本節書摘來異步社群《hbase管理指南》一書中的第1章,第1.1節,作者: 蔣燚峰 譯者: 蘇南,更多章節内容可以通路雲栖社群“異步社群”公衆号檢視。
本章将介紹hbase叢集的安裝方法,首先将介紹基本的單機運作模式的hbase執行個體的安裝方法,然後介紹如何在amazon ec2上安裝完全分布式運作的高可靠性hbase叢集。
根據apache hbase首頁上的定義:
hbase是hadoop上的資料庫。它适合在需要對大資料進行随機且實時讀寫的情況下使用。其目标是在基于商品化硬體建構的叢集之上存儲那些非常大的表——比如那些有數百萬個字段和數十億條記錄的大表。
hbase可以在任何檔案系統上運作。比如說,無論是在ext4本地檔案系統、amazon s3(amazon simple storage service),還是hadoop分布式檔案系統(hdfs)上,都可以運作hbase。 hdfs是hadoop首選的分布式檔案系統,是以大多數完全分布式的hbase叢集都運作在hdfs檔案系統上,是以我們将首先介紹一下如何安裝hadoop。
apache zookeeper是一個開源軟體,它能夠提供一種具有高可靠性的分布式的協調服務。分布式的hbase需要運作一個zookeeper叢集。
作為一種運作在hadoop上的資料庫,hbase需要同時打開很多個檔案。 為了使hbase能夠順暢運作,我們需要修改一些linux核心參數的設定。
一個完全分布式的hbase叢集都有一個或多個主節點(hmaster)和許多從節點(regionserver),其中主節點用于協調整個叢集,從節點用于處理實際的資料存儲和要求。圖1-1顯示的是一個典型的hbase叢集結構。
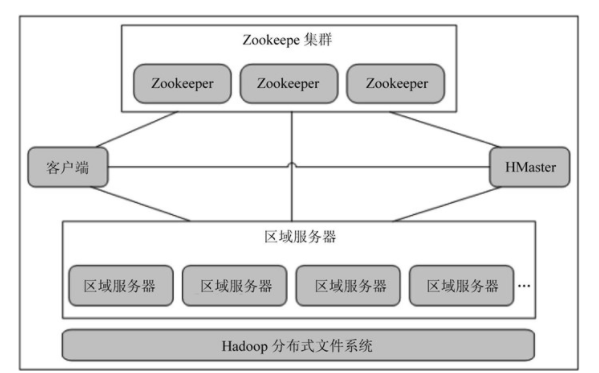
hbase可以同時運作多個主節點,它會使用zookeeper來監控這些主節點和實作這些主節點之間的故障轉移。不過,由于hbase在底層使用了hdfs來作為它的檔案系統,是以如果hdfs當機了,hbase也自然要當機。hdfs的主節點(我們稱之為namenode)是hdfs的單點故障(spof,single point of failure),是以也是hbase叢集的單一故障點。幸運的是,namenode在軟體方面非常健壯和穩定。此外,hdfs的研發團隊也正在努力開發具有真正高可靠性的namenode,hadoop的下一個主要釋出版本可能就會包含這一特性。
在1.2~1.8節中,我們将介紹如何讓hbase與它所需要使用的那些軟體一起工作,建構起一個完全分布式的hbase叢集。最後一節将介紹一個較為進階的話題——如何避免叢集的單點故障問題。
下面,我們就開始介紹如何安裝一個單機運作的hbase執行個體,之後再來示範如何在amazon ec2上安裝一個分布式的hbase叢集。
![Apache配置SSLApache配置SSL[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)