在多線程環境下,使用<code>HashMap</code>進行<code>put</code>操作時存在丢失資料的情況,為了避免這種bug的隐患,強烈建議使用<code>ConcurrentHashMap</code>代替<code>HashMap。</code>
HashTable是一個線程安全的類,它使用synchronized來鎖住整張Hash表來實作線程安全,即每次鎖住整張表讓線程獨占,相當于所有線程進行讀寫時都去競争一把鎖,導緻效率非常低下。ConcurrentHashMap可以做到讀取資料不加鎖,并且其内部的結構可以讓其在進行寫操作的時候能夠将鎖的粒度保持地盡量地小,允許多個修改操作并發進行,其關鍵在于使用了鎖分離技術。它使用了多個鎖來控制對hash表的不同部分進行的修改。ConcurrentHashMap内部使用段(Segment)來表示這些不同的部分,每個段其實就是一個小的Hashtable,它們有自己的鎖。隻要多個修改操作發生在不同的段上,它們就可以并發進行。
ConcurrentHashMap 為了提高本身的并發能力,在内部采用了一個叫做 Segment 的結構,一個 Segment 其實就是一個類 Hash Table 的結構,Segment 内部維護了一個連結清單數組,我們用下面這一幅圖來看下 ConcurrentHashMap 的内部結構,從下面的結構我們可以了解到,ConcurrentHashMap 定位一個元素的過程需要進行兩次Hash操作,第一次 Hash 定位到 Segment,第二次 Hash 定位到元素所在的連結清單的頭部,是以,這一種結構的帶來的副作用是 Hash 的過程要比普通的 HashMap 要長,但是帶來的好處是寫操作的時候可以隻對元素所在的 Segment 進行操作即可,不會影響到其他的 Segment,這樣,在最理想的情況下,ConcurrentHashMap 可以最高同時支援 Segment 數量大小的寫操作(剛好這些寫操作都非常平均地分布在所有的 Segment上),是以,通過這一種結構,ConcurrentHashMap 的并發能力可以大大的提高。我們用下面這一幅圖來看下ConcurrentHashMap的内部結構詳情圖,如下:
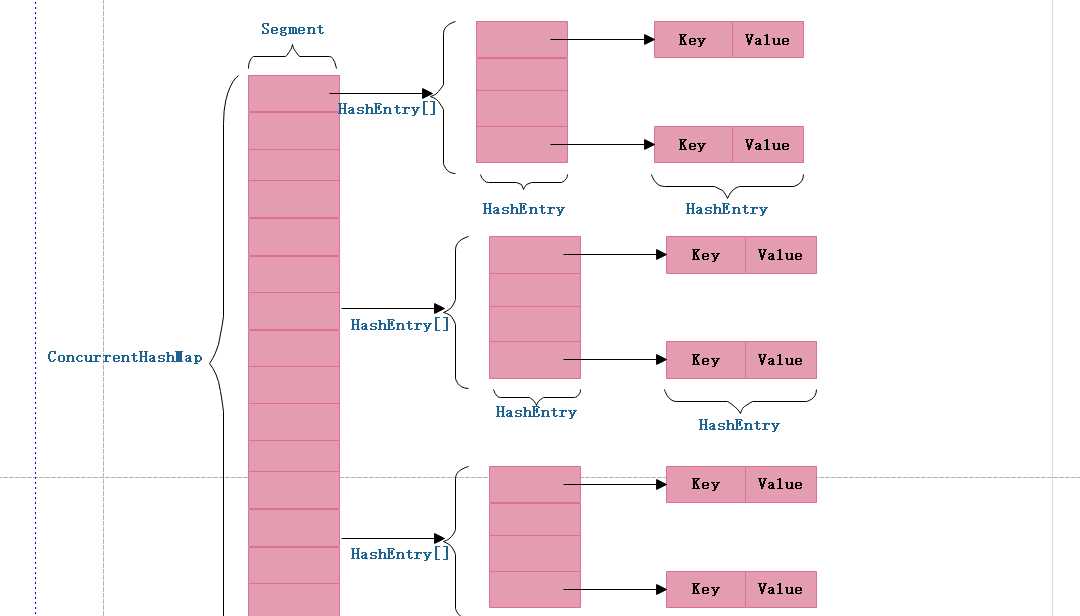
不難看出,ConcurrentHashMap采用了二次hash的方式,第一次hash将key映射到對應的segment,而第二次hash則是映射到segment的不同桶(bucket)中。
為什麼要用二次hash,主要原因是為了構造分離鎖,使得對于map的修改不會鎖住整個容器,提高并發能力。當然,沒有一種東西是絕對完美的,二次hash帶來的問題是整個hash的過程比hashmap單次hash要長,是以,如果不是并發情形,不要使用concurrentHashmap。
底層采用分段的數組+連結清單實作,線程安全
通過把整個Map分為N個Segment,可以提供相同的線程安全,但是效率提升N倍,預設提升16倍。(讀操作不加鎖,由于HashEntry的value變量是 volatile的,也能保證讀取到最新的值。)
Hashtable的synchronized是針對整張Hash表的,即每次鎖住整張表讓線程獨占,ConcurrentHashMap允許多個修改操作并發進行,其關鍵在于使用了鎖分離技術
有些方法需要跨段,比如size()和containsValue(),它們可能需要鎖定整個表而而不僅僅是某個段,這需要按順序鎖定所有段,操作完畢後,又按順序釋放所有段的鎖
擴容:段内擴容(段内元素超過該段對應Entry數組長度的75%觸發擴容,不會對整個Map進行擴容),插入前檢測需不需要擴容,有效避免無效擴容
![網絡程式設計----TCP實作聊天室項目前言[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)