這是【kudu pk parquet】的第二篇,query2在kudu和parquet上的對比解析,其中kudu包含有不能下發的謂詞。
3台實體機,1T規模的資料集,impala和kudu版本是我們修改後支援runtime filter的版本,結果對比如下圖:
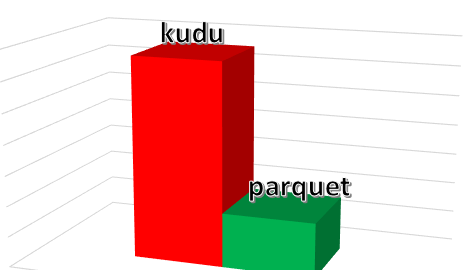
縱坐标表示耗時,矮表示性能好,耗時短,響應差近三倍。
首先,來我們來看兩者的執行計劃,顔色越鮮豔表示越耗時:
- parquet

- kudu
可以看到kudu左右兩邊各有一個鮮豔的紅色框(節點),說明這兩個執行節點耗時比較長,放大來看:
左邊部分:
上面兩個圖的執行計劃紅色圈起來部分,parquet的掃描(“05:SCAN KUDU”)和關聯(“09:HASH JOIN”)分别隻要1秒鐘左右,而kudu則要7秒和11秒。
大家注意到了沒有,“07:SCAN KUDU”這個節點在兩個引擎上傳回的資料量是不一樣的,parquet隻傳回了5條記錄,kudu則傳回了25條。同時這個傳回結果是作為runtime filter應用于“06:SCAN KUDU”的,是以可以看到“06:SCAN KUDU”節點上傳回的資料量,呈現幾何級的差異(條件寬泛,是以比對的資料量就多了)。接着,過濾出來的結果再runtime filter應用于“05:SCAN KUDU”節點。為什麼“05:SCAN KUDU”節點的掃描動作會差7倍(kudu 7秒鐘對比parquet 1秒鐘)?
分析kudu的profile可以看到“05:SCAN KUDU”的runtime filter是在2秒鐘(另外1個是在18秒後到達,無效)以後才到達的:
是以減去1秒鐘的filter等待時間,對partsupp表掃描花了6秒鐘時間,同樣是掃描partsupp表為啥parquet隻要掃描2秒鐘,怎麼解釋?這涉及到了runtime裁剪分片,因為它們的關聯鍵剛好是個主鍵
05:SCAN KUDU [kudu_1000g_2.partsupp]
runtime filters: RF000 -> kudu_1000g_2.partsupp.ps_partkey, RF004 -> ps_suppkey
mem-estimate=0B mem-reservation=0B
tuple-ids=5 row-size=24B cardinality=800000000
---------------- 是以動态裁剪分片很重要,這裡就不再展開,以後有機會再解析。
掃描傳回的資料多,直接導緻後續的關聯節點“09:HASH JOIN”時間變成11秒。
前面埋伏了1個地雷,有心的讀者可以想一下。
右邊部分:
上面兩個圖中,kudu的“00:SCAN KUDU”節點消耗了4秒鐘,而parquet隻需要817毫秒!
檢視kudu的profile:
| | | F07:PLAN FRAGMENT [RANDOM] hosts=3 instances=3
| | | 00:SCAN KUDU [kudu_1000g_2.part]
| | | predicates: p_type LIKE '%NICKEL'
| | | kudu predicates: p_size = 22
| | | mem-estimate=0B mem-reservation=0B
| | | tuple-ids=0 row-size=75B cardinality=1264911
| | | 可以看到有個“like”的謂詞,但是kudu官網說“!=”和“like”目前是不支援的:
因為kudu不支援“like”謂詞的下發,是以過濾的動作需要在impala側執行,這就需要impala把kudu上的資料全部掃描讀取過來,那麼這個耗時跟parquet本地過濾顯然是沒法比的(網絡IO+序列化反序列化),近5倍的差異。
然後,左邊“02:SCAN KUDU”節點的runtime filter是在4秒鐘後到達:
是以partsupp全表掃了3秒鐘(減去1秒鐘的filter等待時間),然後應用filter,接着掃描剩下的7秒鐘(11秒-4秒),也即掃描花了10秒鐘時間。耗時比parquet長的原因和最前面“左邊部分”的“05:SCAN KUDU”一樣,也涉及到了runtime裁剪分片,因為它們的關聯鍵也是主鍵:
| | 02:SCAN KUDU [kudu_1000g_2.partsupp]
| | runtime filters: RF008 -> ps_partkey
| | mem-estimate=0B mem-reservation=0B
| | tuple-ids=2 row-size=24B cardinality=800000000
| | 這裡埋伏第2個地雷。
-------------------------------------------------------------------------------------------
到此,TPC-H query2在kudu和parquet上執行耗時的對比已經解析完成,接下來挖出前面埋伏的2個地雷:
- 為什麼parquet上“07:SCAN KUDU”隻傳回5條,而kudu傳回了25條?
- 在kudu執行計劃中,同樣是掃描partsupp表,為啥“左邊部分”“05:SCAN KUDU”節點隻耗時7秒鐘,而“右邊部分”“02:SCAN KUDU”節點則耗時11秒鐘?
本文來自網易雲社群,經作者何李夫授權釋出。
原文位址:【kudu pk parquet】TPC-H Query2對比解析
更多網易研發、産品、營運經驗分享請通路網易雲社群。