在DC學院上買了個資料分析的課程,OK!說幹就幹,記錄下學習的筆記,希望能有所收獲( ̄︶ ̄)↗
開放資料集
網站爬蟲
科研資料共享
資料算法競賽:DC學院,天池,kaggle
政府公司分享
個人分享
這個沒什麼好說的,科學上網,國外網站多的是!
建立網站連接配接
爬取網頁/API
分析傳回結果
抽取所需資訊
爬蟲分兩大類:
基于網站API的爬取:一般傳回格式是JSON,這個和阿裡雲API傳回的格式是一樣的
基于網頁的爬取:這個就比較難了,用過API的都明白(/▽\)
OK,剛學習了簡單的網站API的爬取,下面實踐一下!
我們可以通路請求的url來擷取想要的資訊
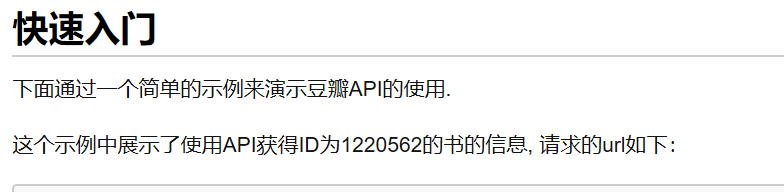
但這樣顯然太麻煩了,我們也可以通過python的urllib包來解決問題

傳回的格式是JSON
JSON 指的是 JavaScript 對象表示法(JavaScript Object Notation)
JSON 是輕量級的文本資料交換格式
JSON 獨立于語言 ,JSON 使用 JavaScript 文法來描述資料對象,但是 JSON 仍然獨立于語言和平台。JSON 解析器和 JSON 庫支援許多不同的程式設計語言。
JSON 具有自我描述性,更易了解
資料在名稱/值對中(如:"Day" : "Sunday"),資料由逗号,分隔花括号儲存對象,方括号儲存數組
然後我們用python解析JSON,假設我們要擷取的是上文(如圖)“rating”中“average"鍵所對應的值
來和浏覽網站的時候所看到的對比一下
如果需要将獲得的資料存到本地,同樣可以用python輕松解決
在本地看一下
擷取多部電影
這樣是不是還不夠便捷?
能不能輸入一些電影名字,然後直接傳回我們需要的資訊,如評分呢?
OK,還是用到API,不過這裡用到了”電影搜尋“的API:
很OK!
下面看代碼!
今天資料分析就學習了這麼多,OK!希望能有所收獲( ̄︶ ̄)↗