这是【kudu pk parquet】的第二篇,query2在kudu和parquet上的对比解析,其中kudu包含有不能下发的谓词。
3台物理机,1T规模的数据集,impala和kudu版本是我们修改后支持runtime filter的版本,结果对比如下图:
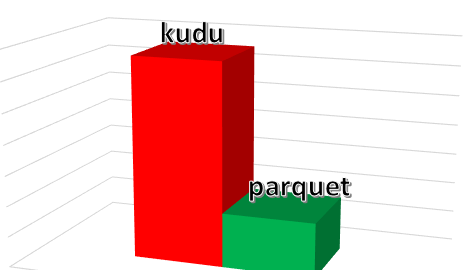
纵坐标表示耗时,矮表示性能好,耗时短,响应差近三倍。
首先,来我们来看两者的执行计划,颜色越鲜艳表示越耗时:
- parquet

- kudu
可以看到kudu左右两边各有一个鲜艳的红色框(节点),说明这两个执行节点耗时比较长,放大来看:
左边部分:
上面两个图的执行计划红色圈起来部分,parquet的扫描(“05:SCAN KUDU”)和关联(“09:HASH JOIN”)分别只要1秒钟左右,而kudu则要7秒和11秒。
大家注意到了没有,“07:SCAN KUDU”这个节点在两个引擎上返回的数据量是不一样的,parquet只返回了5条记录,kudu则返回了25条。同时这个返回结果是作为runtime filter应用于“06:SCAN KUDU”的,所以可以看到“06:SCAN KUDU”节点上返回的数据量,呈现几何级的差异(条件宽泛,所以匹配的数据量就多了)。接着,过滤出来的结果再runtime filter应用于“05:SCAN KUDU”节点。为什么“05:SCAN KUDU”节点的扫描动作会差7倍(kudu 7秒钟对比parquet 1秒钟)?
分析kudu的profile可以看到“05:SCAN KUDU”的runtime filter是在2秒钟(另外1个是在18秒后到达,无效)以后才到达的:
所以减去1秒钟的filter等待时间,对partsupp表扫描花了6秒钟时间,同样是扫描partsupp表为啥parquet只要扫描2秒钟,怎么解释?这涉及到了runtime裁剪分片,因为它们的关联键刚好是个主键
05:SCAN KUDU [kudu_1000g_2.partsupp]
runtime filters: RF000 -> kudu_1000g_2.partsupp.ps_partkey, RF004 -> ps_suppkey
mem-estimate=0B mem-reservation=0B
tuple-ids=5 row-size=24B cardinality=800000000
---------------- 所以动态裁剪分片很重要,这里就不再展开,以后有机会再解析。
扫描返回的数据多,直接导致后续的关联节点“09:HASH JOIN”时间变成11秒。
前面埋伏了1个地雷,有心的读者可以想一下。
右边部分:
上面两个图中,kudu的“00:SCAN KUDU”节点消耗了4秒钟,而parquet只需要817毫秒!
查看kudu的profile:
| | | F07:PLAN FRAGMENT [RANDOM] hosts=3 instances=3
| | | 00:SCAN KUDU [kudu_1000g_2.part]
| | | predicates: p_type LIKE '%NICKEL'
| | | kudu predicates: p_size = 22
| | | mem-estimate=0B mem-reservation=0B
| | | tuple-ids=0 row-size=75B cardinality=1264911
| | | 可以看到有个“like”的谓词,但是kudu官网说“!=”和“like”目前是不支持的:
因为kudu不支持“like”谓词的下发,所以过滤的动作需要在impala侧执行,这就需要impala把kudu上的数据全部扫描读取过来,那么这个耗时跟parquet本地过滤显然是没法比的(网络IO+序列化反序列化),近5倍的差异。
然后,左边“02:SCAN KUDU”节点的runtime filter是在4秒钟后到达:
所以partsupp全表扫了3秒钟(减去1秒钟的filter等待时间),然后应用filter,接着扫描剩下的7秒钟(11秒-4秒),也即扫描花了10秒钟时间。耗时比parquet长的原因和最前面“左边部分”的“05:SCAN KUDU”一样,也涉及到了runtime裁剪分片,因为它们的关联键也是主键:
| | 02:SCAN KUDU [kudu_1000g_2.partsupp]
| | runtime filters: RF008 -> ps_partkey
| | mem-estimate=0B mem-reservation=0B
| | tuple-ids=2 row-size=24B cardinality=800000000
| | 这里埋伏第2个地雷。
-------------------------------------------------------------------------------------------
到此,TPC-H query2在kudu和parquet上执行耗时的对比已经解析完成,接下来挖出前面埋伏的2个地雷:
- 为什么parquet上“07:SCAN KUDU”只返回5条,而kudu返回了25条?
- 在kudu执行计划中,同样是扫描partsupp表,为啥“左边部分”“05:SCAN KUDU”节点只耗时7秒钟,而“右边部分”“02:SCAN KUDU”节点则耗时11秒钟?
本文来自网易云社区,经作者何李夫授权发布。
原文地址:【kudu pk parquet】TPC-H Query2对比解析
更多网易研发、产品、运营经验分享请访问网易云社区。