Author | Walid Amamou
Translated by | Hirakawa
Planning | Ling Min
This article was originally published at Towards Data Science.
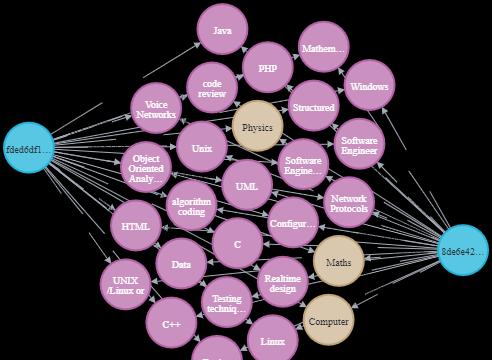
Image courtesy of the author: Knowledge Graph in Neo4j
Introduction
In this article, I'll show how to create a knowledge graph based on job descriptions using an optimized, converter-based named entity recognition (NER) and spaCy relational extraction model. The methods presented here can be applied to any other field, such as biomedicine, finance, healthcare, etc.
Here are the steps we're going to take:
Load the optimized converter NER and spaCy relationship extraction model in Google Colab;
Create a Neo4j Sandbox and add entities and relationships;
Query the graph to find the positions that match your target resume the most, find the three most popular skills and the ones with the highest co-occurrence rates.
To learn more about how to use UBIAI to generate training data and optimize NER and relational extraction models, check out the following articles.
UBIAI: Easy-to-use NLP application text annotations
How to use the BERT converter to train a federated entity and relationship extract classifier with spaCy3
How to optimize the BERT converter using spaCy3
The job description dataset is available from Kaggle.
At the end of this article, we can create a knowledge graph like the one shown below.

Image courtesy of the author: Knowledge Graph of Job Description
Named entities and relationship extraction
First, we load the dependencies of the NER and the relational model, as well as the previously optimized NER model itself, to extract skills, qualifications, specializations, and years of service:
Load the job dataset from which we want to extract entities and relationships:
To extract entities from a job collection:
Before we feed an entity to a relational extraction model, we can look at some of the extracted entities:
We are now ready to predict relationships; first load the relationship extraction model, be sure to change the directory to rel_component/scripts so that you can access all the necessary scripts for the relationship model.
Neo4J
Now we can load the job dataset and extract it into the Neo4j database.
First, we create an empty Neo4j Sandbox and add the connection information as follows:
Next, we add documents, entities, and relationships to the knowledge graph. Note that we need to extract the integer age from the name of the entity EXPERIENCE and store it as a property.
Now let's get into the fun part. We can start the knowledge graph and run the query. Let's run a query to find out which position best matches your target resume:
Public entities in the results displayed in tabular form:
Diagrams displayed in visual form:
Image courtesy of the author: Based on Best Match positions
Although this dataset has only 29 job descriptions, the approach presented here can be applied to large-scale datasets with thousands of jobs. With just a few lines of code, we can instantly extract the work that matches the most of our target resume.
Let's find out the skills we need the most:
And skills that require a maximum number of years of service:
Web development and technical support require the highest number of years of work, followed by security settings.
Finally, let's look up the skill pairs with the highest co-occurrence rate:
Summary
In this article, we describe how to extract models using converter-based NER and spaCy relationships to create knowledge graphs with Neo4j. In addition to information extraction, the topology of the graph can also be used as input to other machine learning models.
Combining NLP with the graph database Neo4j can accelerate information discovery in many fields, with more significant effects in medical and biomedical applications.
https://medium.com/m/global-identity?