XGBoost(eXtreme Gradient Boosting) 是基于 GB(Gradient Boosting)模型架構實作的一個高效,便捷,可擴充的一個機器學習庫。該庫先由陳天奇在 2014 年完成 v0.1 版本之後開源到 github[1]上,目前最新版本是 v0.6。目前在各類相關競賽中都可以看到其出現的身影,如 kaggle[2],在 2015 年 29 個競賽中,top3 隊伍發表的解決方案中有 17 個方案使用了 XGBoost,而隻有 11 個解決方案使用了深度學習;同時在 2015KDDCup 中 top10 隊伍都使用了 XGBoost[3]。由于其與 GBDT(Gradient Boosting decision Tree)存在一定相似之處,網上也經常會有人将 GBDT 和 XGBoost 做個對比 [4]。最近正好讀了陳天奇的論文《XGBoost: A Scalable Tree Boosting System》[3], 從論文中可以看出 XGBoost 新穎之處在于:
1、使用了正則化的目标函數,其加入的懲罰項會控制模型複雜度(葉子個數) 和葉子結點的得分權重
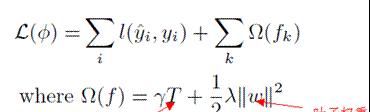
圖 1-1 目标函數
2、使用 Shrinkage,通過一個因子η縮減每次最新生成樹的權重,其目的是為了降低已生成的樹對後續樹的影響。
3、支援列(特征) 采樣,該方式曾被用于随機森林。可以預防過拟合且加快模型訓練速度。
4、并行計算。Boost 方式樹是串行生成的,是以其在尋找樹分裂點時候進行并行計算,加快模型訓練速度。
在尋找分裂點時候論文中也提到多種方式:
1、基本枚舉貪婪搜尋算法。該方式将特征按其值排序之後,枚舉每個特征值作為其分裂點并計算該分裂點的增益,然後選擇最大增益的分裂點
2、近似貪婪搜尋算法。該方式在尋找分裂點前會将所有的特征按其對應值進行排序後選擇其百分位的點作為候選集合,在執行基本窮舉貪婪搜尋法。
3、權重分位數法(weighted quantile sketch)。該方法可以用于對權重資料的處理。
4、稀疏分裂點查找。可以加快模型對稀疏資料處理。
其與 GBDT 不同之一在于其對目标函數進行二階泰勒展開,使用了二階導數加快了模型收斂速度。總的來說 XGBoost 受到歡迎最重要的一個因素在于其快速的訓練過程。
Linux 上的源碼下載下傳和編譯過程如下 [5]:
使用--recursive 指令是因為 XGBoost 使用了作者自己編寫的分布式計算庫,通過這個指令可以下載下傳對應的庫,編譯好之後就可以開始閱讀源碼了,XGBoost 主要代碼目錄結構如下:
程式的執行入口在 cli_main.cc 檔案中
在 main 函數中隻調用了 CLIRunTask() 函數,在該函數中可以看出,程式通過函數 configure() 解析配置檔案後,根據參數 task 選擇對應的執行函數。我們這裡主要看下訓練函數 CLITrain();
在 CLI 函數中, 先是将訓練資料加載到記憶體中,然後開始建立 Learner 類執行個體, 接着調用 Learner 的 configure 函數配置參數,調用 InitModel() 初始化模型。然後就開始 XGboost 的 Boosting 訓練,主要調用的是 Learner 的 UpdateOneIter() 函數。
在每次疊代過程中,LazyInitDMatrix() 先初始化需要用到的資料結構。GetGradient() 擷取目标函數的一階導和二階導,最後 DoBoost() 執行 Boost 操作生成一棵回歸樹。Class GradientBoost 是一個抽象類,他定義了 Gradient Boost 的抽象接口。其派生出的兩個類 Class GBTree 和 Class GBLinear 分别對應着配置檔案裡面的參數"gbtree"和"gblinear", Class GBTree 主要使用的回歸樹作為其弱分類器,而 Class GBLinear 使用的是線性回歸或邏輯回歸作為其弱分類器。
Class GBTree 用的比較多,其 DoBoost() 函數執行的操作如下:
DoBoost() 調用了 BoostNewTrees() 函數。在 BoostNewTrees() 中先初始化了 TreeUpdater 執行個體,在調用其 Update 函數生成一棵回歸樹。TreeUpdater 是一個抽象類,根據使用算法不同其派生出許多不同的 Updater,這些 Updater 都在 src/tree 目錄下。
檔案 updater_basemaker-inl.h 中定義了一個派生自 TreeUpdater 的類 BaseMaker。Class ColMaker 使用的是基本枚舉貪婪搜尋算法,通過枚舉所有的特征來尋找最佳分裂點;Class SkMaker 派生自 BaseMaker,使用近似的 sketch 方法尋找最佳分裂點;Class TreeRefresher 用于重新整理資料集上樹的統計資訊和葉子值;Class TreePruner 是樹的剪枝操作;Class HistMaker 使用的是直方圖法,該方法在論文中并沒有提到,是以也不是很清楚。
至此便可以大緻了解 XGBoost 源碼的邏輯結構,目前源碼隻看到這裡。等看了各算法的具體實作之後再在後續文章中寫其具體實作細節。
[1].https://github.com/dmlc/xgboost
[2].https://www.kaggle.com
[3].Tianqi Chen and Carlos Guestrin. XGBoost: A Scalable Tree Boosting System. In 22nd SIGKDD Conference on Knowledge Discovery and Data Mining, 2016
[4].https://www.zhihu.com/question/41354392
[5].http://xgboost.readthedocs.io/en/latest/build.html