.本節書摘來自華章出版社《機器學習系統設計:python語言實作》一書中的第1章,第1.2節,作者 [美] 戴維·朱利安(david julian),更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視
我們經常拿系統設計和其他事物的設計進行類比,例如建築設計。在一定程度上,這種類比是正确的,它們都是依據規格說明,在結構體中放置設計好的元件。但當我們考慮到它們各自的運作環境時,這種類比就會瓦解。在建築設計上,通常會假設,當景觀正确形成後就不會再改變。
軟體環境則有些不同。系統是互動和動态的。我們設計的任何系統,諸如電子、實體,或人類,都會嵌入在其他系統中。同樣,在計算機網絡中有不同的層(應用層、傳輸層、實體層,等等),具有不同的含義和功能集,是以在項目中,需要在不同的層完成所需執行的活動。
作為這些系統的設計師,我們必須對其背景(即我們所工作的領域)具有強烈意識。領域知識能夠賦予我們工作的背景,為我們在資料中發現模式提供線索。
機器學習項目可以分解為如下6項不同的活動:
定義目标和規格說明
準備和探索資料
建立模型
實作
測試
部署
設計師主要關注前三項活動。但是,他們通常需要在其他活動中扮演主要角色,并且在許多項目中必須如此。同時,這些活動在項目的時間表中不一定是線性序列。但重點是,這些都是明确不同的活動。這些活動可以并行進行,或者彼此互相作用,但通常會涉及不同類型的任務,在人力和其他資源、項目階段和外在性上互相分離。而且,我們需要考慮到不同的活動所涉及的操作模式也彼此不同。想想看,我們在勾勒想法時、進行特定分析任務時,以及編寫一段代碼時,大腦工作方式的差異。
通常,最困難的是從何下手。我們可以先專研某一問題的不同要素,構思其中的特征集,或者考慮用什麼模型。這樣就能得出目标和規格說明的定義。或者我們可能不得不進行一些初步研究,例如檢查潛在的資料集和資料源、評估适用的技術,或與其他工程師、技術專家和系統使用者進行探讨。我們還需要探索操作環境和各種限制;确定這是一個web應用還是科學家們的實驗室研究工具。
在設計的早期階段,我們的工作流程會在不同要素的工作上切來切去。例如,我們首先着手于必須要解決的一般性問題,這時可能隻是形成一些關于任務的思路,然後就将其分解為我們認為是關鍵的特征,嘗試使用模拟的資料集對其建立一些模型,再回過頭來修訂特征集,調整模型,細化任務,改進模型。當感覺系統足夠健壯時,可以使用一些真實資料進行測試。當然,有可能需要回過頭來改變特征集。
對于機器學習設計師而言,選擇和優化特征通常是一項主要活動(其本身就是一個任務)。在沒有充分地描述任務之前,我們無法真正确定所需的特征。當然,任務和特征都受我們所建立的可行模型的類型的限制。
作為設計師,我們的責任是解決問題。我們要在所提供的資料上得出預期的成果。第一步是以機器能夠了解的方式來表示問題,同時這種方式也能夠承載人類的意圖。以下六點概括了問題的類型,可以幫助我們精确定義所要解決的機器學習問題:
探索(exploratory):分析資料,尋找模式,例如趨勢或不同變量之間的關系。探索通常會得出一些假設,例如,飲食和疾病的關聯、犯罪率和城鎮住宅的關聯等。
描述(descriptive):總結資料的具體特征。例如,平均壽命、平均溫度,或人口中左撇子的數量等。
推理(inferential):推理性問題是用來支援假設的,例如,使用不同資料集來證明或證僞壽命和收入之間存在一般性關聯。
預測(predictive):預測未來的行為。例如,通過分析收入來預測壽命。
原因(casual):試圖發現事物的原因。例如,短壽命是否是由低收入導緻的?
機制(mechanistic):試圖解答諸如“收入和壽命關聯的機制是什麼?”的問題。
大多數機器學習系統在開發過程中會涉及多種問題類型。例如,我們首先需要探索資料來發現模式或趨勢,然後需要描述資料的具體關鍵特征。這樣,我們可能會給出一個假設,并發現其原因或特定問題背後的機制。
問題在其主題領域内必須是合理且有意義的。領域知識能夠幫助我們了解資料中重要的事物,發現有意義的特定模式和相關性。
問題應該盡可能具體,同時還能給出有意義的答案。通常在開始時,對問題的陳述不那麼具體,例如“财富是否意味着健康”。是以,我們需要進一步研究。我們會發現,可以從稅務局得到地域财富統計,可以通過健康的對立面,即疾病,來度量健康,而疾病資料可以從醫院接診處獲得。這樣,我們就能夠将疾病和地域财富進行關聯,驗證最初的命題:“财富意味着健康”。我們可以發現,更為具體的問題會依賴于多個可能存疑的假設。
我們還應該考慮到,窮人可能沒有醫療保險,是以生病了也不大可能去醫院,而這一因素可能會混淆我們的結果。我們想要發現的事物和試圖去度量的事物之間具有互相作用。這種互相作用可能會隐藏真實的疾病率。但是還好,因為知道這些領域知識,我們或許能夠在模型中解釋這些因素。
通過學習盡可能多的領域知識,能夠讓事情變得簡單得多。
檢查一下我們的問題是否已經有答案,或者部分問題已有答案,又或者已經存在資料集對此有所啟示,這都有可能節省大量的時間。通常,我們需要同時從不同角度來處理問題。我們應該盡可能做更多的準備性研究。其他設計師完成的工作很可能會對我們所有啟發。
任務是一段時間内進行的特定活動。我們必須區分人工任務(計劃、設計和實作)和機器任務(分類、聚類、回歸等)。同時也要考慮有時人工任務會和機器任務重合,例如,為模型選擇特征。在機器學習中,我們真正的目标正是要盡可能地将人工任務變換為機器任務。
現實世界中的問題到具體任務的适配并不總是很容易。很多現實世界的問題看起來可能有概念上的關聯,但是卻需要非常不同的解決方案。與之相反,看起來完全不同的問題,卻可能需要相同的方法。不幸的是,在問題和特定任務之間的适配不存在什麼簡單的查找表,而更多依賴于背景和領域。同樣的問題,換個領域,可能就因為缺少資料而無法解決。然而,在适用于解決衆多最具共性的問題類型的大量方法中,存在少數通用的任務。換言之,在所有可能的規劃任務的空間内,存在一個任務子集,适用于特定問題。在這個子集内,存在更小的任務子集,是簡單有效的。
機器學習任務大緻有如下三種環境:
有監督學習(supervised learning):其目标是,從有标簽訓練資料中學習建立模型,允許對不可見的未來資料進行預測。
無監督學習(unsupervised learning):處理無标簽資料,其目标是在資料中發現隐含模式,以抽取有意義的資訊。
強化學習(reinforcement learning):其目标是,開發一個系統,基于該系統與其環境的互相作用,提高系統的性能。其中通常會引入獎賞信号。與有監督學習類似,但是沒有标簽訓練集,強化學習使用獎賞函數來持續改進其性能。
現在,讓我們看看一些主要的機器學習任務。下圖可以作為我們的起點,嘗試決定不同的機器學習問題适用什麼類型的任務。
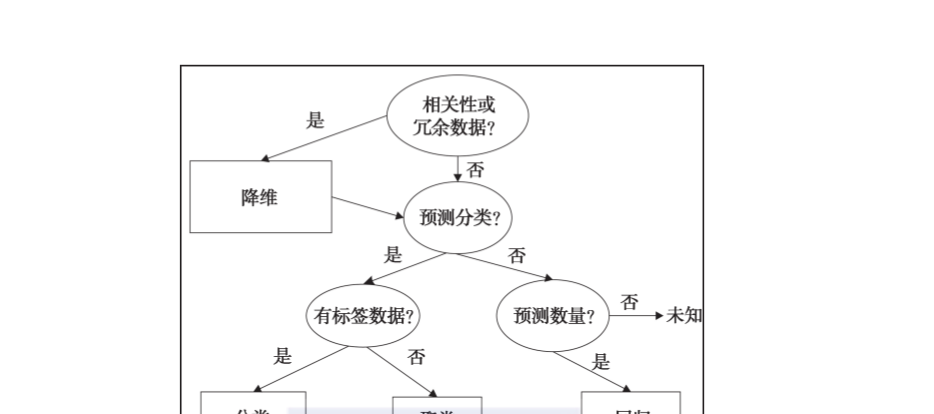
1.分類
分類大概是最常見的任務類型了,主要是因為它相對容易,很好了解,能夠解決很多常見問題。分類基于特征對一組執行個體(樣本)賦予類别。分類是有監督學習方法,它依賴标簽訓練集來建立模型參數。建立好的模型可以應用于無标簽資料,用來預測每個執行個體所屬的類别。大緻上,有兩種分類任務:二分類(binary classification)和多分類(multiclass classification)。垃圾郵件檢測就是一種典型的二分類任務,它隻有兩種類别,即垃圾或非垃圾,它根據郵件内容來确定其所屬類别。手寫識别則是多分類的例子,它需要預測輸入的是什麼字元。在這種情況下,每個字母和數字字元都是一個類别。多分類有時可以通過連結多個二分類任務來實作,但是這種方法會丢失資訊,我們無法定義單一決策邊界。是以,多分類和二分類通常需要分别對待。
2.回歸
在某些情形下,我們所關心的事物并非是離散的類别,而是連續變量,例如機率。這種類型的問題稱為回歸問題。回歸分析的目的是,了解自變量的變化如何影響因變量的變化。最簡單的回歸問題是線性的,為了進行預測,需要将一組資料近似為一條直線。這種方法通常需要最小化訓練集中每個執行個體的誤差平方和。典型的回歸問題有,通過給定的症狀範圍和嚴重程度,評估相應疾病的可能性,或者根據過往表現來預測測試得分。
3.聚類
聚類是最為著名的無監督方法。聚類關注的是,對無标簽資料集内執行個體的相似性進行度量。我們通常會基于執行個體的特征值,采用幾何模型,度量執行個體之間的距離,來确定其相似性。我們可以使用任意封閉的路徑成本,來确定每個執行個體所屬的聚類簇。在資料挖掘和探索性資料分析中會經常使用聚類。有大量不同的方法和算法用來執行聚類任務,其中有些會利用這種基于距離的方法,并且還會發現每個聚類簇的中心點,還有一些方法會利用基于分布的統計技術。
關聯和聚類有關,也是一種無監督任務,用以在資料中發現特定類型的模式。很多産品推薦系統都使用了這一方法,例如amazon和其他網店。
4.降維
很多資料集中,每個執行個體都包含了大量特征或路徑成本。這會給計算能力和記憶體配置設定帶來挑戰。同時,很多特征會包含備援資訊,或與其他特征相關的資訊。在這種情況下,學習模型的性能可能會顯著退化。降維最常用于特征預處理,它将資料壓縮到較低次元的子空間,但同時保留了有用的資訊。降維也常用于資料可視化,通常将高維資料投影為一維、二維、或三維資料。
源自這些基礎的機器學習任務還有大量派生任務。在許多應用中,學習模型可能隻是用來進行預測以建立因果關系。我們必須知道,解釋和預測并不相同。模型可以用來進行預測,但除非明确地知道它是如何進行預測的,否則我們無法形成可了解的解釋。解釋需要人類的領域知識。
我們還可以使用預測模型發現與一般模式不同的例外。而這時,我們感興趣的正是這些與預測偏離的個例。這通常稱為異常檢測(anomaly detection),而且有着廣泛應用,例如,銀行欺詐檢測、噪聲過濾,甚至是尋找外星生命。
還有一種重要且可能有用的任務是子群發現。子群發現的目标與聚類不同,不是對整個領域進行劃分,而是發現具有基本上不同分布的子群。本質上,子群發現是試圖在目标因變量和大量解釋性自變量之間找到關系。我們并非試圖找到領域内的完整關系,而是其中不同的具有重要意義的一組執行個體。例如,對目标變量heart disease=true,建立一個子群,其解釋變量為smoker=true且family history=true。
最後,我們還要考慮控制類型的任務。這些任務是根據不同條件,對控制設定進行優化,最大化收益。控制任務可以有多種方式。我們可以克隆專家行為:機器直接學習人類,對不同條件下的行動進行預測。這項任務是學習專家行動的預測模型。這類似于強化學習,其任務是學習條件和最優行動之間的關系。
5.錯誤
對于機器學習系統,軟體缺陷會給現實世界帶來非常嚴重的後果;如果我們的算法用于裝配線機器人,當它把人分類為産品元件會發生什麼?顯然,對于關鍵系統,我們需要對失敗進行計劃。在我們的設計過程和系統中,應該具備健壯的故障和錯誤檢測程式。
有時,有必要隻是為了調試和檢查邏輯缺陷而設計十分複雜的系統。可能還有必要建立具有特定統計結構的資料集,或者建立人造人去模拟人機界面。例如,為了驗證設計在資料、模型和任務等不同層次上都是合理的,我們需要開發一系列方法。錯誤可能是難以跟蹤的,但是作為科學家,我們必須假設系統中存在錯誤,否則就必須努力進行論證。
對于軟體設計師而言,識别和優雅地捕獲錯誤的思想很重要,但作為機器學習系統設計師,我們必須更進一步。在我們的模型中,我們需要擷取從錯誤中學習的能力。
我們必須考慮如何選擇測試集,特别是,測試集如何代表其餘資料集。例如,如果與訓練集相比,測試集充滿更多噪聲資料,這将會導緻惡劣的結果,說明我們的模型過度拟合,然而事實上卻并非如此。為了避免這種情況,可以使用交叉驗證。交叉驗證将資料随機分為大小相等的資料塊,例如分為十個資料塊。我們使用其中九個資料塊對模型進行訓練,使用剩下的一個資料塊進行測試。然後,重複十次該過程,每次使用不同的一個資料塊進行測試。最後,我們采用十次測試的平均結果。除了分類,交叉驗證還可以用于其他有監督學習問題,但是正如我們所知道的,無監督學習問題需要不同的評估方法。
在無監督任務中,我們沒有有标簽訓練集。是以,評估會有些棘手,因為我們不知道正确的結果是什麼樣的。例如,在聚類問題中,為了比較不同模型的品質,我們可以度量簇直徑和簇間距之間的比率。然而,對于複雜問題,我們可能永遠不知道是否存在更好的模型,也許該模型還沒有建立。
6.優化
優化問題在不同領域都普遍存在,例如,金融、商業、管理、科學、數學和工程等。優化問題包括以下幾個方面:
目标函數,我們想要最大化或最小化目标函數。
決策變量,即一組可控輸入。這些輸入在特定限制内可變,以滿足目标函數。
參數,即不可控或固定的輸入。
限制條件,即決策變量和參數之間的關系。限制條件定義了決策變量的取值空間。
大多數優化問題隻有單一的目标函數。當有多目标函數時,我們通常會發現它們彼此有沖突,例如,降低成本和增加産量。在實踐中,我們試圖将多目标轉化為單一函數,例如通過建立目标函數的權重組合。在成本和産量例子中,類似機關成本這樣的變量可能會解決問題。
為實作優化目标,我們需要控制決策變量。決策變量可能包括諸如資源或人工等事物。每個運作模型的子產品,其參數是不變的。我們可以使用幾種測試案例,選擇不同的參數,測試在多種條件下的變化。
對于衆多不同類型的優化問題,存在成千上萬的解決算法。大多數算法首先會找到一個可行解,然後通過調整決策變量,進行疊代改進,以此來發現最優解。使用線性規劃技術可以相當好地解決許多優化問題。其中假設目标函數和所有限制與決策變量呈線性關系。如果這些關系并非是線性的,我們通常會使用适當的二次函數。如果系統是非線性的,則目标函數可能不是凸函數。也就是說,可能會存在多個局部極小值,同時不能保證局部極小值是全局極小值。
7.線性規劃
線性模型為何如此普遍?首先是因為其相對容易了解和實作。線性規劃有着完善的數學理論基礎,其于18世紀中期就已經發展形成,此後,線性規劃在數字計算機的發展中扮演着極為關鍵的角色。因為計算機的概念化大量依賴于線性規劃理論基礎,是以計算機極為适合于實作線性規劃。線性函數總是凸函數,即隻有一個極小值。線性規劃(linear programming,lp)問題通常使用單純形法求解。假設要求解優化問題,我們将采用如下文法來表示該問題:

假設其中的x1和x2都大于等于0。我們首先需要做的是将其轉換為标準型。完成這一轉換需要確定該問題是極大化問題,即需要将min z轉換為max –z。我們還需要通過引入非負松弛變量将不等式轉換為等式。這裡的例子已經是最大化問題了,是以可以保留我們的目标函數不變。我們需要做的是将限制條件中的不等式變為等式:
如果以z來表示目标函數的值,則可以将目标函數變換為如下表達式:
如此,我們可以得到如下線性方程組:
我們的目标是求解極大化z,并且注意其中所有變量都是非負值。我們可以發現x1和x2出現在所有方程中,我們稱之為非基變量。x3和x4隻出現在一個方程中,我們稱之為基變量。通過将所有非基變量指派為0,我們可以得到一個基解。這樣可以得到如下方程組:
這是最優解嗎?還記得我們的目标是求極大化z嗎?線上性方程組的第一個方程中有z減x1和x2,是以我們還是能夠增大這些變量的。但如果該方程的所有系數都是非負數,則不可能增大z。我們得知,當目标方程的所有系數為正時,可以得到最優解。
這裡不是這種情況。是以,我們要把目标方程中系數為負的非基變量通過主元消元法(pivoting),變為基變量(例如x1,稱之為進基變量(entering variable))。同時,我們會将基變量變為非基變量,稱之為離基變量(leaving variable)。我們可以看到,x1同時出現在兩個限制條件方程中,那我們選擇哪一個進行主元消元呢?記住我們的目标是要確定系數為正。我們發現,當主元方程的右值與其各自的進基系數的比值最小時,可以得到另一個基解。對于此例中的x1,第一個限制條件方程右值和進基系數比是4/2,第二個限制條件方程是3/1。是以,我們選擇對限制條件方程1中的x1進行主元消元。
用限制條件方程1除以2,得到如下方程式:
這樣,我們可以得到x1,然後将其代入到其他方程中,對x1進行消元。當我們進行一系列代數運算後,最終可以得到如下線性方程組:
如上,我們得到另一個基解。但是,這是最優解嗎?因為在目标方程中,還存在一個負系數,是以答案是否定的。我們同樣可以對x2運用主元消元法,使用最小右值系數比規則,我們發現,可以選擇第三個方程中的3/2x2作為主元。這樣可以得到如下方程組:
這樣,我們可以得到解為和。因為在第一個方程中不存在負系數,是以這是最優解。
我們能夠以如下圖形進行可視化。在陰影區域,我們可以發現可行解。
8.模型
線性規劃為我們提供了将現實世界問題編碼為計算機語言的政策。然而,必須記得我們的目标并非隻是解決一個問題執行個體,而是要建立模型來解決新産生資料中的獨特問題。這是機器學習的本質。學習模型必須具有評估其輸出的機制,據此來改變其行為,以達到最佳求解狀态。
這種模型本質上是一種假設,也就是說,是對現象的一種推薦解釋。其目标是對問題進行歸納。對于有監督學習問題,從訓練集擷取的知識被應用于對無标簽資料的測試上。對于無監督學習問題,例如聚類,系統不是從訓練集學習,而是從資料集本身的特征中學習,例如相似度。無論是哪種情況,其過程都是疊代的,都要重複定義良好的任務集,使模型更接近正确的假設。
模型是機器學習系統的核心,是對學習的實作。有大量模型及其變體,其作用各不相同。機器學習系統可以解決出現在衆多不同背景下的問題(回歸、分類、關聯等)。它們已經成功地被應用于科學、工程學、數學、商業,甚至社會科學等幾乎所有的分支,它們與其所應用的領域一樣具有多樣性。
這種多樣性給機器學習系統帶來了巨大的問題解決能力,但同時也讓設計師有些望而生畏。對于特定問題,哪一個或哪一些模型是最佳的,做出這樣的抉擇并不容易。對于複雜事物,通常有多個模型能夠解決問題,或者解決這個問題需要多個模型。在開始着手這樣的項目時,我們無法輕易知道由初始問題到解決該問題的最為準确和有效的路徑。
就我們的目标而言,可以将模型分為重疊、互斥和排他的三類:幾何、機率和邏輯。在這三個模型之間,必須要關注的差別是如何對執行個體空間(樣本空間)進行劃分。執行個體空間可以被認為是所有可能的資料執行個體,但并不是每個執行個體都要在資料中出現。實際資料是執行個體空間的子集。
劃分執行個體空間有兩種方式:分組和分級。兩者之間的關鍵差異在于,分組模型将執行個體空間劃分為固定的離散單元,稱為段(segment)。分組具有有限解析度,并且無法區分超越了這一解析度的類型。另一方面,分級會對整個執行個體空間形成全局模型,而不是将空間分為段。理論上,分級的解析度是無限的,無論執行個體多麼相似,分級都能夠加以區分。分組和分級的差別也不是絕對的,很多模型都兼而有之。例如,基于連續函數的線性分類器一般被認為是分級模型,但也存在其無法區分的執行個體,比如平行于決策邊界的線或面。
(1)幾何模型
幾何模型使用執行個體空間的概念。幾何模型最顯著的例子是,所有特征都是數值,并且可以在笛卡兒坐标系中坐标化。如果我們隻有兩到三個特征,則很容易可視化。然而,很多機器學習問題都有成百上千個特征和次元,是以不可能對這些空間進行可視化。但是,很多幾何概念,例如線性變換,還是能在這種超空間中應用的。為了便于了解,例如,我們認為很多學習算法具有平移不變性,也就是說,與坐标系原點位置無關;同時,我們可以采用幾何概念中的歐幾裡得距離來度量執行個體間的相似性;這樣我們就有了一種對相似執行個體進行聚類并形成決策邊界的方法。
假設,我們使用線性分類器對文章段落是快樂的還是悲傷的進行分類。我們可以設計一個測試集,給每個測試都配置設定一個權重w,以确定每個測試對總體結果的貢獻。
我們可以用每個測試的分值乘以其權重,并進行求和,以作為總體分值,并以此建立決策邊界,例如,快樂分值是否大于門檻值t。
每個特征值對總體結果的貢獻都是獨立的,是以這一規則是線性的。這一貢獻依賴于特征的相對權重,權重可以為正,也可以為負。計算總體分值時,個體特征值不受門檻值限制。
我們可以使用向量來重新表示以上求和算式,w表示權重向量(w1, w2, ..., wn),x表示測試分值向量(x1, x2, ..., xn)。同時,如果向量次元相等,我們可以定義決策邊界為:
我們可以認為w是負值(悲傷)“質心”n,指向正值(快樂)“質心”p的向量。可以通過分别計算正負值的平均值得到正負值的質心:
我們的目标是以正負值質心的中間值作為決策邊界。可以看到,w與p-n成正比或相等,(p+n)/2即為決策邊界。是以,可以得出如下算式:
在實踐中,真實的資料是具有噪聲的,并且不一定容易分離。即便有時資料是容易分離的,但特定的決策邊界也可能并沒有多大意義。考慮到資料是稀疏的,例如在文本分類器中,單詞總數對于每個單詞執行個體的數量而言是巨大的。在這樣大而空的執行個體空間内找到決策邊界可能很容易,但是否為最佳選擇呢?有種選擇方法是使用邊緣,即決策邊界與執行個體之間的最小距離。我們将在本書中探索這些技巧。
(2)機率模型
貝葉斯分類器是機率模型的典型例子,即給定一些訓練資料(d)和基于初始訓練集的機率(特定假設,h),給出後驗機率p(h/d)。
舉個例子,假設我們有一袋大理石,其中40%是紅色的,60%是藍色的,同時,一半紅色大理石和所有藍色大理石有白斑。當我們伸進袋子選擇一塊大理石時,可以通過感受其紋理得知是否有白斑。那麼得到紅色大理石的機率有多少?
設p(r|f)等于随機抽取有白斑的大理石是紅色的機率:
p(f|r)=紅色大理石有白斑的機率,為0.5。
p(r)=大理石為紅色的機率,為0.4。
p(f)=大理石有白斑的機率,為0.5×0.5+1×0.6=0.8。
機率模型允許我們明确地計算機率,而不僅是在真或假中二選一。正如我們所知,其中的關鍵是需要建立映射特征變量到目标變量的模型。當采用機率方法時,我們假設其背後存在着随機過程,能建立具有良好定義但未知的機率分布。
例如,垃圾郵件檢測器。特征變量x可以由代表郵件可能是垃圾的詞語集合組成。目标變量y是執行個體類型,取值為垃圾或火腿。我們關心的是給定x的情況下,y的條件機率。對于每個郵件執行個體,存在一個特征向量x,由表示垃圾詞語是否出現的布爾值組成。我們試圖發現目标變量y的布爾值,代表是否為垃圾郵件。
此時,假設我們有兩個詞語,x1和x2,構成了特征向量x。由訓練集,我們可以構造下表:
我們可以看到,如果在特征向量中加入更多詞語的話,該表格會快速增長失控。對于n維特征向量,我們會有2n種情況需要區分。幸運的是,有其他方法可以解決這一問題,稍後我們會看到。
表1.1中的機率叫作後驗機率,用于我們具備先驗分布知識的情況下。例如,有1/10的郵件是垃圾郵件。然而,如果我們知道x中包含x2=1,但是不确定x1的值,在這種情況下,該執行個體可以是行2,垃圾郵件的機率是0.7,也可能是行4,垃圾郵件的機率是0.8。其解決方案是,基于x1=1的機率,對行2和行4進行平均。也就是說,需要考慮x1出現在郵件中的機率,無論是否為垃圾郵件:
上式稱為似然函數。如果由訓練集得知x1=1的機率是0.1,x1=0的機率是0.9,因為機率和必須為1,那麼,我們就可以計算郵件包含垃圾詞語的機率是0.7×0.9+ 0.8×0.1=0.71。
這是一個似然函數的例子:p(x|y)。x是我們已知的,y是我們未知的,那麼,為什麼我們想要知道以y為條件x的機率呢?對于了解這一點,我們可以考慮任意郵件包含特定随機段落的機率,假設是《戰争與和平》的第127段。顯然,無論郵件是否為垃圾郵件,這種可能性都很小。我們真正關心的并不是這兩種可能性的量級,而是它們的比率。包含有特定詞語組合的郵件更像是垃圾郵件,還是非垃圾郵件?這些有時被稱為生成模型,因為我們可以對所有相關變量進行采樣。
我們可以利用貝葉斯定理在先驗分布和似然函數之間進行變換:
p(y)是先驗機率,即在觀察到x之前,每種類型的可能性。同樣,p(x)是不考慮y的機率。如果隻有兩種類型,我們可以采用比率的方式。例如,當想要知道資料更支援哪一類型時,可以采用如下比率形式(spam,垃圾郵件;ham,非垃圾郵件):
如果比率小于1,我們假設位于分母的類型的可能性較大。如果比率大于1,則位于分子的類型的可能性較大。當代入表1.1中的資料時,可以計算出如下後驗機率:
似然函數對于機器學習非常重要,因為它建立了生成模型。如果我們知道每個詞語在詞語表中的機率分布,以及在垃圾郵件和非垃圾郵件中出現的可能性,我們就能夠根據條件機率p(x|y=垃圾)生成随機垃圾郵件了。
(3)邏輯模型
邏輯模型以算法為基礎。它們可以被翻譯為人類能夠了解的一組正式規則。例如,如果x1和x2都為1,則郵件被分類為垃圾郵件。
這些邏輯規則可以被組織為樹形結構。在下圖中,我們看到在每一分支上疊代地劃分了執行個體空間。葉子由矩形區域組成(在高次元的情況下,或者是超矩形),代表了執行個體空間的段。基于所要解決的任務,葉子上标記了類型、機率、實數等。
特征樹對于表示機器學習問題十分有用,即便是那些第一眼看上去不是樹結構的問題。例如,在之前章節中的貝葉斯分類器,我們可以根據特征值的組合,将執行個體空間劃分為多個區域。決策樹模型通常會引入剪枝技術,删除給出錯誤結果的分支。在第3章中,我們将看到在python中表示決策樹的多種方式。
請注意,決策規則可能會重疊,并且給出沖突的預測。
這些規則被認為是邏輯不一緻的。當沒有考慮特征空間的所有坐标時,規則也可能是不完整的。有很多方法可以解決這些問題,我們将在本書中詳細介紹。
樹學習算法通常是以自頂向下的方式工作的,是以,首要任務是選擇合适的特征,用于在樹頂進行劃分,以使劃分結果在後續節點具有更高純度。純度指的是,訓練樣本都屬于同一類型的程度。當逐層向下時,我們會發現在每一節點上,訓練樣本的純度都在增加,也就是說,這些樣本逐層被劃分為自己的類型,直到抵達葉子,每一葉子的樣本都屬于同一類型。
從另一角度來看,我們關注降低決策樹後續節點的熵。熵是對混亂的度量,在樹頂(根節點)最高,逐層降低,直到資料被劃分為各自的類型。
在更為複雜的問題中,有更大的特征集和決策規則,有時不可能找到最優的劃分,至少在可接受的時間範圍内是不可行的。我們真正關心的是建立最淺樹,實作到達葉子的最短路徑。就其用于分析的時間而言,每一額外的特征都會帶來每個節點的指數級增長,是以,找到最優決策樹比實際上使用子最優樹來完成任務,所需要的時間更長。
邏輯模型的一個重要特性是,它們可以為其預測提供一定程度的解釋。例如,對于決策樹做出的預測,通過追溯由葉子到根的路徑,可以确定得出最終結果的條件。邏輯模型的優點之一是:能夠被人類探查,揭示更多問題。
9.特征
在現實生活中,我們得到的資訊越多越有價值,那麼所做出的決策也就越好,同理,對于機器學習任務,模型的好壞與其特征息息相關。在數學上,特征是執行個體空間到特定域内集合的映射函數。對于機器學習而言,我們所做的大多數度量都是數值型的,是以,大多數常見的特征域是實數集合。其他常見域還有布爾、真或假、整數(通常用于計算某一特征發生的次數),或諸如顔色或形狀等有限集合。
模型是依據其特征進行定義的。單一特征也能夠成為模型,我們稱之為單變量模型。我們可以差別特征的兩種用法,這與分組和分級的差別相關。
首先,我們關注執行個體空間的具體區域對特征進行分組。設x為一封郵件,f為對郵件中某一詞語x1進行計數的特征。我們可以建立如下條件:
當f(x)=0,表示郵件不包含x1;當f(x)>0,則表示郵件中包含一次或多次x1。這種條件叫作二劃分(binary splits),因為它們将執行個體空間劃分為兩個分組:滿足條件的和不滿足條件的。我們還可以将執行個體空間劃分為多于兩個的段,即非二劃分。例如,當f(x)=0;05,等等。
其次,我們可以對特征進行分級,計算每個特征對總體結果的獨立貢獻。在我們之前所述的簡單線性分類器中,其決策規則如下:
該規則是線性的,是以每一特征對某一執行個體的分值具有獨立貢獻,其貢獻依賴于wi。如果wi為正,則值為正的xi會增加總分值。如果wi為負,則值為正的xi會減少總分值。如果wi很小或者為零,則其對總體結果的貢獻可以忽略不計。可以看到,這些特征對最終預測做出了可度量的貢獻。
特征的這兩種用法,即劃分(分組)和預測(分級)可以在同一模型中組合。有個典型的例子是,當我們求某一非線性函數的近似解時,例如y sin x,其中-1
在特征建構和變換方面,有很多工作可以用來改進模型性能。在大多數機器學習問題中,特征并不一定是直接可用的,而是需要從原始資料集中建構,并變換為模型可用的形式。這在諸如文本分類等問題中尤為重要。在垃圾郵件例子中,我們使用了詞語包的表示形式,因為這樣可以忽略詞語的順序,然而也會丢失有關文本含義的重要資訊。
離散化是特征建構的一個重要部分。有時,我們可以把特征劃分為相應的塊,以抽取與任務更為相關或更多的資訊。例如,假設資料包含一組精确的收入資訊,而我們要試圖确定人們的經濟收入與其所居住的城郊之間是否存在關系。顯然,收入範圍比精确收入更适合作為特征集,盡管嚴格地說,這樣會丢失一些資訊。如果選擇恰當的收入範圍區間,我們不僅不會丢失與問題有關的資訊,而且會讓模型執行得更好,得出的結果也更易于解釋。
這突出了特征選擇的主要任務:從噪聲中分離信号。
現實世界的資料總是包含大量我們不需要的資訊,以及簡單的随機噪聲,而從中分離出我們所需要的資料,可能隻是其中的一小部分資料,對模型的成功是十分重要的。當然,我們不能丢掉對我們可能重要的資訊。
通常,特征可能是非線性的,而且線性回歸的結果可能并不理想。有種技巧是對執行個體空間進行變換。假設我們的資料如下圖所示。顯然,線性回歸隻是得出一種合理的拟合,如下圖左側所示。然而,如果對執行個體空間的資料取平方,即x=x2,y=y2,我們能得出更好的拟合結果,如下圖右側所示。
進一步,我們還可以采用核方法(kernel trick)。其思想是建立更高次元的隐式特征空間,即通過特定函數,有時稱為相似性函數(similarity function),将原始資料集的資料點映射到高維空間。
例如,設和。
如下所示,建立二維到三維的映射:
對應于二維空間中的點x1和x2,其在三維空間中如下所示:
這兩個向量的點積則為:
我們發現,通過對原二維空間的向量點積取平方,即可得到三維空間的向量點積,而無須求得三維空間的向量,再進行點積計算。這裡,我們可以定義核函數為k(x1, x2) = (x1, x2)2。在高維空間計算點積通常代價更高,而使用核方法則更具優勢,我們可以看到,這一技術在機器學習的支援向量機(support vector machines,svm)、主成分分析(principle component analysis,pca)和相關性分析中都有着廣泛應用。
在之前提及的基本線性分類器中,将決策邊界定義為w•x = t。向量w等于正樣本平均值和負樣本平均值的差,即p-n。設點n = (0, 0)和p = (0, 1)。假設我們通過兩個訓練樣本來計算正平均值,p1 = (-1, 1)和p2 = (1, 1),則其平均值如下所示:
這樣,我們可以得到決策邊界為:
如果采用核方法,我們可以用下式來計算決策邊界:
基于我們之前定義的核函數,可以得到下式:
這樣,我們可以導出如下決策邊界:
這正是以t為半徑圍繞原點的圓。
另一方面,使用核方法,每一個新執行個體可以根據每一個訓練樣本進行評估。對于這種更為複雜的計算,其回報是能夠獲得更為靈活的非線性決策邊界。
特征之間的互相作用是非常有趣和重要的,相關性是其中的一種互相作用形式。例如,在部落格文章中的詞語,我們可能期望詞語冬天和寒冷之間是正相關的,冬天和炎熱之間是負相關的。那麼這對我們任務中的模型意味着什麼呢?假如我們是在進行情緒分析,如果這些詞語一起出現,我們可能需要考慮降低其中每個詞語的權重,因為附加了另一相關詞語後,其對總體結果的貢獻,比起該詞語本身,在一定程度上會有所減弱。
同樣是在情緒分析中,我們通常需要變換某些特征,以捕獲其含義。例如,詞組不快樂包含了兩個詞語不和快樂,如果隻是使用1-grams分詞法,可能會得到正面的情緒分值,而其本意明顯是負面的。一種解決方案是(如果使用2-grams分詞法,則可能會不必要地使模型複雜化),當這兩個詞語以這一順序出現時,則建立一個新的特征,即不快樂,并對其配置設定情緒分值。
選擇和優化特征是值得花費時間的。這在學習系統設計中是十分重要的部分。這也是一種疊代設計,需要在兩個階段之間不斷反複。首先,需要了解我們所研究現象的特性;其次,需要通過實驗來測試我們的想法。實驗能夠讓我們對現象進行更為深入的觀察,讓我們能夠獲得更為深入的了解,并對特征進行優化。我們需要重複這一過程,直到模型足以準确反映真實的情況。
1.2.4 統一模組化語言
機器學習系統可以是複雜的。對于人腦而言,了解整個系統的所有互動通常很困難。我們需要某種方式将系統抽象為一組分離的功能元件。通過圖形和場景能夠可視化系統的結構和行為。
uml是一種形式化語言,可以讓我們以一種精确的方式對設計思想進行可視化和溝通。我們使用代碼來實作系統,使用數學來表示其背後的原理,但這裡還有第三個方面,在某種意義上,與前兩者正交,即可視化表示系統。對設計進行繪制的過程可以幫助我們從不同的角度對其進行概念化。或許我們可以将其想象為對解決方案的三角定位。
概念模型是描述問題元素的理論方法。概念模型能夠幫助我們澄清假設,證明某一特性,并幫助我們對系統的結構和互動建立基本了解。
uml能夠簡化複雜性,讓我們能夠清晰無誤地與團隊成員、客戶和其他涉衆溝通我們的設計,uml的出現正是為了滿足這些需要。模型是真實系統的簡化表示。這裡,我們使用了模型一詞的一般性含義,而不是在機器學習中更為精确的定義。uml幾乎可以用來對系統所有可想象的方面進行模組化。uml的核心思想是清晰地表示核心屬性和功能,去除無關和潛在歧義的元素。
1.類圖
類圖是對系統的靜态結構進行模組化。類表示具有共同特征的抽象實體。類的用途在于,其表達并強制化面向對象程式設計方法。我們可以看到,通過在代碼中分離不同的對象,每個對象都是自包含單元,則我們針對每個對象的工作會更為清晰。我們可以将對象定義為特定的一組特征和與其他對象的互動。這樣就可以将複雜程式分解為互相獨立的功能元件。我們還可以通過繼承來定義對象的子類。繼承特别有用,能夠在模型中反映真實世界中的層次(例如,程式員是人類的子類,python程式員是程式員的子類)。面向對象程式設計可以加快整體開發速度,因為它允許複用元件,并且擁有豐富的已開發元件的類庫。同時,所開發的代碼更易于維護,因為我們可以替換或改變類,并且(通常)能夠了解這些變化是如何對整體系統産生影響的。
事實上,面向對象編碼會導緻更為龐大的代碼庫,這意味着程式運作會變慢。但這最終并非是一種“非此即彼”的情形。對于大量的簡單任務,如果不會再次使用,我們可能并不會花時間去建立類。一般地,如果我們發現在輸入一些重複的代碼,或者在建立同一類型的資料結構,這時,建立一個類或許是個好主意。面向對象程式設計的最大優點是能夠在一個對象中封裝資料及操作這些資料的函數。這些軟體對象能夠以一種相當直接的方式與真實世界中的對象相對應。
最初,設計面向對象系統可能需要花些時間。然而,一旦建立起可行的類結構和類定義,則實作這些類所需的編碼任務會變得更為清晰。建立類結構是着手對系統進行模組化的一種非常有用的方法。當我們定義類時,我們關心的是一組特定屬性,是所有可能的屬性或無關的屬性的子集。它應該是真實系統的準确表示,但我們需要判斷哪些是有關的,哪些是無關的。因為真實世界的現象很複雜,而我們所擁有的關于系統的資訊往往不是完整的,是以這種判斷是困難的。我們隻能依賴于自身認知,是以領域知識(對我們所要模組化的系統的了解)至關重要,無論是對于軟體、自然,還是人類。
2.對象圖
對象圖是系統運作時的邏輯視圖。對象圖是特定時刻的快照,可以了解為類圖的執行個體。在程式運作時,許多參數和變量的值在變化,而對象圖的功能正是在于描繪這些變化。對象圖所表示的一個關鍵方面正是運作時綁定。通過使用對象間的連線,我們可以對特定運作時配置進行模組化。對應于對象類之間的關聯關系,對象之間具有連接配接。是以,對象間的連接配接強制綁定了與類相同的限制。
類圖和對象圖都是由相同的基本元素構成,其中,類圖表示類的抽象藍圖,對象圖表示在特定時刻對象的真實狀态。單一對象圖不能表示類的所有執行個體,是以在繪制對象圖時,我們必須限定于重要執行個體或那些覆寫系統基本功能的執行個體。在對象圖中,應當明确對象之間的關聯,并标示重要變量的值。
3.活動圖
活動圖将在一個過程中的獨立活動連結在一起,用于對系統的工作流程進行模組化。活動圖特别适用于對協同任務集的模組化。活動圖是uml規範中最常用的工具之一,因為其格式基于傳統流程圖,是以直覺并易于了解。活動圖主要包括活動、邊(有時稱為路徑)和決策。活動由圓角矩形表示,邊由箭頭線表示,決策由菱形表示。活動圖通常具有開始節點和結束節點。
4.狀态圖
系統改變行為依賴于其所在狀态,狀态圖用于對此進行模組化。狀态圖使用狀态和轉換來表示。狀态表示為圓角矩形,轉換表示為箭頭線。轉換具有觸發事件,觸發事件寫在箭頭線上。
大多數狀态圖會包含一個初始僞狀态和最終狀态。僞狀态是控制轉換流的狀态。僞狀态的另一個例子是選擇僞狀态,其标示了決定轉換的布爾條件。
狀态轉換系統由四種元素組成,分别是:
s = {s1, s2, …}:狀态集合
a = {a1, a2, …}:活動集合
e = {e1, e2, …}:事件集合
y: s(a u e)→2s:狀态轉換函數
第一種元素s是主體所有可能狀态的集合。活動是代理能夠改變主體所做的事情。事件可以發生于主體,并且不為代理所控制。狀态轉換函數y有兩個輸入:主體的狀态,活動與事件的并集。狀态轉換函數根據所輸入的特定活動或事件,給出所有可能的輸出狀态。
假設我們有個倉庫,存儲三種貨物,每種貨物隻能存儲一件。我們可以使用如下矩陣來表示倉庫存儲的所有可能狀态:
我們還可以為事件和活動定義類似的二進制矩陣,e表示賣出事件,a表示訂購活動。
在這個簡單的例子中,轉換函數可以作用于執行個體s(s中的一列),即s' = s + a - e,其中s'是系統的最終狀态,s是初始狀态,a和e分别是活動和事件。
我們可以用如下轉換圖來表示。