在DC学院上买了个数据分析的课程,OK!说干就干,记录下学习的笔记,希望能有所收获( ̄︶ ̄)↗
开放数据集
网站爬虫
科研数据共享
数据算法竞赛:DC学院,天池,kaggle
政府公司分享
个人分享
这个没什么好说的,科学上网,国外网站多的是!
建立网站连接
爬取网页/API
分析返回结果
抽取所需信息
爬虫分两大类:
基于网站API的爬取:一般返回格式是JSON,这个和阿里云API返回的格式是一样的
基于网页的爬取:这个就比较难了,用过API的都明白(/▽\)
OK,刚学习了简单的网站API的爬取,下面实践一下!
我们可以访问请求的url来获取想要的信息
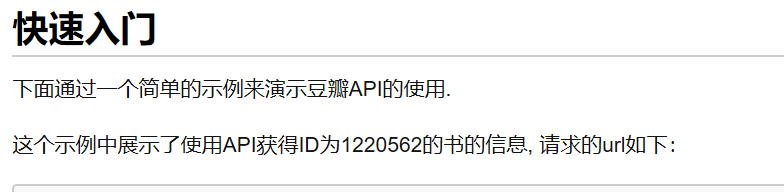
但这样显然太麻烦了,我们也可以通过python的urllib包来解决问题

返回的格式是JSON
JSON 指的是 JavaScript 对象表示法(JavaScript Object Notation)
JSON 是轻量级的文本数据交换格式
JSON 独立于语言 ,JSON 使用 JavaScript 语法来描述数据对象,但是 JSON 仍然独立于语言和平台。JSON 解析器和 JSON 库支持许多不同的编程语言。
JSON 具有自我描述性,更易理解
数据在名称/值对中(如:"Day" : "Sunday"),数据由逗号,分隔花括号保存对象,方括号保存数组
然后我们用python解析JSON,假设我们要获取的是上文(如图)“rating”中“average"键所对应的值
来和浏览网站的时候所看到的对比一下
如果需要将获得的数据存到本地,同样可以用python轻松解决
在本地看一下
获取多部电影
这样是不是还不够便捷?
能不能输入一些电影名字,然后直接返回我们需要的信息,如评分呢?
OK,还是用到API,不过这里用到了”电影搜索“的API:
很OK!
下面看代码!
今天数据分析就学习了这么多,OK!希望能有所收获( ̄︶ ̄)↗