Node
255 * @param e 带查询的元素e
256 * @return
257 */
258 private boolean contains(Node node, E e) {
259 // 递归的第一部分
260 if (node == null) {
261 // 如果node节点为空,是不包含元素e的,此时直接返回false
262 return false;
263 }
264
265 // 递归的第二部分,开始逻辑判断
266 if (e.compareTo(node.e) == 0) {
267 // 如果待查询元素e和node的元素e相等
268 return true;
269 } else if (e.compareTo(node.e) < 0) {
270 // 如果待查询元素e小于node的元素e,如果此二分搜索树中还包含元素e的话,那么只可能在node的左子树
271 return contains(node.left, e);
272 } else {
273 // 如果待查询元素e大于node的元素e,如果此二分搜索树中还包含元素e的话,那么只可能在node的右子树
274 return contains(node.right, e);
275 }
276 }
277
278
279 /**
280 * 二分搜索树的前序遍历。二分搜索树的遍历操作,就是把所有节点都访问一遍。
281 * 对于二分搜索树的遍历操作来说,两棵子树都要顾及,区别于添加或者查询是否包含,
282 * 只走左子树或者右子树。
283 * <p>
284 * <p>
285 * 二分搜索树的前序遍历。为什么这种遍历称为前序遍历呢,是因为先访问这个节点,
286 * 再访问左右子树,也就是说,访问这个节点放在了访问左右子树的前面,所以叫做前序遍历。
287 * 基于此,也就有了二叉树的中序遍历和后序遍历。
288 */
289 public void preOrder() {
290 // 需要指定递归的调用,指定是那一棵二叉树进行的前序遍历。
291
292 // 用户的初始的调用,只需要对root根节点调用递归的preOrder就行了。
293 preOrder(root);
294 }
295
296 /**
297 * 前序遍历以node为根的二分搜索树,递归算法。
298 * <p>
299 * 前序遍历思路。
300 * 首先先遍历这个节点,再遍历这个节点的左子树,之后遍历这个节点的右子树。
301 * <p>
302 * 前序遍历是最自然的遍历方式,同时也是最常用的遍历方式。如果没有特殊情况下,在大多数情况下都是使用前序遍历。
303 *
304 * @param node
305 */
306 private void preOrder(Node node) {
307 // 递归的第一部分
308 if (node == null) {
309 // 如果node为空的话,直接返回
310 return;
311 }
312
313 // 递归的第二部分,开始遍历
314 System.out.println(node.e);
315 // 递归的调用根节点root的左子树。
316 preOrder(node.left); // 此处是循环遍历左孩子,直到左孩子为空,直接返回。
317 // 递归的调用根节点root的右子树。
318 preOrder(node.right); // 执行完上面循环遍历左孩子,执行下面的循环遍历右孩子,直到右孩子是空,直接返回。
319 // // 此时,完成了二分搜索树的前序遍历。
320
321
322 // 升级版递归过程
323 // if (node != null) {
324 // // 递归的第二部分,开始遍历
325 // System.out.println(node.e);
326 // // 递归的调用根节点root的左子树。
327 // preOrder(node.left);
328 // // 递归的调用根节点root的右子树。
329 // preOrder(node.right);
330 // // 此时,完成了二分搜索树的前序遍历。
331 // }
332 }
333
334
335 /**
336 * 二分搜索树的的前序遍历的非递归方式实现。
337 */
338 public void preOrderNonRecursive() {
339 // 栈的作用是记录下面要到底要访问那些节点,记录下一次依次要访问那些节点。
340 // 泛型是Node类型的,存储的二叉树节点类型的对象。
341 Stack<Node> stack = new Stack<Node>();
342 // 初始的时候将root根节点push进去
343 stack.push(root);
344
345 // 进行循环操作,只要stack.isEmpty()为false,说明了栈里面有元素。
346 // !stack.isEmpty()说明了记录了下面要访问那个节点。
347 while (!stack.isEmpty()) {
348 // 只要栈不为空,说明记录了下面要访问那个节点。
349 // 就要进行访问这个节点。
350
351 // 当前访问的节点。
352 Node current = stack.pop();//将当前的栈顶元素拿出来。
353 // 此时current就是当前要访问的节点。当前要访问的节点直接打印即可。
354 System.out.println(current.e);
355
356
357 // 访问了当前节点之后,就要依次访问当前节点的左子树,右子树。
358 // 由于栈是后入先出的,所以先将当前节点的右子树push进去。
359 // 此时应该判断当前节点的右子树是否为空,如果为空,就不要压入栈了。
360 if (current.right != null) {
361 stack.push(current.right);// 右子树压入栈
362 }
363 // 此时应该判断当前节点的左子树是否为空,如果为空,就不要压入栈了。
364 if (current.left != null) {
365 stack.push(current.left);//左子树压入栈
366 }
367 }
368
369 }
370
371
372 /**
373 * 二分搜索树的中序遍历。
374 * <p>
375 * 二分搜索树的的中序遍历,先访问这个节点的左子树,再访问这个节点,再访问这个节点的右子树。
376 * 中序遍历的中就体现在访问该节点放在遍历这个节点的左子树和右子树的中间。
377 */
378 public void inOrder() {
379 inOrder(root);
380 }
381
382 /**
383 * 中序遍历以node为根的二分搜索树,递归算法。
384 * <p>
385 * <p>
386 * 二分搜索树的中序遍历结果是顺序的。有时候,因为这个功能,二分搜索树也叫做排序树。
387 *
388 * @param node
389 */
390 private void inOrder(Node node) {
391 // 递归的第一部分,递归终止的条件
392 if (node == null) {
393 // 如果node为空的话,直接返回
394 return;
395 }
396
397 // 递归的第二部分,开始遍历
398 // 递归的调用根节点root的左子树。
399 inOrder(node.left); // 此处是循环遍历左孩子,直到左孩子为空,直接返回。
400 // 此程序就是简单的打印node节点的元素。就是访问这个节点元素的过程。
401 System.out.println(node.e);
402 // 递归的调用根节点root的右子树。
403 inOrder(node.right); // 执行完上面循环遍历左孩子,执行下面的循环遍历右孩子,直到右孩子是空,直接返回。
404 // 此时,完成了二分搜索树的中序遍历。
405 }
406
407
408 /**
409 * 后续遍历,二分搜索树的后序遍历。
410 */
411 public void postOrder() {
412 postOrder(root);
413 }
414
415 /**
416 * 二分搜索树的的后序遍历。
417 * <p>
418 * 二分搜索树的的后序遍历,先访问这个节点的左子树,再访问这个节点的右子树,最后再访问这个节点。
419 * <p>
420 * 后续遍历必须先处理完左子树,再处理完右子树,最后处理这个节点。
421 * <p>
422 * 后续遍历的一个应用,为二分搜索树释放内存。先释放左右孩子的内存,最后释放这个节点的内存。
423 *
424 * @param node
425 */
426 private void postOrder(Node node) {
427 // 递归的第一部分,递归终止的条件
428 if (node == null) {
429 // 如果node为空的话,直接返回
430 return;
431 }
432
433 // 递归的第二部分,开始遍历
434 // 递归的调用根节点root的左子树。
435 postOrder(node.left); // 此处是循环遍历左孩子,直到左孩子为空,直接返回。
436 // 递归的调用根节点root的右子树。
437 postOrder(node.right); // 执行完上面循环遍历左孩子,执行下面的循环遍历右孩子,直到右孩子是空,直接返回。
438 // 此程序就是简单的打印node节点的元素。就是访问这个节点元素的过程。
439 System.out.println(node.e);
440 // 此时,完成了二分搜索树的后序遍历。
441 }
442
443
444 /**
445 * 二分搜索树的层序遍历
446 * <p>
447 * <p>
448 * 相对于深度优先遍历,广度优先遍历最大的有点,可以更快的找到你想要查询的那个元素,
449 * 这样的区别,主要用于搜索策略上,而不是用于遍历这种操作上,
450 * 因为遍历需要将所有的元素都访问一遍,在这种情况下,深度优先遍历,
451 * 广度优先遍历是没有区别的。但是如果想要在一棵树中找到某个问题的解的话,
452 * 对于深度优先遍历来说,将从根节点一下子访问到树的最深的地方,
453 * 但是问题的解很可能在树的上面,所以深度优先遍历先估计左子树,
454 * 需要很长的时间才能访问到最上面,在这种情况下,广度优先遍历就很有意义了,
455 * 这种问题的模型,最常用于算法设计中的最短路径的。
456 */
457 public void levelOrder() {
458 // 由于Queue是接口,这里使用链表的方式实现该Queue。
459 Queue<Node> queue = new LinkedList<Node>();
460 // 将根节点添加到队列中
461 queue.add(root);
462 // 循环遍历,当队列不为空的时候,queue.isEmpty()结果为false表示队列不为空,
463 // 当!queue.isEmpty()表示队列不为空的时候,继续循环遍历。
464 while (!queue.isEmpty()) {
465 // 声明一个当前的节点current,也就是我们队列中的元素出队之后的那个元素,
466 // 就是我们当前要访问的这个元素。
467 Node current = queue.remove();
468 // 对于当前要访问的这个元素,可以进行打印输出
469 System.out.println(current.e);
470
471 // 之后,根据当前访问的元素来看当前的这个节点左右孩子,如果有左孩子或者右孩子进行入队。
472 if (current.left != null) {
473 queue.add(current.left);
474 }
475 // 如果当前节点有右孩子,就将当前节点的右孩子进行入队操作。
476 if (current.right != null) {
477 queue.add(current.right);
478 }
479 }
480
481 }
482
483
484 /**
485 * 寻找二分搜索树的最小元素。
486 * <p>
487 * <p>
488 * 此时,使用递归的算法比写非递归的算法,要麻烦一点,因为这里相当于我们不停的只想左走,
489 * 根本不考虑每一个节点的它的右子树,或者是右孩子,那么此时呢,我们跟操作一个链表是没有区别的,
490 * 相当于我们在操作对于每一个节点的next就是node.left这样的一个链表,找它的尾节点而已。
491 *
492 * @return
493 */
494 public E minimum() {
495 // 首先,判断二分搜索树中元素个数为零,说明二分搜索树中没有元素,就抛出异常。
496 if (size == 0) {
497 // 首先,判断二分搜索树中元素个数为零,就抛出异常。
498 throw new IllegalArgumentException("BinarySearchTree is Empty.");
499 }
500
501 // 调用递归的方式进行查询最小值
502 Node minimum = minimum(root);
503 // 此时将返回的最小节点的元素值e返回即可。
504 return minimum.e;
505 }
506
507 /**
508 * 返回以node为根的二分搜索树的最小值所在的节点。
509 *
510 * @param node
511 */
512 private Node minimum(Node node) {
513 // 递归算法,第一个部分,递归终止的条件
514 // 如果向左走,走不动了,这个就是最左节点了,即最小值
515 if (node.left == null) {
516 return node;
517 } else {
518 // 递归算法,第二部分,即如果节点最左节点不为空
519 // 将这个节点的左孩子作为node传递进去,依次查看最左节点的值。
520 return minimum(node.left);
521 }
522 }
523
524
525 /**
526 * 寻找二分搜索树的最大元素。
527 *
528 * @return
529 */
530 public E maximum() {
531 // 首先,判断二分搜索树中元素个数为零,说明二分搜索树中没有元素,就抛出异常。
532 if (size == 0) {
533 // 首先,判断二分搜索树中元素个数为零,就抛出异常。
534 throw new IllegalArgumentException("BinarySearchTree is Empty.");
535 }
536
537 // 调用递归的方式进行查询最大值
538 Node maximum = maximum(root);
539 // 此时将返回的最大节点的元素值e返回即可。
540 return maximum.e;
541 }
542
543 /**
544 * 返回以node为根的二分搜索树的最大值所在的节点。
545 *
546 * @param node
547 */
548 private Node maximum(Node node) {
549 // 递归算法,第一个部分,递归终止的条件
550 // 如果向右走,走不动了,这个就是最右节点了,即最大值
551 if (node.right == null) {
552 return node;
553 } else {
554 // 递归算法,第二部分,即如果节点最右节点不为空
555 // 将这个节点的右孩子作为node传递进去,依次查看最右节点的值。
556 return maximum(node.right);
557 }
558 }
559
560
561 /**
562 * 从二分搜索树中删除最小值所在节点,返回最小值。
563 *
564 * @return
565 */
566 public E removeMin() {
567 // 将删除的元素删除掉
568 E ret = minimum();
569
570 // 设计删除最小值的逻辑。最小值所在的节点从二分搜索树中删除掉。
571 // 从根节点开始,尝试从root节点开始,删除最小值所在的节点。
572
573 // 将删除最小值以后的节点返回给root根节点。
574 // 换句话说,我们从root为根的二分搜索树删除掉了最小值,
575 // 之后又返回了删除掉最小值之后的那棵二分搜索树对应的根节点。
576 // 这个根节点就是新的root。
577 root = removeMin(root);
578
579 // 最后,将待删除元素删除掉就行了。
580 return ret;
581 }
582
583 /**
584 * 删除掉以node为根的二分搜索树中的最小节点。
585 * 返回删除节点后新的二分搜索树的根。
586 * <p>
587 * <p>
588 * 这个逻辑就是在这种情况下,删除node节点的左子树对应的最小值,删除掉之后,对于我们当前
589 * 这个以node为根的二分搜索树,在做完这些操作之后,它的根节点依然是node,将它返回回去。
590 *
591 * @param node
592 */
593 private Node removeMin(Node node) {
594 // 递归调用,递归到底,终止条件。
595 // 就是节点左子树为空的时候,就是向左走,直到不能再走的时候,就终止条件
596 // 就是当前这个节点不能再向左走了,即当前这个节点就是最小值。
597 // 所在的节点,就是这个待删除的节点。
598 if (node.left == null) {
599 // 我们要删除当前这个节点,但是当前这个节点可能有右子树的,则右子树的部分不可以丢失掉。
600 // reightNode保存当前节点的右子树。
601 Node reightNode = node.right;
602 // 保存当前节点的右子树之后,就将当前节点的右子树置空就行了。
603 // 将当前节点的右子树和这个二分搜索树脱离关系。
604 node.right = null;
605 // 返回保存的右子树,为什么返回这个呢,因为这个函数做的事情就是删除掉以node为根的二分搜索树中的最小节点,
606 // 返回删除节点后新的二分搜索树的根,此时,最小节点就是node节点本身,将node删除掉之后,
607 // 新的二分搜索树的根就是node.right,就是node的右孩子,它就是node的右子树对应的那个根节点。
608 // 如果node的右孩子为空,没有关系,就说明node的右子树为空,一棵空树,它的根节点还是空。
609
610 // 维护size的大小。因为删除掉一个元素,所以要维护size的大小。
611 size--;
612 return reightNode;
613 // 这就是删除最小节点这个算法来说,递归到底的情况。
614 }
615
616
617 // 如果此时,没有递归到底,就说明还有左孩子。
618 // 就是进行递归操作的第二部分就行了。去删除掉这个当前节点node的左子树所对应的最小值。
619 // Node removeMin = removeMin(node.left);
620 // 删除掉以node为根的二分搜索树中的最小节点。
621 // 返回删除节点后新的二分搜索树的根。
622 // 这样才可以真正改变二分搜索树的结构。
623 // node.left = removeMin;
624 node.left = removeMin(node.left);
625
626 // 返回当前节点
627 return node;
628 }
629
630
631 /**
632 * 从二分搜索树中删除最大值所在节点,返回最大值。
633 * <p>
634 * 删除最大值,类比删除最小值的思路即可。
635 *
636 * @return
637 */
638 public E removeMax() {
639 // 将删除的元素删除掉
640 E ret = maximum();
641
642 root = removeMax(root);
643
644 // 最后,将待删除元素删除掉就行了。
645 return ret;
646 }
647
648
649 /**
650 * 删除掉以node为根的二分搜索树中的最大节点。
651 * 返回删除节点后新的二分搜索树的根。
652 *
653 * @param node
654 */
655 private Node removeMax(Node node) {
656 // 当走到该节点最右孩子的时候,即最右孩子是空的时候,就走到了最底。
657 if (node.right == null) {
658 // 保存当前节点的左子树。因为对于当前节点,右子树已经为空了。
659 // 删除掉这个节点之后,这个节点的左子树的根节点就是新的根节点,
660 Node leftNode = node.left;
661 // 保存当前节点的左子树之后,就将当前节点的左子树置空就行了。
662 // 将当前节点的左子树和这个二分搜索树脱离关系。
663 node.left = null;
664 // 删除节点,维护size的大小
665 size--;
666 // 删除掉这个节点之后,那么,这个节点的左子树的根节点,就是新的根节点。
667 return leftNode;
668 }
669
670 // 如果递归没有到到底的话,我们做的事情就是去删除当前这个节点右子树中的最大值,
671 // 将最终的结果返回给当前的这个节点的右孩子。然后返回node节点。
672 node.right = removeMax(node.right);
673
674 // 返回当前节点
675 return node;
676 }
677
678
679 /**
680 * 从二分搜索树中删除元素为e的节点。
681 *
682 * @param e
683 */
684 public void remove(E e) {
685 // 参数一是根节点,参数二是待删除元素
686
687 // 将删除掉元素e之后d得到的新的二分搜索树的根节点返回回来
688 root = remove(root, e);
689 }
690
691 /**
692 * 删除掉以node为根的二分搜索树中值为e的节点,递归算法。
693 * 返回删除节点后新的二分搜索树的根。
694 * <p>
695 * <p>
696 * 删除左右都有孩子的节点d,找到p = max(d -> node.left)。p是d的前驱。
697 * 此删除方法是找到待删除节点的后继,也可以找到当前节点的前驱。
698 *
699 * @param node
700 * @param e
701 */
702 private Node remove(Node node, E e) {
703 // 如果node节点为空,直接返回空即可。
704 // 另外一层含义,在二分搜索树中找这个元素为e的节点,根本没有找到,最后找到node为空的位置了,
705 // 直接返回空就行了。
706 if (node == null) {
707 return null;
708 }
709
710 // 递归函数,开始近逻辑
711 // 如果待删除元素e和当前节点的元素e进行比较,如果待删除元素e小于该节点的元素e
712 if (e.compareTo(node.e) < 0) {
713 // 此时,去该节点的左子树,去找到待删除元素节点
714 // 递归调用,去node的左子树,去删除这个元素e。
715 // 最后将删除的结果赋给该节点左子树。
716 node.left = remove(node.left, e);
717 return node;
718 } else if (e.compareTo(node.e) > 0) {
719 // 如果待删除元素e大于该节点的元素e
720 // 去当前节点的右子树去寻找待删除元素节点
721 // 将删除后的结果返回给当前节点的右孩子
722 node.right = remove(node.right, e);
723 return node;
724 } else {
725 // 当前节点元素e等于待删除节点元素e,即e == node.e,
726 // 相等的时候,此时就是要删除这个节点的。
727
728 // 如果当前节点node的左子树为空的时候,待删除节点左子树为空的情况
729 if (node.left == null) {
730 // 保存该节点的右子树
731 Node rightNode = node.right;
732 // 将node和这棵树断开关系
733 node.right = null;
734 // 维护size的大小
735 size--;
736 // 返回原来那个node的右孩子。也就是右子树的根节点,此时就将node删除掉了
737 return rightNode;
738 }
739
740 // 如果当前节点的右子树为空,待删除节点右子树为空的情况。
741 if (node.right == null) {
742 // 保存该节点的左子树
743 Node leftNode = node.left;
744 // 将node节点和这棵树断开关系
745 node.left = null;
746 // 维护size的大小
747 size--;
748 //返回原来那个节点node的左孩子,也就是左子树的根节点,此时就将node删除掉了。
749 return leftNode;
750 }
751
752 // 待删除节点左右子树均为不为空的情况。
753 // 核心思路,找到比待删除节点大的最小节点,即待删除节点右子树的最小节点
754 // 用这个节点顶替待删除节点的位置。
755
756 // 找到当前节点node的右子树中的最小节点,找到比待删除节点大的最小节点。
757 // 此时的successor就是node的后继。
758 Node successor = minimum(node.right);
759 // 此时将当前节点node的右子树中的最小节点删除掉,并将二分搜索树的根节点返回。
760 // 将新的二分搜索树的根节点赋值给后继节点的右子树。
761 successor.right = removeMin(node.left);
762
763 // 因为removeMin操作,删除了一个节点,但是此时当前节点的右子树的最小值还未被删除
764 // 被successor后继者指向了。所以这里做一些size加加操作,
765 size++;
766
767 // 将当前节点的左子树赋值给后继节点的左子树上。
768 successor.left = node.left;
769 // 将node节点没有用了,将node节点的左孩子和右孩子置空。让node节点和二分搜索树脱离关系
770 node.left = node.right = null;
771
772 // 由于此时,将当前节点node删除掉了,所以这里做一些size减减操作。
773 size--;
774
775 // 返回后继节点
776 return successor;
777 }
778
779 }
780
781
782 @Override
783 public String toString() {
784 StringBuilder stringBuilder = new StringBuilder();
785 // 使用一种形式展示整个二分搜索树,可以先展现根节点,再展现左子树,再展现右子树。
786 // 上述这种过程就是一个前序遍历的过程。
787 // 参数一,当前遍历的二分搜索树的根节点,初始调用的时候就是root。
788 // 参数二,当前遍历的这棵二分搜索树的它的深度是多少,根节点的深度是0。
789 // 参数三,将字符串传入进去,为了方便生成字符串。
790 generateBSTString(root, 0, stringBuilder);
791
792 return stringBuilder.toString();
793 }
794
795 /**
796 * 生成以node为根节点,深度为depth的描述二叉树的字符串。
797 *
798 * @param node 节点
799 * @param depth 深度
800 * @param stringBuilder 字符串
801 */
802 private void generateBSTString(Node node, int depth, StringBuilder stringBuilder) {
803 // 递归的第一部分
804 if (node == null) {
805 // 显示的,将在字符串中追加一个空字符串null。
806 // 为了表现出当前的空节点对应的二分搜索树的层次,封装了一个方法。
807 stringBuilder.append(generateDepthString(depth) + "null\n");
808 return;
809 }
810
811
812 // 递归的第二部分
813 // 当当前节点不为空的时候,就可以直接访问当前的node节点了。
814 // 将当前节点信息放入到字符串了
815 stringBuilder.append(generateDepthString(depth) + node.e + "\n");
816
817 // 递归进行调用
818 generateBSTString(node.left, depth + 1, stringBuilder);
819 generateBSTString(node.right, depth + 1, stringBuilder);
820 }
821
822 /**
823 * 为了表现出二分搜索树的深度
824 *
825 * @param depth
826 * @return
827 */
828 private String generateDepthString(int depth) {
829 StringBuilder stringBuilder = new StringBuilder();
830 for (int i = 0; i < depth; i++) {
831 stringBuilder.append("--");
832 }
833 return stringBuilder.toString();
834 }
835
836
837 public static void main(String[] args) {
838 BinarySearchTree<Integer> binarySearchTree = new BinarySearchTree<Integer>();
839 int[] nums = new int[]{1, 5, 3, 6, 8, 4, 2};
840 // for (int i = 0; i < nums.length; i++) {
841 // // 二分搜索树的新增
842 // binarySearchTree.add(nums[i]);
843 // }
844 for (int num : nums) {
845 binarySearchTree.add(num);
846 }
847
848
849 // 二分搜索树的前序遍历
850 binarySearchTree.preOrder();
851 System.out.println();
852
853
854 // 二分搜索树的中序遍历
855 binarySearchTree.inOrder();
856 System.out.println();
857
858 // 二分搜索树的后序遍历
859 binarySearchTree.postOrder();
860 System.out.println();
861
862 // 二分搜索树的非递归的前序遍历。
863 binarySearchTree.preOrderNonRecursive();
864 System.out.println();
865
866 // 二分搜索树的非递归的层序遍历。
867 binarySearchTree.levelOrder();
868 System.out.println();
869
870 // 二分搜索树的递归的删除任意元素
871 System.out.println("二分搜索树的递归的删除任意元素.");
872 binarySearchTree.remove(5);
873 System.out.println(binarySearchTree);
874
875
876 // System.out.println(binarySearchTree.toString());
877 // 5
878 // --3
879 // ----2
880 // ------null
881 // ------null
882 // ----4
883 // ------null
884 // ------null
885 // --6
886 // ----null
887 // ----8
888 // ------null
889 // ------null
890
891
892 // 二分搜索树的递归的删除最小值
893 // BinarySearchTree<Integer> binarySearchTree = new BinarySearchTree<Integer>();
894 // Random random = new Random();
895 // int n = 1000;
896 // for (int i = 0; i < n; i++) {
897 // // 随机添加1000个0-10000之间的数字。有可能重复,总数可能小于1000
898 // binarySearchTree.add(random.nextInt(10000));
899 // }
900 //
901 // ArrayList<Integer> nums = new ArrayList<Integer>();
902 // while (!binarySearchTree.isEmpty()) {
903 // nums.add(binarySearchTree.removeMin());
904 // }
905 // System.out.println(nums);
906 //
907 // // 判断是否是从小到大排序的
908 // for (int i = 1; i < nums.size(); i++) {
909 // if (nums.get(i - 1) > nums.get(i)) {
910 // throw new IllegalArgumentException("Error.");
911 // }
912 // }
913 // System.out.println("removeMin test completed.");
914
915
916 // 二分搜索树的递归的删除最大值
917 // BinarySearchTree<Integer> binarySearchTree2 = new BinarySearchTree<Integer>();
918 // Random random2 = new Random();
919 // int n2 = 1000;
920 // for (int i = 0; i < n2; i++) {
921 // // 随机添加1000个0-10000之间的数字。有可能重复,总数可能小于1000
922 // binarySearchTree2.add(random2.nextInt(10000));
923 // }
924 //
925 // ArrayList<Integer> nums2 = new ArrayList<Integer>();
926 // while (!binarySearchTree2.isEmpty()) {
927 // nums2.add(binarySearchTree2.removeMax());
928 // }
929 // System.out.println(nums2);
930 //
931 // // 判断是否是从小到大排序的
932 // for (int i = 1; i < nums2.size(); i++) {
933 // if (nums2.get(i - 1) < nums2.get(i)) {
934 // throw new IllegalArgumentException("Error.");
935 // }
936 // }
937 // System.out.println("removeMax test completed.");
938
939 }
940
941 }