本节书摘来异步社区《hbase管理指南》一书中的第1章,第1.1节,作者: 蒋燚峰 译者: 苏南,更多章节内容可以访问云栖社区“异步社区”公众号查看。
本章将介绍hbase集群的安装方法,首先将介绍基本的单机运行模式的hbase实例的安装方法,然后介绍如何在amazon ec2上安装完全分布式运行的高可靠性hbase集群。
根据apache hbase主页上的定义:
hbase是hadoop上的数据库。它适合在需要对大数据进行随机且实时读写的情况下使用。其目标是在基于商品化硬件构建的集群之上存储那些非常大的表——比如那些有数百万个字段和数十亿条记录的大表。
hbase可以在任何文件系统上运行。比如说,无论是在ext4本地文件系统、amazon s3(amazon simple storage service),还是hadoop分布式文件系统(hdfs)上,都可以运行hbase。 hdfs是hadoop首选的分布式文件系统,因此大多数完全分布式的hbase集群都运行在hdfs文件系统上,所以我们将首先介绍一下如何安装hadoop。
apache zookeeper是一个开源软件,它能够提供一种具有高可靠性的分布式的协调服务。分布式的hbase需要运行一个zookeeper集群。
作为一种运行在hadoop上的数据库,hbase需要同时打开很多个文件。 为了使hbase能够顺畅运行,我们需要修改一些linux内核参数的设置。
一个完全分布式的hbase集群都有一个或多个主节点(hmaster)和许多从节点(regionserver),其中主节点用于协调整个集群,从节点用于处理实际的数据存储和要求。图1-1显示的是一个典型的hbase集群结构。
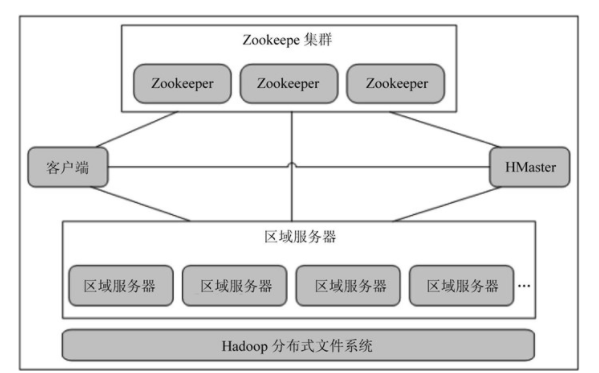
hbase可以同时运行多个主节点,它会使用zookeeper来监控这些主节点和实现这些主节点之间的故障转移。不过,由于hbase在底层使用了hdfs来作为它的文件系统,所以如果hdfs宕机了,hbase也自然要宕机。hdfs的主节点(我们称之为namenode)是hdfs的单点故障(spof,single point of failure),因此也是hbase集群的单一故障点。幸运的是,namenode在软件方面非常健壮和稳定。此外,hdfs的研发团队也正在努力开发具有真正高可靠性的namenode,hadoop的下一个主要发布版本可能就会包含这一特性。
在1.2~1.8节中,我们将介绍如何让hbase与它所需要使用的那些软件一起工作,构建起一个完全分布式的hbase集群。最后一节将介绍一个较为高级的话题——如何避免集群的单点故障问题。
下面,我们就开始介绍如何安装一个单机运行的hbase实例,之后再来演示如何在amazon ec2上安装一个分布式的hbase集群。
![Apache配置SSLApache配置SSL[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)