Zhi DongXi (public number: zhidxcom)
Author | ZeR0
Edit | Desert Shadow
Zhidong reported on January 4 that last Thursday (December 30), at the Beijing Zhiyuan Artificial Intelligence Research Institute Natural Language Processing Major Research Direction Frontier Technology Open Day, the Beijing Zhiyuan Artificial Intelligence Research Institute (hereinafter referred to as the "Zhiyuan Research Institute") released a new solution for the "proposition" of the big model evaluation - the Zhiyuan Index.
NLP is one of the major academic research directions of Zhiyuan, with Professor Sun Maosong of Tsinghua University as the chief scientist in this direction, Professor Yang Erhong of Beijing Language and Culture University as the project manager, scholars including Li Juanzi, Sui Zhifang, Liu Yang, Wan Xiaojun, He Xiaodong, and young scientists including Liu Zhiyuan, Han Xianpei, Sun Xu, Yan Rui, Zhang Jiajun, Zhao Xin, Yang Zhilin, Li Jiwei, etc.
In addition to the release of the Wisdom Source Index, during this technology open day, 24 natural language processing (NLP) academic experts, more than 20 cutting-edge reports, and more than 10 latest research results were "grouped" to appear.
I. Zhiyuan Index CUBE: Multi-level and multi-dimensional evaluation scheme for large models
According to Liu Zhiyuan, associate professor of Tsinghua University, young scientist of Zhiyuan and backbone member of Zhiyuan Index Construction, CUI (full name of Chinese Language Enderstanding and Generation Evaluation) is a comprehensive and balanced machine Chinese language ability evaluation benchmark, and has established a multi-level and multi-dimensional evaluation scheme on the basis of a comprehensive and systematic evaluation system.
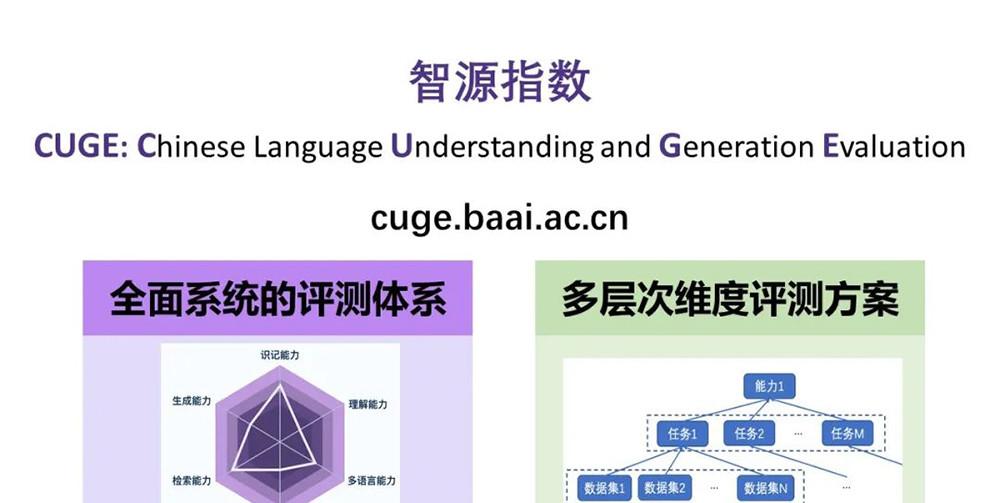
CUGE website link: cuge.baai.ac.cn
Technical report link: arxiv.org/pdf/2112.13610.pdf
Code link: github.com/TsinghuaAI/CUGE
In terms of benchmark framework, different from the traditional way of flattening commonly used data sets, the Wisdom Source Index selects and organizes data sets according to the human language examination syllabus and the current status of NLP research, with a hierarchical framework of language proficiency-task-datasets, covering 7 important language abilities, 17 mainstream NLP tasks and 19 representative data sets, comprehensively balanced, and avoiding "partial selection".

▲Source Index CUBE framework
In terms of scoring strategy, with reference to the advantages and disadvantages of existing evaluation schemes, Zhiyuan Index has built a multi-level evaluation scheme, which can better show the differences in model language intelligence in different dimensions of the model: relying on the hierarchical benchmark framework of capability-task-dataset, providing model performance scores at different levels, the systematization is greatly strengthened.
The Zhiyuan Index will provide a performance ranking of the participant model, which fully absorbs the characteristics of relevant evaluation benchmarks at home and abroad and builds a corresponding feature.
First, the leaderboard is based on the capability-task-dataset system, which will give the corresponding labels to each data set, so that participants can filter out the abilities or angles of interest and evaluate them accordingly.
Second, based on the label system, participants are supported to customize the ranking list through label screening. At the same time, the official will also provide a number of representative recommendation packages, such as the condensed list, etc., to make it easier for participants to use their platform to carry out targeted ability assessments.
Third, the radar chart is presented according to the 7 important language abilities, which intuitively reflects the effect of different models on different capabilities.
Fourth, the platform will also support the ranking and evaluation of single data sets, which is more conducive to participants to track the progress and dynamics of data set research. In other words, any single dataset can see a list of related evaluation effects.
"We hope to build the Zhiyuan Index from an academic perspective, so that it returns to our original intention of constructing this kind of evaluation benchmark, not into the behavior of brushing the list." Liu Zhiyuan believes that optimizing specifically for the list does not mean that the big model gets a good effect in the application scenario, this behavior is meaningless, but it will waste a very large amount of computing power and time.
The Wisdom Source Index will regularly incorporate new excellent data sets into the calculation of the Wisdom Source Index every year, and all submitters must fill in the Honor Code and display, without manual intervention in the data pre-training and testing process. In the future, Zhiyuan also plans to rely on the strength of Zhiyuan Research Institute and Zhiyuan community to provide users with feedback and discussion mechanisms for data sets and evaluation results, and build a mechanism for Chinese high-quality data set communities through interactive communication to promote the development of natural language processing in Chinese.
In order to better support the development of the Zhiyuan Index, the Zhiyuan Research Institute set up the "Zhiyuan Index Working Committee", with Sun Maosong as the director and Sui Zhifang and Yang Erhong as the deputy directors. At present, the committee unit has absorbed more than 10 advantageous units in natural language processing in China, and close to 20 relevant advantageous research groups to continuously improve the wisdom source index, and strive to promote the standard evaluation of natural language processing technology Chinese more scientifically, standardized and high-quality.
In this regard, Dai Qionghai, professor of Tsinghua University and chairman of the Chinese Engineering Intelligence Society, commented: "Congratulations to Professor Sun Maosong for leading Zhiyuan NLP scholars to jointly establish the zhiyuan index of machine Chinese language ability evaluation benchmark, which is of important milestone significance for the development of Chinese information processing and even artificial intelligence in China." ”
2. Sui Zhifang: Problems and countermeasures in NLP evaluation
In the zhiyuan scholars achievement report session, Professor Sui Zhifang of Peking University shared the problems and countermeasures in the NLP evaluation.
He talked about the problems in NLP evaluation involving the specification, efficiency, indicators, period, data set and tasks of the evaluation.
First, reviews lack certain normativity. As a result, the entry threshold for evaluation is very low, the number of evaluations is too large and the quality is uneven, and researchers often use the most favorable data set for their models and claim to achieve the best results, which makes it difficult for follow-up researchers to objectively compare and surpass, making it difficult for the public to grasp the real level of research in the current field.
Second, evaluate the decline in efficiency. Faced with an increasingly large number of parameters, most of the existing evaluation tasks can no longer clearly distinguish between human level and machine performance. Most reviews lose their effectiveness in a short period of time, which is called a decline in the effectiveness of reviews.
Third, the evaluation lifecycle is very short. Soon after some of the datasets were proposed, the best machine models scored above the human benchmark. The evaluation system loses its effectiveness too quickly and lacks vitality.
Whether NLP evaluates language proficiency or language performance is a profound question. The short cycle and the decline in potency are only a manifestation of language, how to really evaluate the language ability of the machine, we need to evaluate the language ability of the machine, not just a temporary presentation of behavior at the surface.
Another issue is the generic NLP review. Can the general NLP evaluation completely, comprehensively, and systematically examine the comprehensive ability of machine understanding and language processing? What we see is a comprehensive summary, comprehensive evaluation may not be synthesis, just simple data aggregation, the lack of organic correlation between the tasks, the tasks are not really combined into a system, the lack of a systematic system.
The evaluation technology is single, why can the machine model reach a relatively high level in the short term? Part of the reason is because of the evaluation technology, only relying on fixed training sets, test sets and development sets, the immutable data set is easy to be learned and broken by the machine model, resulting in a very short life cycle of evaluation. Therefore, there is still a need for further breakthroughs in evaluation technology.
Third, more than 10 fruitful achievements, Zhiyuan NLP research direction exploration and landing
The technology open day also carried out a phased report on the research results such as "Problems and Countermeasures in Natural Language Processing Evaluation", "Towards a Universal Continuous Knowledge Base", and "Text Repetition Generation", covering more than 10 key NLP scientific research issues such as pre-training models, knowledge computing, human-computer dialogue, and text generation.
With the support of Zhiyuan Research Institute, a team of scholars in major research directions of natural language processing actively explores a new pattern of natural language processing, and significantly improves the semantic understanding and generation ability of Chinese natural language with natural language as the core through the two-wheel drive of big data and knowledge-rich knowledge, and through interaction with cross-modal information.
In terms of landing application, the "multimodal Beijing Tourism Knowledge Atlas" built by the team of Li Juanzi, a professor at Tsinghua University and a researcher at Zhiyuan, can provide data support for functions such as path planning and scenic spot information query, and plan tourism itineraries for tourists.
In view of the shortcomings of large-scale and trained language models in the task of long text comprehension, dr. He Xiaodong, vice president of JD Group and researcher of Zhiyuan, proposed a machine reading comprehension model based on multiple perspectives through the repeated reading method (Read-over-Read, RoR) from the local perspective to the global perspective, which significantly improved the reading comprehension ability for long texts.
In terms of diversified text repetition, the scientific research results of Wan Xiaojun, a researcher at the Wang Xuan Institute of Computer Science and a researcher at Zhiyuan university, have achieved two "industry firsts": the industry's first textreference dataset ParaSCI has been successfully constructed, divGAN, a diversified sentence repetition model, and the industry's first chapter repetition model - CoRPG. This series of studies provides basic data resources, method models and new ideas for the field of text repetition, respectively, so as to promote the application of text repetition technology.
In terms of pre-training large models, in order to break through the bottlenecks such as high computing cost, high equipment requirements, and difficult application adaptation of pretrained language models (PLM), Liu Zhiyuan, associate professor of Tsinghua University and young scientist of Zhiyuan, proposed a full-process efficient computing framework for PLM, and based on this framework, a super-large-scale pre-trained language model CPM-2 with Chinese as the core was constructed, with 198 billion parameters, covering multiple languages, Taking into account the functions of language understanding and language generation, it has developed supporting open source tools such as BMInf and OpenPrompt.
Zhao Xin, Han Xianpei, Zhang Jiajun and other 7 young scientists also brought the latest achievements on pre-training models, multi-modal languages and other aspects to share, bringing a new generation of scholars to the forefront of thinking.
Including the direction of NLP, the "Zhiyuan Scholar Program" launched by the Zhiyuan Research Institute in April 2019 has gathered nearly 100 first-class artificial intelligence scholars in several major research directions such as the mathematical basis of artificial intelligence, the cognitive neural basis of artificial intelligence, machine learning, intelligent information retrieval and mining, intelligent architecture and chips, etc., to encourage and support scholars to conduct free exploration.
At present, Zhiyuan Research Institute adheres to the principle of "free exploration + goal orientation", and has achieved a number of first-time and original-level major achievements such as the "Enlightenment" big model, and has accumulated support - published more than 1470 papers in the top journal of the International Artificial Intelligence Summit, applied for 82 Chinese patents, obtained 49 invention patents, and registered 24 software copyrights.
Next, the Great Model of Enlightenment will continue to be the booster research direction of the Zhiyuan Research Institute. In an interview with the media, Professor Sun Maosong mentioned that the recognition of the big model development will enter the judgment of the cooling off period, the development of the big model is now to two trillion parameters, and then up, the simple scale expansion is meaningless, but the big model shows a lot of wonderful, profound nature, the next step should be studied, if the several problems in this are clear, it is possible to let the big model as an introduction, lead to more profound model problems, go straight to almost, but the big model digested thoroughly, It is possible that there will be a relatively large peak circuit rotation.
"The wonderful nature has not been well explained now, this thing is clear, the study of brain science can basically cover," Professor Sun said, "because the study of the human brain has many limitations, but the study of neural network artificial brain, all the parameters of the artificial brain are transparent to us, detection is also very accurate, brain research does not have these good conditions." If this piece is thoroughly studied, there may be a deeper level of development. ”
Conclusion: Chinese NLP review has a long way to go
As Academician Dai Qionghai said in his speech, if natural language processing is a pearl in the crown of artificial intelligence, the establishment of scientific evaluation standards requires the search for the pearl itself, if the direction is wrong, the farther it goes, the more deviation, it is likely to be found.
In the past decade, intelligent language processing has made rapid progress, especially the breakthrough of technologies such as ultra-large-scale pre-training language models, and the English language proficiency evaluation benchmark has played a crucial guiding role. He hopes that in the future, with the joint efforts of scholars, teachers and students, the Zhiyuan Index can continue to formulate and improve the evaluation system, unite more research institutions and universities, scholars, companies, and researchers, and contribute important forces, and also look forward to seeing the progress and important contributions of machine Chinese language capabilities based on the Zhiyuan Index every year in the future.