一、插件开发
模块命名规范
Reader插件名称格式: Xreader-Y
Writer插件名称格式: Xwriter-Y
其中:
X:数据源类型英⽂文名称小写 oraclereader、mysqlwriter
Y:厂商(版本) mysqlreader-5.7 hivewriter-cdh5.12.0 QuickStart
使用私服上的项目骨架进行开发
- DgroupId:新项⽬目的groupId 【保持与示例一致即可】
- Dpackage:新项⽬目的package 【保持与示例一致即可】
- Dversion:新项⽬目的version 【保持与示例一致即可】
- DarchetypeGroupId:模板⼯工程的GroupId 【保持与示例一致即可】
- DarchetypeVersion:模板⼯工程的Version 【保持与示例一致即可】
- DarchetypeArtifactId:模板⼯工程的ArtifactId
- DartifactId:新项⽬目的artifactId 建议命名方式为插件名称
jdbc类骨架
writer
mvn archetype:generate -DarchetypeGroupId=com.dtwave.dipper.datax.plugin -DarchetypeVersion=1.0.0-SNAPSHOT -X -DarchetypeCatalog=local -DgroupId=com.dtwave.datax.plugin -Dpackage=com.dtwave.dipper.datax.plugin -Dversion=1.0.0-SNAPSHOT -DarchetypeArtifactId=dataxwriterplugin-archetype -DartifactId= reader
mvn archetype:generate -DarchetypeGroupId=com.dtwave.dipper.datax.plugin -DarchetypeVersion=1.0.0-SNAPSHOT -X -DarchetypeCatalog=local -DgroupId=com.dtwave.datax.plugin -Dpackage=com.dtwave.dipper.datax.plugin -Dversion=1.0.0-SNAPSHOT -DarchetypeArtifactId=dataxreaderplugin-archetype -DartifactId= Hadoop类骨架
需要指定厂商和版本,添加参数-Dvendor,例如:
cdh5.12.0 -Dvendor=cdh5.12.0
cdh6.1.0 -Dvendor=cdh6.1.0
apache -Dvendor=apache
mvn archetype:generate -DarchetypeGroupId=com.dtwave.dipper.datax.plugin -DarchetypeVersion=1.0.0-SNAPSHOT -X -DarchetypeCatalog=local -DgroupId=com.dtwave.datax.plugin -Dpackage=com.dtwave.dipper.datax.plugin -Dversion=1.0.0-SNAPSHOT -DarchetypeArtifactId=dataxhadoopwriterplugin-archetype -DartifactId= -Dvendor= mvn archetype:generate -DarchetypeGroupId=com.dtwave.dipper.datax.plugin -DarchetypeVersion=1.0.0-SNAPSHOT -X -DarchetypeCatalog=local -DgroupId=com.dtwave.datax.plugin -Dpackage=com.dtwave.dipper.datax.plugin -Dversion=1.0.0-SNAPSHOT -DarchetypeArtifactId=dataxhadoopreaderplugin-archetype -DartifactId= -Dvendor= 其他类骨架
其他的一些数据源,例如es,需要使用自身的api,通用实现无法适用,则使用common骨架
主要的区别在于mvn的依赖,只依赖了datax-common
mvn archetype:generate -DarchetypeGroupId=com.dtwave.dipper.datax.plugin -DarchetypeVersion=1.0.0-SNAPSHOT -X -DarchetypeCatalog=local -DgroupId=com.dtwave.datax.plugin -Dpackage=com.dtwave.dipper.datax.plugin -Dversion=1.0.0-SNAPSHOT -DarchetypeArtifactId=dataxcommonwriterplugin-archetype -DartifactId= mvn archetype:generate -DarchetypeGroupId=com.dtwave.dipper.datax.plugin -DarchetypeVersion=1.0.0-SNAPSHOT -X -DarchetypeCatalog=local -DgroupId=com.dtwave.datax.plugin -Dpackage=com.dtwave.dipper.datax.plugin -Dversion=1.0.0-SNAPSHOT -DarchetypeArtifactId=dataxcommonreaderplugin-archetype -DartifactId= 其中骨架生成的目录结构如下
.
├── doc
│ └── README.md 插件文档
├── pom.xml
├── src
│ └── main
│ ├── assembly
│ │ └── package.xml 打包配置
│ ├── java
│ └── resources
│ └── plugin.json 插件描述 0.mvn依赖
- rdbms
<dependency>
<groupId>com.alibaba.datax</groupId>
<artifactId>plugin-rdbms-util</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<!--这里的connector依赖要改成相应数据源的-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.34</version>
</dependency> - hadoop
<properties>
<!--替换成对应集群厂商的hadoop和hive的pom版本-->
<hadoop.version>2.6.0-cdh5.12.0</hadoop.version>
<hive.version>1.1.0-cdh5.12.0</hive.version>
</properties> 1.实现接口
插件的入口类必须扩展
Reader
或
Writer
抽象类,并且实现分别实现
Job
和
Task
两个内部抽象类,
Job
Task
的实现必须是 内部类 的形式。
骨架生成项目是一个mysql插件的实现
我们已经在CommonRdbmsReader和CommonRdbmsWriter做了通用实现
可以看到,MysqlReader通过CommonRdbmsReader只需要很少的代码就可以适配了
rdbms类型的数据源适配过程和mysql基本一致
大部分情况下,只要把DBType中的typeName和driverClassName改一下就好了
public class MysqlReader extends Reader {
/**
* 数据源类型
*/
private static final DBType DB_TYPE;
static {
/*
typeName:数据源类型名称(全小写)
driverClassName:数据源jdbc驱动类
*/
DB_TYPE = new DBType("mysql", "com.mysql.jdbc.Driver");
}
public static class Job extends Reader.Job {
private static final Logger LOG = LoggerFactory.getLogger(Job.class);
private Configuration originalConfig = null;
private CommonRdbmsReader.Job commonRdbmsReaderJob;
/**
* Job对象初始化工作,测试可以通过super.getPluginJobConf()获取与本插件相关的配置。
* 读插件获得配置中reader部分,写插件获得writer部分。
*/
@Override
public void init() {
this.originalConfig = super.getPluginJobConf();
Integer userConfigedFetchSize = this.originalConfig.getInt(Constant.FETCH_SIZE);
if (userConfigedFetchSize != null) {
LOG.warn("对 mysqlreader 不需要配置 fetchSize, mysqlreader 将会忽略这项配置. 如果您不想再看到此警告,请去除fetchSize 配置.");
}
this.originalConfig.set(Constant.FETCH_SIZE, Integer.MIN_VALUE);
this.commonRdbmsReaderJob = new CommonRdbmsReader.Job(DB_TYPE);
this.commonRdbmsReaderJob.init(this.originalConfig);
}
/**
* 全局准备工作,比如odpswriter清空目标表。
*/
@Override
public void prepare() {
super.prepare();
}
/**
* 校验
*/
@Override
public void preCheck() {
this.commonRdbmsReaderJob.preCheck(this.originalConfig, DB_TYPE);
}
/**
* 拆分Task。
* 参数adviceNumber框架建议的拆分数,一般是运行时所配置的并发度。
* 值返回的是`Task`的配置列表。
*
* @param adviceNumber
* @return
*/
@Override
public List<Configuration> split(int adviceNumber) {
return this.commonRdbmsReaderJob.split(this.originalConfig, adviceNumber);
}
/**
* 全局的后置工作,比如mysqlwriter同步完影子表后的rename操作。
*/
@Override
public void post() {
this.commonRdbmsReaderJob.post(this.originalConfig);
}
/**
* Job对象自身的销毁工作。
*/
@Override
public void destroy() {
this.commonRdbmsReaderJob.destroy(this.originalConfig);
}
}
public static class Task extends Reader.Task {
private Configuration readerSliceConfig;
private CommonRdbmsReader.Task commonRdbmsReaderTask;
/**
* Task对象的初始化。此时可以通过super.getPluginJobConf()获取与本Task相关的配置。
* 这里的配置是Job的split方法返回的配置列表中的其中一个。
*/
@Override
public void init() {
this.readerSliceConfig = super.getPluginJobConf();
this.commonRdbmsReaderTask = new CommonRdbmsReader.Task(DB_TYPE, super.getTaskGroupId(), super.getTaskId());
this.commonRdbmsReaderTask.init(this.readerSliceConfig);
}
/**
* 局部的准备工作。
*/
@Override
public void prepare() {
super.prepare();
}
/**
* 从数据源读数据,写入到RecordSender中。
* RecordSender会把数据写入连接Reader和Writer的缓存队列。
*
* @param recordSender
*/
@Override
public void startRead(RecordSender recordSender) {
int fetchSize = this.readerSliceConfig.getInt(Constant.FETCH_SIZE);
this.commonRdbmsReaderTask.startRead(this.readerSliceConfig, recordSender,
super.getTaskPluginCollector(), fetchSize);
}
/**
* 局部的后置工作。
*/
@Override
public void post() {
this.commonRdbmsReaderTask.post(this.readerSliceConfig);
}
/**
* Task对象自身的销毁工作。
*/
@Override
public void destroy() {
this.commonRdbmsReaderTask.destroy(this.readerSliceConfig);
}
}
} 2.修改插件描述 plugin.json
plugin.json
在每个插件的项目中,都有一个
plugin.json
文件,这个文件定义了插件的相关信息,包括入口类。例如:
{
"name": "oraclereader",
"class": "com.alibaba.datax.plugin.writer.oraclereader.OracleReader",
"description": "插件用途",
"developer": "插件开发者",
"engineVersion": ""
} -
name
-
class
-
description
-
developer
-
engineVersion
注意:插件的目录名字必须和
plugin.json
中定义的插件名称一致。
3.打包发布
- 模块单独打包命令:
mvn clean package -DskipTests
编译好的内容存放在target/datax 下面
.
├── plugin
│ └── reader
│ └── common
│ └── mysqlreader
│ ├── libs
│ │ ├── mysqlreader-plugin-dependencies.jar
│ ├── mysqlreader-0.0.1-SNAPSHOT.jar
│ └── plugin.json - 为了运维方便部署区分厂商版本,整体打包形成压缩包目录格式根据厂商版本区分、通用组件存放在common 文件目录下
-- plugin
-- reader
-- common(通用插件)
-- mysqlreader
-- sqlserverreader
-- ...
-- hdp (hdp厂商的插件)
-- hivereader
-- ...
-- cdh5.14.2(cdh5.14.2 的插件)
-- hivereader
-- ...
-- cdh6.1.0
-- hivereader
-- ...
-- writer
-- common(通用插件)
-- mysqlwriter
-- sqlserverwriter
-- ...
-- hdp (hdp厂商的插件)
-- hivewriter
-- ...
-- cdh5.14.2(cdh5.14.2 的插件)
-- hivewriter
-- ...
-- cdh6.1.0
-- hivewriter
-- ... 4.如何调试
0. python准备
如果没有python,需要先安装
python2.7
,一定要2.7版本
1.copy插件
在
datax-plugin-test
文件夹中已经准好了下面的目录结构
.
├── bin 可执行程序目录
├── conf 框架配置目录
├── job 任务配置文件,里面有stream.json和rdbms.json的两个配置文件样例
├── lib 框架依赖库目录
├── log 运行日志
└── plugin 插件目录
plugin目录分为`reader`和`writer`子目录,读写插件分别存放。插件目录规范如下:
${PLUGIN_HOME}/libs: 插件的依赖库。
${PLUGIN_HOME}/plugin-name.jar: 插件本身的jar。
${PLUGIN_HOME}/plugin.json: 插件描述文件。
可以在终端执行python datax.py ../job/stream.json
感受一下执行过程 把打包好的插件放到plugin对应目录下
在调试时推荐另一端使用mysql。比如要写一个reader的插件,那目的端使用mysqlwriter,要写一个writer的插件,源端使用mysqlreader
2.修改配置文件
修改job路径下rdbms.json,填写正确的jdbcUrl、column以及table信息
不要忘记修改使用的插件名
reader.name
、
writer.name
配置详细信息请看第三章
配置文件
3.执行debug脚本
cd到bin目录下,执行
python datax.py ../job/mysql2mysql_config.json -d
执行脚本后会打印出远程调试端口

4.idea启动调试
设置ip和端口,本地调试的话ip就用localhost就行了,端口设置成终端打印出来的
打上断点,点击启动调试
5.写文档
一定要记得把你的成果用文档记录下来哦!!!
可以参照doc/README.md
二、如何使用 Configuration
Configuration
为了简化对json的操作,
DataX
提供了简单的DSL配合
Configuration
类使用。
Configuration
提供了常见的
get
,
带类型get
,
带默认值get
set
等读写配置项的操作,以及
clone
toJSON
等方法。配置项读写操作都需要传入一个
path
做为参数,这个
path
就是
DataX
定义的DSL。语法有两条:
- 子map用
.key
path
- 数组元素用
[index]
比如操作如下json:
{
"a": {
"b": {
"c": 2
},
"f": [
1,
2,
{
"g": true,
"h": false
},
4
]
},
"x": 4
} 比如调用
configuration.get(path)
方法,当path为如下值的时候得到的结果为:
-
x
4
-
a.b.c
2
-
a.b.c.d
null
-
a.b.f[0]
1
-
a.b.f[2].g
true
注意,因为插件看到的配置只是整个配置的一部分。使用
Configuration
对象时,需要注意当前的根路径是什么。
三、配置文件
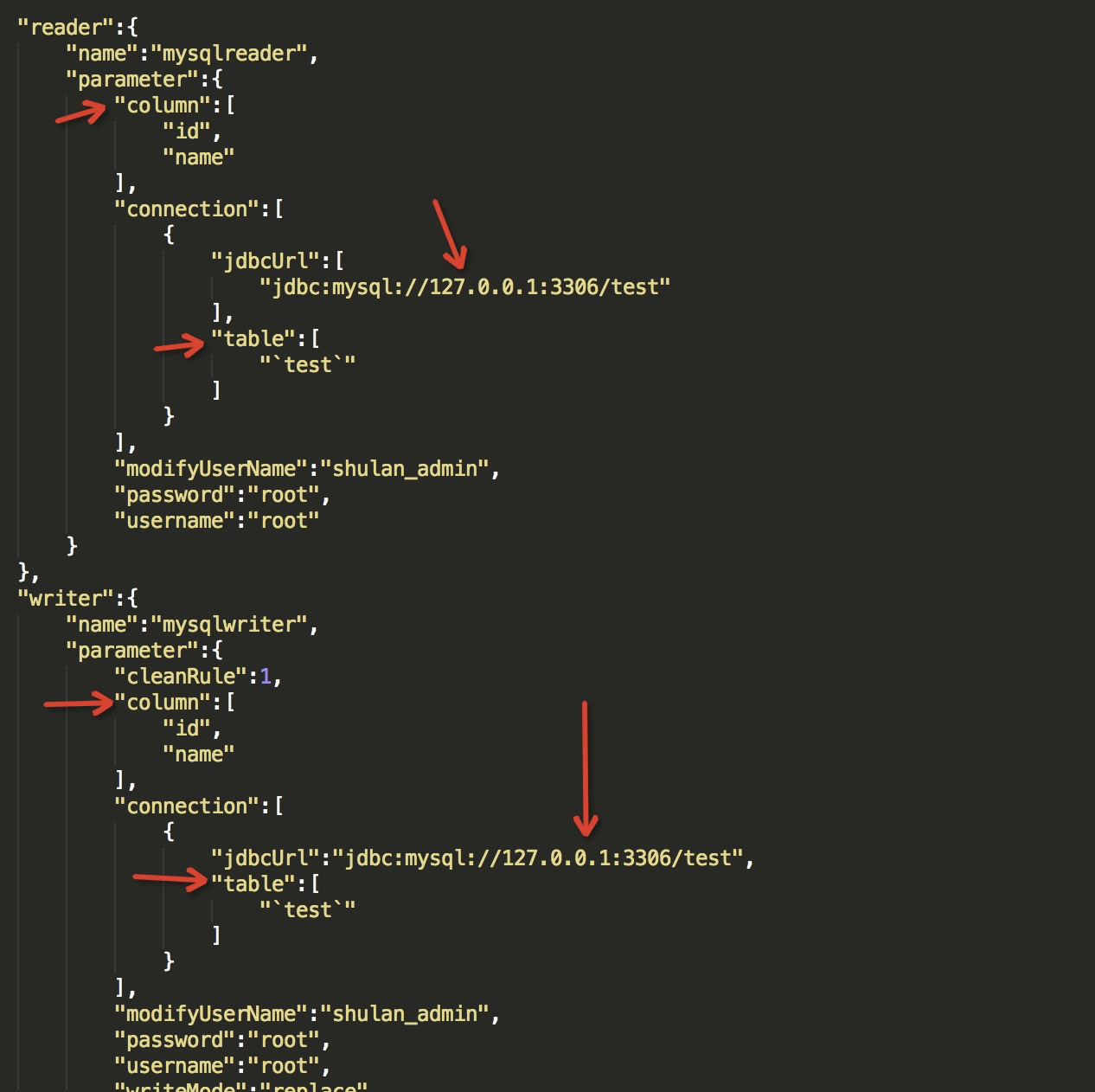
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/test"
],
"table": [
"`test`"
]
}
],
"modifyUserName": "shulan_admin",
"password": "root",
"username": "root"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"cleanRule": 1,
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test",
"table": [
"`test`"
]
}
],
"modifyUserName": "shulan_admin",
"password": "root",
"username": "root",
"writeMode": "replace"
}
}
}
],
"setting": {
"errorLimit": {
"record": 0
},
"speed": {
"channel": 5,
"throttle": false
}
}
}
} - jdbcUrl
数据库的 JDBC 连接信息。作业运行时,DataX 会在你提供的 jdbcUrl 后面追加如下属性:
- username
数据库的用户名
- password
数据库的密码
- table
表名称,支持写入一个或者多个表;当配置为多张表时,必须确保所有表结构保持一致。
注意:table 和 jdbcUrl 必须包含在 connection 配置单元中 - column
表需要写入/读取数据的字段,字段之间用英文逗号分隔。例如: "column": ["id","name","age"]。
下面是一些非必填的选项
- session
DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性
- preSql
写入数据到目的表前,会先执行这里的标准语句。比如你希望导入数据前,先对表中数据进行删除操作,那么你可以这样配置: "preSql":["delete from 表名"]
- postSql
写入数据到目的表后,会执行这里的标准语句。(原理同 preSql )
- writeMode
控制写入数据到目标表采用或者insert into
replace into
ON DUPLICATE KEY UPDATE
语句
所有选项:insert/replace/update。需要注意的是一些库可能不支持replace
默认值:insert
- batchSize
一次性批量提交的记录数大小,该值可以极大减少DataX与Mysql的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进程OOM情况。
默认值:1024
四、脏数据处理
-
什么是脏数据?
目前主要有三类脏数据:
- Reader读到不支持的类型、不合法的值。
- 不支持的类型转换,比如:
Bytes
Date
- 写入目标端失败,比如:写mysql整型长度超长。
-
如何处理脏数据
Reader.Task
Writer.Task
中,通过
AbstractTaskPlugin.getPluginCollector()
可以拿到一个
TaskPluginCollector
,它提供了一系列
collectDirtyRecord
的方法。当脏数据出现时,只需要调用合适的
collectDirtyRecord
方法,把被认为是脏数据的
Record
传入即可。
用户可以在任务的配置中指定脏数据限制条数或者百分比限制,当脏数据超出限制时,框架会结束同步任务,退出。插件需要保证脏数据都被收集到,其他工作交给框架就好。
五、整体框架
逻辑执行模型
插件开发者不用关心太多,基本只需要关注特定系统读和写,以及自己的代码在逻辑上是怎样被执行的,哪一个方法是在什么时候被调用的。在此之前,需要明确以下概念:
-
Job
Job
-
Task
Task
Job
Job
Task
-
TaskGroup
Task
TaskGroupContainer
Task
TaskGroup
-
JobContainer
Job
Job
-
TaskGroupContainer
TaskGroup
Task
简而言之,
Job
拆分成
Task
,在分别在框架提供的容器中执行,插件只需要实现
Job
Task
两部分逻辑。
物理执行模型
框架为插件提供物理上的执行能力(线程)。
DataX
框架有三种运行模式:
-
Standalone
-
Local
-
Distrubuted
DataX Service
当然,上述三种模式对插件的编写而言没有什么区别,你只需要避开一些小错误,插件就能够在单机/分布式之间无缝切换了。
当
JobContainer
TaskGroupContainer
运行在同一个进程内时,就是单机模式(
Standalone
Local
);当它们分布在不同的进程中执行时,就是分布式(
Distributed
)模式。
是不是很简单?
编程接口
那么,
Job
Task
的逻辑应是怎么对应到具体的代码中的?
首先,插件的入口类必须扩展
Reader
Writer
Job
Task
Job
Task
的实现必须是 内部类 的形式,原因见 加载原理 一节。以Reader为例:
public class SomeReader extends Reader {
public static class Job extends Reader.Job {
@Override
public void init() {
}
@Override
public void prepare() {
}
@Override
public List<Configuration> split(int adviceNumber) {
return null;
}
@Override
public void post() {
}
@Override
public void destroy() {
}
}
public static class Task extends Reader.Task {
@Override
public void init() {
}
@Override
public void prepare() {
}
@Override
public void startRead(RecordSender recordSender) {
}
@Override
public void post() {
}
@Override
public void destroy() {
}
}
} Job
接口功能如下:
-
init
super.getPluginJobConf()
reader
writer
-
prepare
-
split
Task
adviceNumber
Task
-
post
-
destroy
Task
-
init
super.getPluginJobConf()
Task
Job
split
-
prepare
-
startRead
RecordSender
RecordSender
-
startWrite
RecordReceiver
RecordReceiver
-
post
-
destroy
需要注意的是:
-
Job
Task
-
prepare
post
Job
Task
框架按照如下的顺序执行
Job
Task
的接口:
上图中,黄色表示
Job
部分的执行阶段,蓝色表示
Task
部分的执行阶段,绿色表示框架执行阶段。
相关类关系如下:
配置文件
DataX
使用
json
作为配置文件的格式。一个典型的
DataX
任务配置如下:
{
"job": {
"content": [
{
"reader": {
"name": "odpsreader",
"parameter": {
"accessKey": "",
"accessId": "",
"column": [""],
"isCompress": "",
"odpsServer": "",
"partition": [
""
],
"project": "",
"table": "",
"tunnelServer": ""
}
},
"writer": {
"name": "oraclewriter",
"parameter": {
"username": "",
"password": "",
"column": ["*"],
"connection": [
{
"jdbcUrl": "",
"table": [
""
]
}
]
}
}
}
]
}
} DataX
框架有
core.json
配置文件,指定了框架的默认行为。任务的配置里头可以指定框架中已经存在的配置项,而且具有更高的优先级,会覆盖
core.json
中的默认值。
配置中
job.content.reader.parameter
的value部分会传给
Reader.Job
;
job.content.writer.parameter
Writer.Job
Reader.Job
Writer.Job
可以通过
super.getPluginJobConf()
来获取。
DataX
框架支持对特定的配置项进行RSA加密,例子中以
*
开头的项目便是加密后的值。 配置项加密解密过程对插件是透明,插件仍然以不带
*
的key来查询配置和操作配置项 。
如何设计配置参数
配置文件的设计是插件开发的第一步!
任务配置中
reader
writer
下
parameter
部分是插件的配置参数,插件的配置参数应当遵循以下原则:
- 驼峰命名:所有配置项采用驼峰命名法,首字母小写,单词首字母大写。
- 正交原则:配置项必须正交,功能没有重复,没有潜规则。
- 富类型:合理使用json的类型,减少无谓的处理逻辑,减少出错的可能。
- 使用正确的数据类型。比如,bool类型的值使用
true
false
"yes"
"true"
- 合理使用集合类型,比如,用数组替代有分隔符的字符串。
- 使用正确的数据类型。比如,bool类型的值使用
- 类似通用:遵守同一类型的插件的习惯,比如关系型数据库的
connection
{
"connection": [
{
"table": [
"table_1",
"table_2"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/database_1",
"jdbc:mysql://127.0.0.2:3306/database_1_slave"
]
},
{
"table": [
"table_3",
"table_4"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.3:3306/database_2",
"jdbc:mysql://127.0.0.4:3306/database_2_slave"
]
}
]
} 插件数据传输
跟一般的
生产者-消费者
模式一样,
Reader
插件和
Writer
插件之间也是通过
channel
来实现数据的传输的。
channel
可以是内存的,也可能是持久化的,插件不必关心。插件通过
RecordSender
往
channel
写入数据,通过
RecordReceiver
从
channel
读取数据。
channel
中的一条数据为一个
Record
的对象,
Record
中可以放多个
Column
对象,这可以简单理解为数据库中的记录和列。
Record
有如下方法:
public interface Record {
// 加入一个列,放在最后的位置
void addColumn(Column column);
// 在指定下标处放置一个列
void setColumn(int i, final Column column);
// 获取一个列
Column getColumn(int i);
// 转换为json String
String toString();
// 获取总列数
int getColumnNumber();
// 计算整条记录在内存中占用的字节数
int getByteSize();
} 因为
Record
是一个接口,
Reader
插件首先调用
RecordSender.createRecord()
创建一个
Record
实例,然后把
Column
一个个添加到
Record
Writer
插件调用
RecordReceiver.getFromReader()
方法获取
Record
,然后把
Column
遍历出来,写入目标存储中。当
Reader
尚未退出,传输还在进行时,如果暂时没有数据
RecordReceiver.getFromReader()
方法会阻塞直到有数据。如果传输已经结束,会返回
null
Writer
插件可以据此判断是否结束
startWrite
方法。
Column
的构造和操作,我们在《类型转换》一节介绍。
类型转换
为了规范源端和目的端类型转换操作,保证数据不失真,DataX支持六种内部数据类型:
-
Long
-
Double
-
String
-
Date
-
Bool
-
Bytes
对应地,有
DateColumn
LongColumn
DoubleColumn
BytesColumn
StringColumn
BoolColumn
六种
Column
的实现。
Column
除了提供数据相关的方法外,还提供一系列以
as
开头的数据类型转换转换方法。
DataX的内部类型在实现上会选用不同的java类型:
| 内部类型 | 实现类型 | 备注 |
|---|---|---|
| Date | java.util.Date | |
| Long | java.math.BigInteger | 使用无限精度的大整数,保证不失真 |
| Double | java.lang.String | 用String表示,保证不失真 |
| Bytes | byte[] | |
| String | ||
| Bool | java.lang.Boolean |
类型之间相互转换的关系如下:
| from\to | ||||||
|---|---|---|---|---|---|---|
| - | 使用毫秒时间戳 | 不支持 | 使用系统配置的date/time/datetime格式转换 | |||
| 作为毫秒时间戳构造Date | BigInteger转为BigDecimal,然后BigDecimal.doubleValue() | BigInteger.toString() | 0为false,否则true | |||
| 内部String构造BigDecimal,然后BigDecimal.longValue() | 直接返回内部String | |||||
按照 | ||||||
| 按照配置的date/time/datetime/extra格式解析 | 用String构造BigDecimal,然后取longValue() | 用String构造BigDecimal,然后取doubleValue(),会正确处理 | | "true"为 | ||
| |
加载原理
- 框架扫描
plugin/reader
plugin/writer
plugin.json
- 以
plugin.json
name
- 用户在插件中在
reader
writer
name
reader
writer
classpath
- 根据插件配置中定义的入口类,框架通过反射实例化对应的
Job
Task