本節書摘來自華章計算機《大資料架構和算法實作之路:電商系統的技術實戰》一書中的第1章,第1.3節,作者 黃 申,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
樸素貝葉斯(naive bayes)分類是一種實用性很高的分類方法,在了解它之前,我們先來複習一下貝葉斯理論。貝葉斯決策理論是主觀貝葉斯派歸納理論的重要組成部分。貝葉斯決策就是在資訊不完整的情況下,對部分未知的狀态用主觀機率進行估計,然後用貝葉斯公式對發生機率進行修正,最後再利用期望值和修正機率做出最優決策。其基本思想具體如下。
1)已知類條件機率密度參數表達式和先驗機率。
2)利用貝葉斯公式轉換成後驗機率。
3)根據後驗機率大小進行決策分類。
最主要的貝葉斯公式如下:
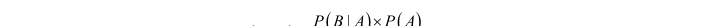
其中,在未知事件裡,b出現時a出現的後驗機率在主觀上等于已有事件中a出現時b出現的先驗機率值乘以a出現的先驗機率值,然後除以b出現的先驗機率值所得到的最終結果。這就是貝葉斯的核心:用先驗機率估計後驗機率。具體到分類模型中,上述公式可以重寫為:

對上述公式的了解如下:将c看作一個分類,将f看作樣本的特征之一,此時等号左邊p (c | f)為待分類樣本中出現特征f時該樣本屬于類别c的機率,而等号右邊p (f | c)是根據訓練資料統計得到分類c中出現特征f的機率,p (c)是分類c在訓練資料中出現的機率,最後p (f)是特征f在訓練樣本中出現的機率。
分析完貝葉斯公式之後,樸素貝葉斯就很容易了解了。樸素貝葉斯就是基于一個簡單假設所建立的一種貝葉斯方法,它假定資料對象的不同特征對其歸類時的影響是互相獨立的。此時若資料對象o中同時出現特征fi與fj,則對象o屬于類别c的機率為:
貝葉斯理論的分類器,在訓練階段需要較大的計算量,但在測試階段其計算量非常小。有一種基于執行個體的歸納學習與貝葉斯理論的分類器恰恰相反,訓練時幾乎沒有任何計算負擔,但是在面對新資料對象時卻有很大的計算開銷。基于執行個體的方法最大的優勢在于其概念簡明易懂,下面就來介紹最基礎的k最近鄰(k-near neighbor,knn)分類法。
knn分類算法其核心思想是假定所有的資料對象都對應于n維空間中的點,如果一個資料對象在特征空間中的k個最相鄰對象中的大多數屬于某一個類别,則該對象也屬于這個類别,并具有這個類别上樣本的特性。knn方法在進行類别決策時,隻與極少量的相鄰樣本有關。由于主要是靠周圍有限的鄰近樣本,是以對于類域的交叉或重疊較多的待分樣本集來說,knn方法較其他方法更為适合。圖1-3表示了水果案例中的k近鄰算法的簡化示意圖。因為水果對象的特征次元遠超過2維,是以這裡将多元空間中的點簡單地投影到二維空間,以便于圖示和了解。圖中n設定為5,待判定的新資料對象“?”最近的5個鄰居中,有3個甜橙、1個蘋果和1個西瓜,是以取最多數的甜橙作為該未知對象的分類标簽。
knn基本無須訓練,下面給出預測算法的大緻流程:
1)knn輸入訓練資料、分類标簽、特征清單tl、相似度定義、k設定等資料。
2)給定等待預測的新資料。
3)在訓練資料集合中尋找最近的k個鄰居。
4)統計k個鄰居中最多數的分類标簽,賦給給定的新資料,公式如下:
其中xnew表示待預測的新資料對象,l表示分類标簽,l表示分類标簽的集合,xi表示k個鄰居中的第i個對象。如果xi的分類标簽label (xi)和l相等,那麼δ (l, label (xi))取值為1,否則取值為0。我們可以對knn算法做一個直覺的改進,根據每個近鄰和待測點xnew的距離,将更大的權值賦給更近的鄰居。比如,可以根據每個近鄰于xnew的距離平方的倒數來确定近鄰的“選舉權”,改進公式如下:
從算法的流程可以看出,空間距離的計算對于knn算法尤為關鍵。常見的定義包括歐氏距離、餘弦相似度、曼哈頓距離、相關系數等。
對算法細節感興趣的讀者,可以閱讀《大資料架構商業之路》的6.3.1節。