hashmap是一個高效通用的資料結構,它在每一個java程式中都随處可見。先來介紹些基礎知識。你可能也知 道,hashmap使用key的hashcode()和equals()方法來将值劃分到不同的桶裡。桶的數量通常要比map中的記錄的數量要稍大,這樣 每個桶包括的值會比較少(最好是一個)。當通過key進行查找時,我們可以在常數時間内迅速定位到某個桶(使用hashcode()對桶的數量進行取模) 以及要找的對象。
這些東西你應該都已經知道了。你可能還知道哈希碰撞會對hashmap的性能帶來災難性的影響。如果多個hashcode()的值落到同一個桶内的 時候,這些值是存儲到一個連結清單中的。最壞的情況下,所有的key都映射到同一個桶中,這樣hashmap就退化成了一個連結清單——查找時間從o(1)到 o(n)。我們先來測試下正常情況下hashmap在java 7和java 8中的表現。為了能完成控制hashcode()方法的行為,我們定義了如下的一個key類:
key類的實作中規中矩:它重寫了equals()方法并且提供了一個還算過得去的hashcode()方法。為了避免過度的gc,我将不可變的key對象緩存了起來,而不是每次都重新開始建立一遍:
現在我們可以開始進行測試了。我們的基準測試使用連續的key值來建立了不同的大小的hashmap(10的乘方,從1到1百萬)。在測試中我們還會使用key來進行查找,并測量不同大小的hashmap所花費的時間:
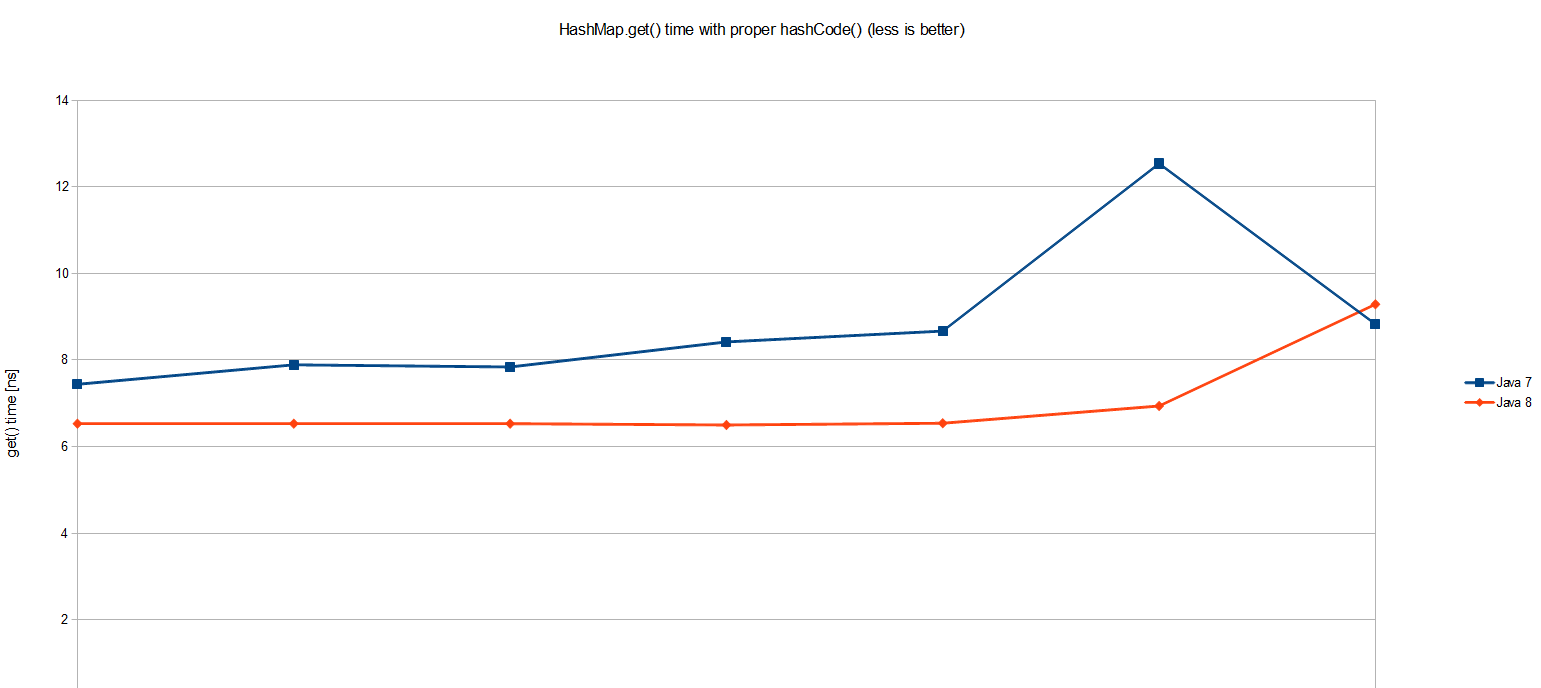
有意思的是這個簡單的hashmap.get()裡面,java 8比java 7要快20%。整體的性能也相當不錯:盡管hashmap裡有一百萬條記錄,單個查詢也隻花了不到10納秒,也就是大概我機器上的大概20個cpu周期。 相當令人震撼!不過這并不是我們想要測量的目标。
假設有一個很差勁的key,他總是傳回同一個值。這是最糟糕的場景了,這種情況完全就不應該使用hashmap:

java 7的結果是預料中的。随着hashmap的大小的增長,get()方法的開銷也越來越大。由于所有的記錄都在同一個桶裡的超長連結清單内,平均查詢一條記錄就需要周遊一半的清單。是以從圖上可以看到,它的時間複雜度是o(n)。
不過java 8的表現要好許多!它是一個log的曲線,是以它的性能要好上好幾個數量級。盡管有嚴重的哈希碰撞,已是最壞的情況了,但這個同樣的基準測試在jdk8中的時間複雜度是o(logn)。單獨來看jdk 8的曲線的話會更清楚,這是一個對數線性分布:
為什麼會有這麼大的性能提升,盡管這裡用的是大o符号(大o描述的是漸近上界)?其實這個優化在jep-180中已經提到了。如果某個桶中的記錄過 大的話(目前是treeify_threshold = 8),hashmap會動态的使用一個專門的treemap實作來替換掉它。這樣做的結果會更好,是o(logn),而不是糟糕的o(n)。它是如何工作 的?前面産生沖突的那些key對應的記錄隻是簡單的追加到一個連結清單後面,這些記錄隻能通過周遊來進行查找。但是超過這個門檻值後hashmap開始将清單升 級成一個二叉樹,使用哈希值作為樹的分支變量,如果兩個哈希值不等,但指向同一個桶的話,較大的那個會插入到右子樹裡。如果哈希值相等,hashmap希 望key值最好是實作了comparable接口的,這樣它可以按照順序來進行插入。這對hashmap的key來說并不是必須的,不過如果實作了當然最 好。如果沒有實作這個接口,在出現嚴重的哈希碰撞的時候,你就并别指望能獲得性能提升了。
這個性能提升有什麼用處?比方說惡意的程式,如果它知道我們用的是雜湊演算法,它可能會發送大量的請求,導緻産生嚴重的哈希碰撞。然後不停的通路這些 key就能顯著的影響伺服器的性能,這樣就形成了一次拒絕服務攻擊(dos)。jdk 8中從o(n)到o(logn)的飛躍,可以有效地防止類似的攻擊,同時也讓hashmap性能的可預測性稍微增強了一些。我希望這個提升能最終說服你的 老大同意更新到jdk 8來。
測試使用的環境是:intel core i7-3635qm @ 2.4 ghz,8gb記憶體,ssd硬碟,使用預設的jvm參數,運作在64位的windows 8.1系統 上。