在多线程环境下,使用<code>HashMap</code>进行<code>put</code>操作时存在丢失数据的情况,为了避免这种bug的隐患,强烈建议使用<code>ConcurrentHashMap</code>代替<code>HashMap。</code>
HashTable是一个线程安全的类,它使用synchronized来锁住整张Hash表来实现线程安全,即每次锁住整张表让线程独占,相当于所有线程进行读写时都去竞争一把锁,导致效率非常低下。ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的Hashtable,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
ConcurrentHashMap 为了提高本身的并发能力,在内部采用了一个叫做 Segment 的结构,一个 Segment 其实就是一个类 Hash Table 的结构,Segment 内部维护了一个链表数组,我们用下面这一幅图来看下 ConcurrentHashMap 的内部结构,从下面的结构我们可以了解到,ConcurrentHashMap 定位一个元素的过程需要进行两次Hash操作,第一次 Hash 定位到 Segment,第二次 Hash 定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是 Hash 的过程要比普通的 HashMap 要长,但是带来的好处是写操作的时候可以只对元素所在的 Segment 进行操作即可,不会影响到其他的 Segment,这样,在最理想的情况下,ConcurrentHashMap 可以最高同时支持 Segment 数量大小的写操作(刚好这些写操作都非常平均地分布在所有的 Segment上),所以,通过这一种结构,ConcurrentHashMap 的并发能力可以大大的提高。我们用下面这一幅图来看下ConcurrentHashMap的内部结构详情图,如下:
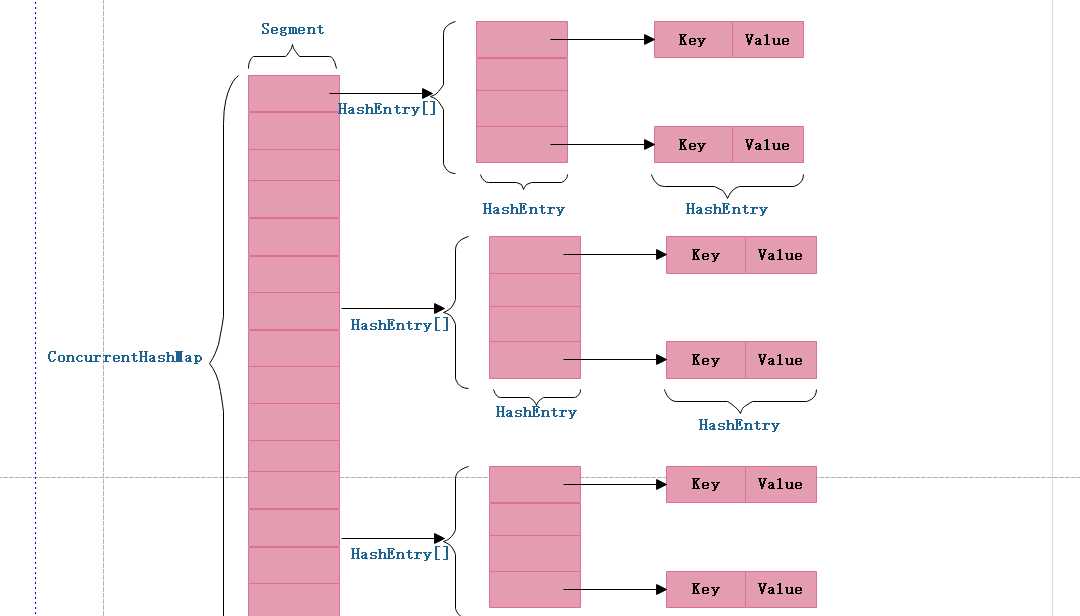
不难看出,ConcurrentHashMap采用了二次hash的方式,第一次hash将key映射到对应的segment,而第二次hash则是映射到segment的不同桶(bucket)中。
为什么要用二次hash,主要原因是为了构造分离锁,使得对于map的修改不会锁住整个容器,提高并发能力。当然,没有一种东西是绝对完美的,二次hash带来的问题是整个hash的过程比hashmap单次hash要长,所以,如果不是并发情形,不要使用concurrentHashmap。
底层采用分段的数组+链表实现,线程安全
通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
![网络编程----TCP实现聊天室项目前言[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)