XGBoost(eXtreme Gradient Boosting) 是基于 GB(Gradient Boosting)模型框架实现的一个高效,便捷,可扩展的一个机器学习库。该库先由陈天奇在 2014 年完成 v0.1 版本之后开源到 github[1]上,当前最新版本是 v0.6。目前在各类相关竞赛中都可以看到其出现的身影,如 kaggle[2],在 2015 年 29 个竞赛中,top3 队伍发表的解决方案中有 17 个方案使用了 XGBoost,而只有 11 个解决方案使用了深度学习;同时在 2015KDDCup 中 top10 队伍都使用了 XGBoost[3]。由于其与 GBDT(Gradient Boosting decision Tree)存在一定相似之处,网上也经常会有人将 GBDT 和 XGBoost 做个对比 [4]。最近正好读了陈天奇的论文《XGBoost: A Scalable Tree Boosting System》[3], 从论文中可以看出 XGBoost 新颖之处在于:
1、使用了正则化的目标函数,其加入的惩罚项会控制模型复杂度(叶子个数) 和叶子结点的得分权重
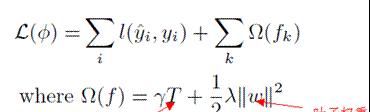
图 1-1 目标函数
2、使用 Shrinkage,通过一个因子η缩减每次最新生成树的权重,其目的是为了降低已生成的树对后续树的影响。
3、支持列(特征) 采样,该方式曾被用于随机森林。可以预防过拟合且加快模型训练速度。
4、并行计算。Boost 方式树是串行生成的,所以其在寻找树分裂点时候进行并行计算,加快模型训练速度。
在寻找分裂点时候论文中也提到多种方式:
1、基本枚举贪婪搜索算法。该方式将特征按其值排序之后,枚举每个特征值作为其分裂点并计算该分裂点的增益,然后选择最大增益的分裂点
2、近似贪婪搜索算法。该方式在寻找分裂点前会将所有的特征按其对应值进行排序后选择其百分位的点作为候选集合,在执行基本穷举贪婪搜索法。
3、加权分位数法(weighted quantile sketch)。该方法可以用于对加权数据的处理。
4、稀疏分裂点查找。可以加快模型对稀疏数据处理。
其与 GBDT 不同之一在于其对目标函数进行二阶泰勒展开,使用了二阶导数加快了模型收敛速度。总的来说 XGBoost 受到欢迎最重要的一个因素在于其快速的训练过程。
Linux 上的源码下载和编译过程如下 [5]:
使用--recursive 命令是因为 XGBoost 使用了作者自己编写的分布式计算库,通过这个命令可以下载对应的库,编译好之后就可以开始阅读源码了,XGBoost 主要代码目录结构如下:
程序的执行入口在 cli_main.cc 文件中
在 main 函数中只调用了 CLIRunTask() 函数,在该函数中可以看出,程序通过函数 configure() 解析配置文件后,根据参数 task 选择对应的执行函数。我们这里主要看下训练函数 CLITrain();
在 CLI 函数中, 先是将训练数据加载到内存中,然后开始创建 Learner 类实例, 接着调用 Learner 的 configure 函数配置参数,调用 InitModel() 初始化模型。然后就开始 XGboost 的 Boosting 训练,主要调用的是 Learner 的 UpdateOneIter() 函数。
在每次迭代过程中,LazyInitDMatrix() 先初始化需要用到的数据结构。GetGradient() 获取目标函数的一阶导和二阶导,最后 DoBoost() 执行 Boost 操作生成一棵回归树。Class GradientBoost 是一个抽象类,他定义了 Gradient Boost 的抽象接口。其派生出的两个类 Class GBTree 和 Class GBLinear 分别对应着配置文件里面的参数"gbtree"和"gblinear", Class GBTree 主要使用的回归树作为其弱分类器,而 Class GBLinear 使用的是线性回归或逻辑回归作为其弱分类器。
Class GBTree 用的比较多,其 DoBoost() 函数执行的操作如下:
DoBoost() 调用了 BoostNewTrees() 函数。在 BoostNewTrees() 中先初始化了 TreeUpdater 实例,在调用其 Update 函数生成一棵回归树。TreeUpdater 是一个抽象类,根据使用算法不同其派生出许多不同的 Updater,这些 Updater 都在 src/tree 目录下。
文件 updater_basemaker-inl.h 中定义了一个派生自 TreeUpdater 的类 BaseMaker。Class ColMaker 使用的是基本枚举贪婪搜索算法,通过枚举所有的特征来寻找最佳分裂点;Class SkMaker 派生自 BaseMaker,使用近似的 sketch 方法寻找最佳分裂点;Class TreeRefresher 用于刷新数据集上树的统计信息和叶子值;Class TreePruner 是树的剪枝操作;Class HistMaker 使用的是直方图法,该方法在论文中并没有提到,所以也不是很清楚。
至此便可以大致了解 XGBoost 源码的逻辑结构,目前源码只看到这里。等看了各算法的具体实现之后再在后续文章中写其具体实现细节。
[1].https://github.com/dmlc/xgboost
[2].https://www.kaggle.com
[3].Tianqi Chen and Carlos Guestrin. XGBoost: A Scalable Tree Boosting System. In 22nd SIGKDD Conference on Knowledge Discovery and Data Mining, 2016
[4].https://www.zhihu.com/question/41354392
[5].http://xgboost.readthedocs.io/en/latest/build.html