本节书摘来自华章计算机《大数据架构和算法实现之路:电商系统的技术实战》一书中的第1章,第1.3节,作者 黄 申,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
朴素贝叶斯(naive bayes)分类是一种实用性很高的分类方法,在理解它之前,我们先来复习一下贝叶斯理论。贝叶斯决策理论是主观贝叶斯派归纳理论的重要组成部分。贝叶斯决策就是在信息不完整的情况下,对部分未知的状态用主观概率进行估计,然后用贝叶斯公式对发生概率进行修正,最后再利用期望值和修正概率做出最优决策。其基本思想具体如下。
1)已知类条件概率密度参数表达式和先验概率。
2)利用贝叶斯公式转换成后验概率。
3)根据后验概率大小进行决策分类。
最主要的贝叶斯公式如下:
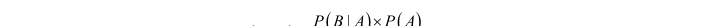
其中,在未知事件里,b出现时a出现的后验概率在主观上等于已有事件中a出现时b出现的先验概率值乘以a出现的先验概率值,然后除以b出现的先验概率值所得到的最终结果。这就是贝叶斯的核心:用先验概率估计后验概率。具体到分类模型中,上述公式可以重写为:

对上述公式的理解如下:将c看作一个分类,将f看作样本的特征之一,此时等号左边p (c | f)为待分类样本中出现特征f时该样本属于类别c的概率,而等号右边p (f | c)是根据训练数据统计得到分类c中出现特征f的概率,p (c)是分类c在训练数据中出现的概率,最后p (f)是特征f在训练样本中出现的概率。
分析完贝叶斯公式之后,朴素贝叶斯就很容易理解了。朴素贝叶斯就是基于一个简单假设所建立的一种贝叶斯方法,它假定数据对象的不同特征对其归类时的影响是相互独立的。此时若数据对象o中同时出现特征fi与fj,则对象o属于类别c的概率为:
贝叶斯理论的分类器,在训练阶段需要较大的计算量,但在测试阶段其计算量非常小。有一种基于实例的归纳学习与贝叶斯理论的分类器恰恰相反,训练时几乎没有任何计算负担,但是在面对新数据对象时却有很大的计算开销。基于实例的方法最大的优势在于其概念简明易懂,下面就来介绍最基础的k最近邻(k-near neighbor,knn)分类法。
knn分类算法其核心思想是假定所有的数据对象都对应于n维空间中的点,如果一个数据对象在特征空间中的k个最相邻对象中的大多数属于某一个类别,则该对象也属于这个类别,并具有这个类别上样本的特性。knn方法在进行类别决策时,只与极少量的相邻样本有关。由于主要是靠周围有限的邻近样本,因此对于类域的交叉或重叠较多的待分样本集来说,knn方法较其他方法更为适合。图1-3表示了水果案例中的k近邻算法的简化示意图。因为水果对象的特征维度远超过2维,所以这里将多维空间中的点简单地投影到二维空间,以便于图示和理解。图中n设置为5,待判定的新数据对象“?”最近的5个邻居中,有3个甜橙、1个苹果和1个西瓜,因此取最多数的甜橙作为该未知对象的分类标签。
knn基本无须训练,下面给出预测算法的大致流程:
1)knn输入训练数据、分类标签、特征列表tl、相似度定义、k设置等数据。
2)给定等待预测的新数据。
3)在训练数据集合中寻找最近的k个邻居。
4)统计k个邻居中最多数的分类标签,赋给给定的新数据,公式如下:
其中xnew表示待预测的新数据对象,l表示分类标签,l表示分类标签的集合,xi表示k个邻居中的第i个对象。如果xi的分类标签label (xi)和l相等,那么δ (l, label (xi))取值为1,否则取值为0。我们可以对knn算法做一个直观的改进,根据每个近邻和待测点xnew的距离,将更大的权值赋给更近的邻居。比如,可以根据每个近邻于xnew的距离平方的倒数来确定近邻的“选举权”,改进公式如下:
从算法的流程可以看出,空间距离的计算对于knn算法尤为关键。常见的定义包括欧氏距离、余弦相似度、曼哈顿距离、相关系数等。
对算法细节感兴趣的读者,可以阅读《大数据架构商业之路》的6.3.1节。