智東西(公衆号:zhidxcom)
作者 | ZeR0
編輯 | 漠影
智東西1月4日報道,上周四(12月30日),在北京智源人工智能研究院自然語言處理重大研究方向前沿技術開放日上,北京智源人工智能研究院(以下簡稱“智源研究院”)釋出大模型評測的“命題”新方案——智源指數。
NLP是智源重大學術研究方向之一,由清華大學孫茂松教授任該方向首席科學家,北京語言大學楊爾弘教授任項目經理,學者包括李涓子、穗志方、劉洋、萬小軍、何曉冬,青年科學家包括劉知遠、韓先培、孫栩、嚴睿、張家俊、趙鑫、楊植麟、李紀為等。
除了釋出智源指數外,本次技術開放日期間,24位自然語言處理(NLP)學術專家,20多項前沿報告、10餘項最新研究成果“組團”亮相。
一、智源指數CUGE:面向大模型的多層次、多元度評測方案
據清華大學副教授、智源青年科學家、智源指數建設骨幹成員劉知遠介紹,智源指數CUGE(全稱為Chinese Language Enderstanding and Generation Evaluation)是一個全面均衡的機器中文語言能力評測基準,在全面系統的評測體系基礎上建立了多層次、多元度的評測方案。
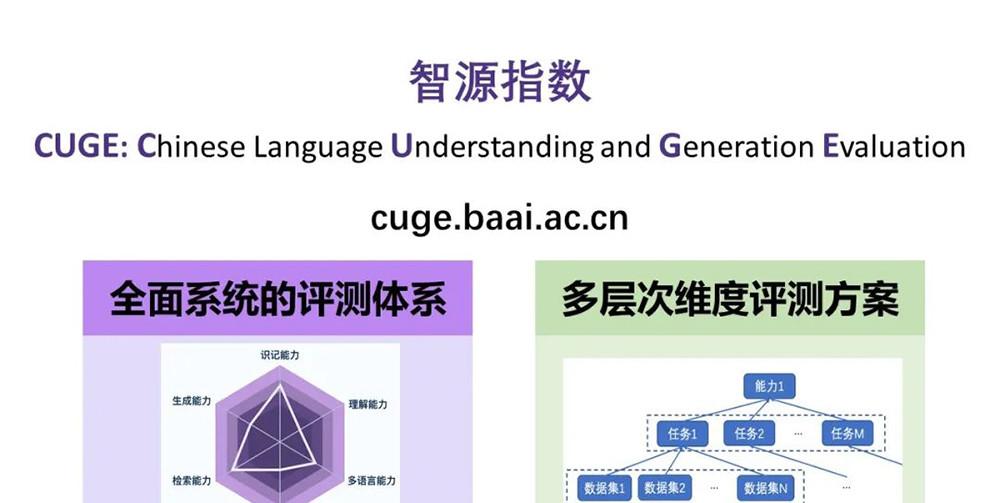
CUGE網站連結:cuge.baai.ac.cn
技術報告連結:arxiv.org/pdf/2112.13610.pdf
代碼連結:github.com/TsinghuaAI/CUGE
在基準架構上,不同于傳統将常用資料集扁平組織的方式,智源指數根據人類語言考試大綱和目前NLP研究現狀,以語言能力-任務-資料集的分層架構來選擇群組織資料集,涵蓋7種重要語言能力、17個主流NLP任務和19個代表性資料集,全面均衡,避免“偏科選拔”。

▲智源指數CUGE架構
在評分政策上,參考現有評測方案優缺點,智源指數建構了一個多層次的評測方案,能更好展現模型不同次元的模型語言智能差異:依托能力-任務-資料集層次性基準架構,提供不同層次的模型性能評分,系統性大大加強。
智源指數會提供一個參與者模型的性能排行榜,該排行榜充分吸收了國内外相關評測基準的特點,建構出了一個具有相應特色。
第一,排行榜基于能力-任務-資料集體系,會給每一個資料集所對應的标簽,友善參與者篩選出感興趣的能力或角度,進行相應的評測。
第二,基于标簽體系,支援參與者通過标簽篩選的方式定制排行榜。同時官方也會提供若幹代表推薦套餐,如精簡榜等,更加友善地讓參與者利用其平台開展有針對性的能力評測。
第三,根據7種重要語言能力呈現雷達圖,直覺反映不同模型在不同能力上提升的效果。
第四,平台同時會支援單資料集的排行榜和評測,更加有利于參與者去追蹤資料集研究的進展和動态。也就是說,任何一個單個資料集,都可以看到相關評測效果的榜單。
“我們希望以學術的視角建構智源指數,讓它回歸我們本身構造這種評測基準的初心,不是變成刷榜的行為。”劉知遠認為,專門針對榜做優化,并不意味着大模型在應用場景中獲得很好的效果,這種行為沒有意義,反而會浪費非常大的算力和時間。
智源指數會每年定期吸納新的優秀資料集加入到智源指數的計算中來,同時所有的送出者必須填寫Honor Code并展示,不人工幹預資料預訓練和測試過程。未來智源也計劃依托智源研究院、智源社群的力量,提供使用者面向資料集和評測結果的回報意見、讨論機制,通過互動交流來去建構起中文高品質資料集社群的機制,來推動中文的自然語言處理的發展。
為了更好地去支援智源指數的發展,智源研究院搭建了「智源指數工作委員會」,由孫茂松擔任主任,穗志方和楊爾弘擔任副主任。目前,委員會機關已經吸納了國内在自然語言處理方面10餘家優勢機關,接近20個相關優勢研究組,去針對智源指數不斷進行改進,力求更加科學、規範、高品質地推進中文自然語言處理技術的标準評測。
對此,清華大學教授、中國人工智能學會理事長戴瓊海院士評價說:“祝賀孫茂松教授帶領智源NLP學者共同建立了機器中文語言能力評測基準智源指數,這對中文資訊處理乃至我國人工智能的發展具有重要的裡程碑意義。”
二、穗志方:NLP評測中的問題與對策
在智源學者成果報告會環節,北京大學穗志方教授分享了NLP評測中的問題與對策。
他談到NLP評測中存在的問題涉及評測的規範性、效率、名額、周期、資料集及任務等。
首先,評測缺乏一定規範性。這緻使評測的準入門檻非常低,評測數量過多而品質參差不齊,研究者們往往采用對自己的模型最有利的資料集,并聲稱達到了最好結果,這導緻後續研究者難以客觀地比較和超越,使得公衆難以把握目前領域的真實研究水準。
第二,評測效率衰退。面對參數量越來越大的模型,大部分現有評測任務已經無法明顯區分人類水準和機器表現。大部分評測在短時間内失去了效力,這被稱之為評測效力衰退。
第三,評測生命周期非常短。部分評測資料集提出後不久,最好的機器模型得分就超過了人類基準。評測系統過快失去效力,缺少生命力。
NLP評測的是語言能力還是語言表現,這是一個比較深刻的問題。周期短、效力衰退僅僅是語言上的一種表現,語言能力如何去真正評估機器的語言能力,我們需要評測的是機器的語言能力,而不僅僅是表層的一種行為臨時的呈現。
另一個問題是通用的NLP評測。通用的NLP評測是否能夠完整、綜合、系統的考察機器了解與語言處理的綜合能力?我們看到的是綜合性彙總,綜合性評測可能并不是綜合,隻是簡單的資料聚合,各任務之間缺乏有機關聯,各個任務沒有真正結合成一個系統,缺乏一個系統性的體系。
評測技術單一,為什麼機器模型在短期内可以達到比較高的水準?有一部分原因是因為評測技術,僅僅依托于固定的訓練集、測試集和開發集,一成不變的資料集很容易被機器模型學會、突破,導緻評測的生命周期非常短。是以,評測技術方面還有待進一步突破。
三、10餘項豐碩成果,智源NLP研究方向探索與落地并重
本次技術開放日中還進行了“自然語言處理評測中的問題與對策”、“邁向通用連續型知識庫”、“文本複述生成”等研究成果的階段性彙報,内容涵蓋預訓練模型、知識計算、人機對話、文本生成等10餘項重點NLP科研問題。
在智源研究院的支援下,自然語言處理重大研究方向學者團隊積極探索自然語言處理新格局,通過大資料與富知識雙輪驅動,并通過與跨模态資訊進行互動,顯著提升以自然語言為核心的中文語義了解與生成能力。
落地應用方面,清華大學教授、智源研究員李涓子團隊建構的“多模态北京旅遊知識圖譜”可以為路徑規劃和景點資訊查詢等功能提供資料支援,為遊客進行旅遊行程的規劃。
京東集團副總裁、智源研究員何曉冬博士團隊針對大規模與訓練語言模型在長文本了解任務上的不足,通過從局部視角到全局視角的重複閱讀方法(Read-over-Read,RoR),提出了一種基于多視角的機器閱讀了解模型,顯著地提高了針對長文本的閱讀了解能力。
多樣性文本複述方面,北京大學王選計算機研究所研究員、智源研究員萬小軍團隊的科研成果實作了兩個“業界首個”:成功建構了業界首個面向學術文獻領域的文本複述資料集ParaSCI,提出了多樣化語句複述模型DivGAN,并提出業界首個篇章複述模型-CoRPG。該系列研究分别為文本複述領域提供了基礎資料資源、方法模型以及新的思路,進而推動文本複述技術的應用落地。
預訓練大模型方面,為突破預訓練語言模型(Pretrained Language Model, PLM)的高計算成本、高裝置需求、難應用适配等瓶頸問題,清華大學副教授、智源青年科學家劉知遠等提出了面向PLM的全流程高效計算架構, 并基于此架構建構了以中文為核心的超大規模預訓練語言模型CPM-2,具有1980億參數,覆寫多語言、兼顧語言了解和語言生成的功能,并研制了BMInf、OpenPrompt等配套開源工具。
趙鑫、韓先培、張家俊等7位青年科學家,也帶來關于預訓練模型、多模态語言等方面的最新成果分享,帶來新一代學者的前沿思考。
包括NLP方向在内,智源研究院于2019年4月啟動的“智源學者計劃”,目前已在人工智能的數理基礎、人工智能的認知神經基礎、機器學習、智能資訊檢索與挖掘、智能體系架構與晶片等幾大研究方向彙聚了近百位一流人工智能學者,鼓勵支援學者進行自由探索。
目前,智源研究院堅持“自由探索+目标導向”并重,取得了“悟道”大模型等多項首發、原創級重大成果,已累計支援——發表國際人工智能頂會頂刊論文1470餘篇,申請中國專利82件,獲得發明專利授權49件,登記軟體著作權24項。
接下來,悟道大模型仍将是智源研究院的助推研究方向。在接受媒體采訪時,孫茂松教授提到認同大模型發展将進入冷靜期的判斷,大模型發展現在到了兩萬億的參數,再往上發展,單純的規模擴大有沒有意義,但是大模型展現出很多奇妙的、深刻的性質,下一步應該研究,如果把這裡面幾個問題搞清楚了,有可能讓大模型作為一個引子,引出更深刻的模型上的問題,直着走差不多了,但是把大模型消化透,有可能會有比較大的峰回路轉。
“奇妙的性質現在還沒有得到很好的解釋,這個東西搞明白了,對腦科學的研究基本能覆寫,”孫教授說,“因為研究人腦有很多限制,但是研究神經網絡人工腦,人工腦所有參數對我們都是透明的,檢測也是非常精準的,腦的研究沒有這些好的條件。這塊如果這個問題研究透了,可能會有更深層次的發展。”
結語:中文NLP評測任重道遠
正如戴瓊海院士在演講中所言,如果說自然語言處理是人工智能皇冠上的一顆明珠,建立科學的評價标準就需要尋找這顆明珠的本身,如果方向錯了走的越遠、偏離越多,很有可能找不到。
近十年裡智能語言處理突飛猛進,特别是超大規模預訓練語言模型等技術的突破,英文語言能力評價基準發揮了至關重要的指引作用。他希望未來智源指數能夠在各位學者、老師和同學們的共同努力下,不斷制定完善評價體系,團結更多研究機構和大學、學者、公司、研究人員,貢獻重要的力量,也期待未來每年都能夠看到基于智源指數的機器中文語言能力的進展和重要貢獻。