M3ER: Multiplicative multimodal emotion recognition using facial, textual, and speech cues
模型总体结构
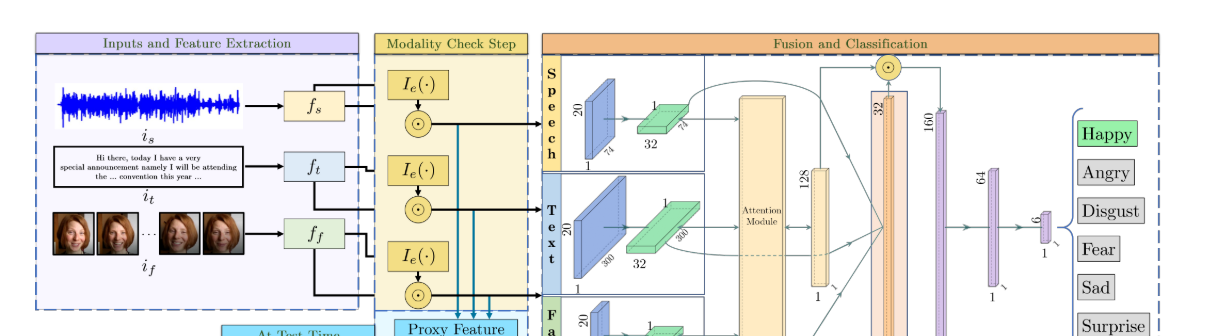
我们使用三种模态特征,即语音,文本和面部特征。 、
流程如下:
- 提取特征以从原始输入is,if和if(紫色框)中获取fs,ft,ff。
- 检查特征向量是否有效。 我们使用指标函数Ie来处理特征向量(黄色框)。
- 将这- 些向量传递到M3ER的分类和融合网络中,以预测情绪(橙色框)。
- 在判断是否有效时,如果遇到有噪声的模态,我们将为该特定模态(蓝框)重新生成代理特征向量**(ps,pt或pf)**
下面会介绍模型的3个 重要结构
检查特征向量模块
作者引入了“模态检查”步骤,该步骤可以过滤无效数据。
作者认为:对于有效的数据,其相应的有效模态信号 至少与另一个模态信号相关。 我们直接利用这种相关性概念来区分可能对情感分类有效的特征(有效特征)和嘈杂的特征(无效特征)。作者使用典型相关分析(CCA)以计算相关分数
- 通过射影变换 把不同模态的特征 映射到同一纬度(100) i j 属于 {face, text, speech}

- 计算相关性
- 判断是否有效 Ie函数
生成代理特征向量模块
如果在模态检查步骤中的一个或多个模态被检测为无效的,我们将使用以下方程式为无效模态生成代理特征向量
其中T 表示一个线性变换
- 找到 Vj 是的 Vj 和 Ff 距离最短
- 解一个线性方程得到 ai
- 用得到的 ai 计算Ps
乘法模态融合
作者收到(Liu et al. 2018) 的损失函数启发; 此方法用乘法的和 来 抑制弱模态,间接加强强模态, 其损失函数
Pj 表示 j模态下的预测值 , β 是超参
选定i为主模态, 其它模态的预测值会相乘 最后相加
作者修改了损失函数
有点像Cross Entropy Loss 的形式
分类网络结构
用的是memory fusion network (MFN)
Zadeh, A.; Liang, P. P.; Mazumder, N.; Poria, S.; Cambria, E.; and Morency, L.-P. 2018a. Memory fusion net- work for multi-view sequential learning. AAAI
- 每个输入模态首先通过单隐藏LSTM,每个LSTM的输出维度为32。
- LSTM的输出以及初始化为全零128维内存变量将其传递给 attention module (MFN 提出的)
小节
- 文章创新的使用 模态特征检测, 差的模态特征向量就不用
- 得到一种生成代理特征的方法, 不过具体怎么生成还没搞太清楚
- 乘法融合那一块没怎么看懂,感觉和一般损失函数差不多, 可能他这个是三个模态的特征分别算损失然后加在一起有关