作者 | Walid Amamou
譯者 | 平川
策劃 | 淩敏
本文最初釋出于 Towards Data Science。
圖檔由作者提供:Neo4j中的知識圖譜
簡 介
在這篇文章中,我将展示如何使用經過優化的、基于轉換器的命名實體識别(NER)以及 spaCy 的關系提取模型,基于職位描述建立一個知識圖譜。這裡介紹的方法可以應用于其他任何領域,如生物醫學、金融、醫療保健等。
以下是我們要采取的步驟:
在 Google Colab 中加載優化後的轉換器 NER 和 spaCy 關系提取模型;
建立一個 Neo4j Sandbox,并添加實體和關系;
查詢圖,找出與目标履歷比對度最高的職位,找出三個最受歡迎的技能和共現率最高的技能。
要了解關于如何使用 UBIAI 生成訓練資料以及優化 NER 和關系提取模型的更多資訊,請檢視以下文章。
UBIAI:簡單易用的 NLP 應用程式文本标注
如何使用 BERT 轉換器與 spaCy3 訓練一個聯合實體和關系提取分類器
如何使用 spaCy3 優化 BERT 轉換器
職位描述資料集可以從 Kaggle 擷取。
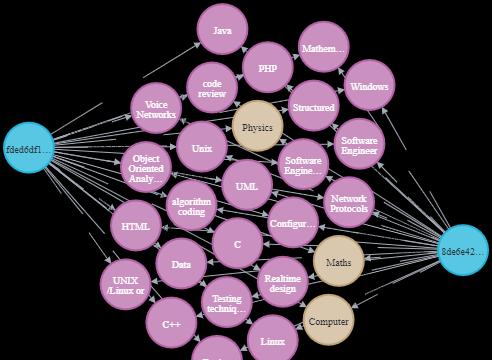
在本文結束的時候,我們就可以建立出如下所示的知識圖譜。

圖檔由作者提供:職位描述的知識圖譜
命名實體和關系提取
首先,我們加載 NER 和關系模型的依賴關系,以及之前優化過的 NER 模型本身,以提取技能、學曆、專業和工作年限:
加載我們想從中提取實體和關系的職位資料集:
從職位資料集中提取實體:
在将實體提供給關系提取模型之前,我們可以看下提取出的部分實體:
我們現在準備好預測關系了;首先加載關系提取模型,務必将目錄改為 rel_component/scripts 以便可以通路關系模型的所有必要腳本。
Neo4J
現在,我們可以加載職位資料集,并将資料提取到 Neo4j 資料庫中了。
首先,我們建立一個空的 Neo4j Sandbox,并添加連接配接資訊,如下所示:
接下來,我們将文檔、實體和關系添加到知識圖譜中。注意,我們需要從實體 EXPERIENCE 的 name 中提取出整數年限,并将其作為一個屬性存儲起來。
現在開始進入有趣的部分了。我們可以啟動知識圖譜并運作查詢了。讓我們運作一個查詢,找出與目标履歷最比對的職位:
以表格形式顯示的結果中的公共實體:
以可視化形式顯示的圖:
圖檔由作者提供:基于最佳比對職位
雖然這個資料集隻有 29 個職位描述,但這裡介紹的方法可以應用于有成千上萬個職位的大規模資料集。隻需幾行代碼,我們立馬就可以提取出與目标履歷比對度最高的工作。
下面,讓我們找出最需要的技能:
以及需要最高工作年限的技能:
Web 開發和技術支援需要的工作年限最高,然後是安全設定。
最後,讓我們查下共現率最高的技能對:
小 結
在這篇文章中,我們描述了如何利用基于轉換器的 NER 和 spaCy 的關系提取模型,用 Neo4j 建立知識圖譜。除了資訊提取之外,圖的拓撲結構還可以作為其他機器學習模型的輸入。
将 NLP 與圖資料庫 Neo4j 相結合,可以加速許多領域的資訊發現,相比之下,在醫療和生物醫學領域的應用效果更為顯著。
https://medium.com/m/global-identity?